In this article, you will learn what prompt compression is, why it matters for agentic AI loops, and how to implement it practically using summarization and instruction distillation.
Topics we will cover include:
- Why agentic loops accumulate token costs quadratically, and how prompt compression addresses this.
- A review of the main prompt compression strategies, including instruction distillation, recursive summarization, vector database retrieval, and LLMLingua.
- A working Python example that combines recursive summarization and instruction distillation to achieve meaningful token savings.
Introduction
Agentic loops in production can be synonymous with high costs, especially when it comes to both LLM and external application usage via APIs, where billing is often closely related to token usage.
The good news: prompt compression is one of the most effective strategies you can implement to navigate the high costs of agentic loops. This article introduces and discusses how a number of prompt compression techniques can help alleviate financial issues when using agentic loops.
Prompt Compression: Motivation and Common Strategies
Numerous agentic frameworks, such as LangGraph and AutoGPT, enforce that the agent keeps a context of what it has done in previous steps. Suppose your agent needs to take 10 to 20 steps to solve a problem. To conduct step 1, it sends 500 tokens. For step 2, it must send those prior 500 tokens plus new information inherent to this step — say about 1,000 tokens in total. This may grow to about 1,500 tokens in step 3, and so on. By the time we reach the 20th step, we have been “paying” for sending largely the same information over and over.
In the example above, it may seem like the number of tokens sent per step (full prompt size) grows linearly. In fact, however, the cumulative costs of the entire agent loop become quadratic, not linear, leading to a cost explosion for long-lasting loops. This is where prompt compression techniques come to help, with strategies like selective context, summarization, and others, as we will discuss shortly.
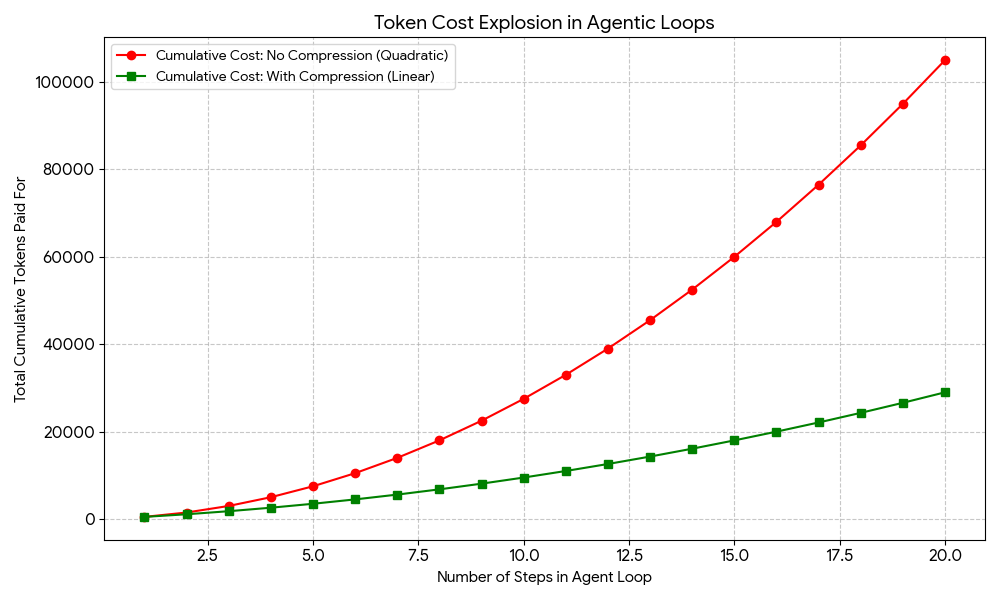
Example cost curve of agentic loops without vs. with prompt compression
The issue is not just financial: there is another hidden cost related to latency, as longer prompts take longer to process, and not all users are willing to wait 30 seconds per interaction. Compressed prompts also enable faster inference and reduce compute overhead.
To put this in perspective, a 500K token context could theoretically be reduced to a 32K token compressed window that retains all relevant information, while elements like repetitive JSON structures, stop words, and low-value conversational parts are removed. Here are some cost-effective solutions and frameworks that can be considered for implementing your own prompt compression strategy:
- Instruction distillation: this consists of creating a “compressed” version of a long system prompt that may be sent repeatedly, containing symbols or shorthand that the model will understand and interpret.
- Recursive summarization: every few steps in a loop, use the agent or a smaller, cheaper model like Llama 3 or GPT-4o-mini to summarize the previous steps’ context into a more succinct paragraph outlining the current state of the task.
- Vector database (RAG) for history retrieval: this replaces sending the full history repeatedly by storing it in a free, local vector database like FAISS or Chroma. For any given prompt, only the most relevant actions are retrieved as part of its context.
- LLMLingua: an open-source framework that is gaining popularity, focused on detecting and eliminating “non-critical” tokens in a prompt before it is sent to a larger, more expensive language model.
A Practical Example: Summarizing Agent
Below is an example of a cost-friendly prompt compression strategy that combines recursive summarization and instruction distillation using Python. The code is intended to serve as a template of what such prompt compression logic should look like when translated into a real, large-scale scenario. It shows a simplified simulation of an agentic loop, emphasizing the summarization and distillation steps:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
import tiktoken
def count_tokens(text, model=“gpt-4o”): encoding = tiktoken.encoding_for_model(model) return len(encoding.encode(text))
def compress_history(history_list): “”“ A function that simulates ‘Summarization’. In a real app, it entails sending the input to a small language model (like gpt-4o-mini) to condense it. ““”
print(“— Compressing History —“)
# In production, pass ‘combined’ to a summarization model combined = ” “.join(history_list)
# Distillation: Shorthand version of the events summary = f“Summary of {len(history_list)} steps: Tasks A & B completed. Result: Success.” return summary
# 1. Distilled System Prompt (uses shorthand instead of prose) system_prompt = “Act: ResearchBot. Task: Find X. Output: JSON only. Constraints: No fluff.”
# 2. The Agentic Loop history = [] raw_token_total = 0
for step in range(1, 6): action = f“Step {step}: Agent performed a very long-winded search for data point {step}…” history.append(action)
# Calculating what the prompt WOULD look like without compression current_full_context = system_prompt + ” “.join(history) raw_tokens = count_tokens(current_full_context)
print(f“Loop {step} | Full Context Tokens: {raw_tokens}”)
# 3. Applying Compression compressed_context = system_prompt + compress_history(history) compressed_tokens = count_tokens(compressed_context)
print(f“\nFinal Uncompressed Tokens: {raw_tokens}”) print(f“Final Compressed Tokens: {compressed_tokens}”) print(f“Savings: {((raw_tokens – compressed_tokens) / raw_tokens) * 100:.1f}%”) |
This code shows how to periodically replace the cumulative list of actions with a summary that spans a single string, helping avoid the added costs of paying for the same context tokens in every loop iteration. Try using a small, cheap model or a local one like Llama 3 to perform the summarization step.
Regarding distillation, this example illustrates what it actually does:
A standard 42-token prompt that reads “You are a helpful research assistant. Your goal is to find information about X. Please provide your output in a valid JSON format and do not include any conversational filler.” can be distilled into this 12-token prompt: “Act: ResearchBot. Task: Find X. Output: JSON. No fluff.” The model will understand it in a nearly identical fashion. Imagine a 100-step loop: this 30-token difference alone can save about 3,000 tokens just on the system prompt.
Output:
|
Loop 1 | Full Context Tokens: 37 Loop 2 | Full Context Tokens: 55 Loop 3 | Full Context Tokens: 73 Loop 4 | Full Context Tokens: 91 Loop 5 | Full Context Tokens: 109 —– Compressing History —–
Final Uncompressed Tokens: 109 Final Compressed Tokens: 36 Savings: 67.0% |
Wrapping Up
Prompt compression is not a minor optimization; it is a practical necessity for any agentic system that runs more than a handful of steps. The strategies covered here, from instruction distillation and recursive summarization to RAG-based history retrieval and LLMLingua, each address the quadratic cost problem from a different angle, and they can be combined for even greater savings. As a starting point, recursive summarization paired with a distilled system prompt requires no additional infrastructure and can already cut token usage dramatically, as the example above demonstrates.