SEO Services in Dubai UAE: How a Dubai SEO Agency Helps Businesses Grow Online
In today’s digital-first economy, visibility on search engines is no longer optional, it’s essential. Businesses operating in Dubai, one...
In today’s digital-first economy, visibility on search engines is no longer optional, it’s essential. Businesses operating in Dubai, one...

Agents built on top of today's models often break with simple changes — a new library, a workflow modification —...
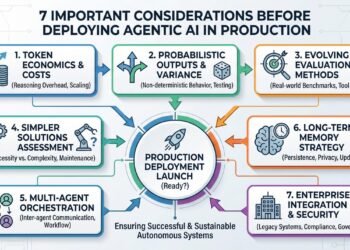
In this article, you will learn seven practical, production-grade considerations that determine whether agentic AI delivers business value or becomes...

A set of bellwether cases alleging that social media platforms harmed teens’ safety and mental health is going to trial...

February 18, 2026 | Rhiannon Day Hesselberg Erosion Protection, a leader in engineered hydraulic solutions, has selected Resonates to help elevate its voice and...

Nevada is taking action against the rapidly growing Wild West of prediction markets. The state's gambling regulators and attorney general...

LOS ANGELES — The J. Paul Getty Trust introduced a new brand identity that captures the breadth and complexity of...

However, beyond algorithms and hardware, the intelligence of robotics AI models depends on accurate, high-volume, deeply contextual, and multimodal annotated...
Key takeaways:Enterprise RPA fails at scale due to operating model gaps, not automation technology limitations.A federated RPA CoE balances delivery...

Humanizing the Customer Relationship: An Interview with Christina Garnett, CX Evangelist and “Pocket CCO” By Stephen Shaw Christina Garnett is...