
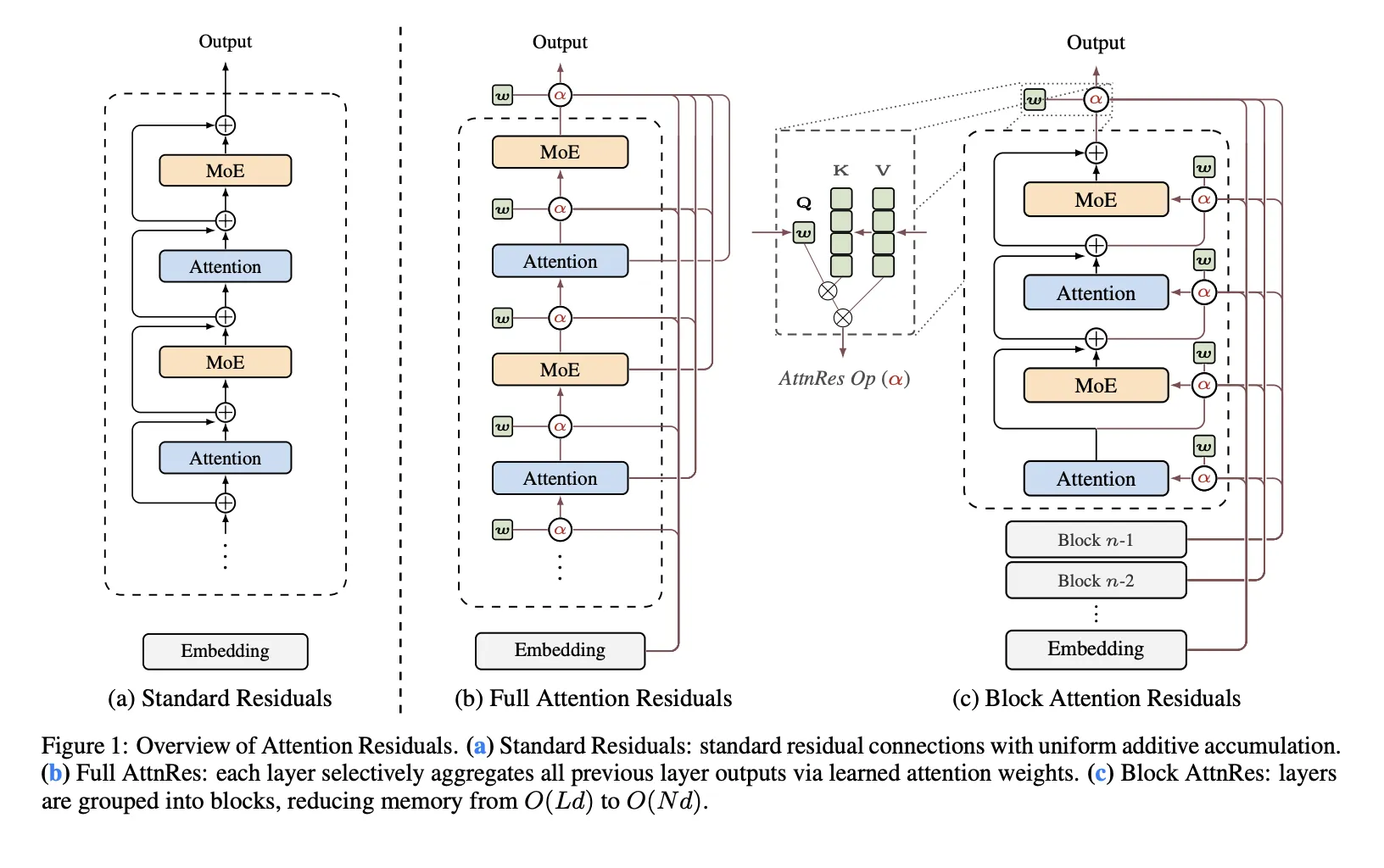
Residual connections are one of the least questioned parts of modern Transformer design. In PreNorm architectures, each layer adds its output back into a running hidden state, which keeps optimization stable and allows deep models to train. Moonshot AI researchers argue that this standard mechanism also introduces a structural problem: all prior layer outputs are accumulated with fixed unit weights, which causes hidden-state magnitude to grow with depth and progressively weakens the contribution of any single layer.
The research team proposes Attention Residuals (AttnRes) as a drop-in replacement for standard residual accumulation. Instead of forcing every layer to consume the same uniformly mixed residual stream, AttnRes lets each layer aggregate earlier representations using softmax attention over depth. The input to layer (l) is a weighted sum of the token embedding and previous layer outputs, where the weights are computed over prior depth positions rather than over sequence positions. The core idea is simple: if attention improved sequence modeling by replacing fixed recurrence over time, a similar idea can be applied to the depth dimension of a network.
Why Standard Residuals Become a Bottleneck
The research team identified three issues with standard residual accumulation. First, there is no selective access: all layers receive the same aggregated state even though attention layers and feed-forward or MoE layers may benefit from different mixtures of earlier information. Second, there is irreversible loss: once information is blended into a single residual stream, later layers cannot selectively recover specific earlier representations. Third, there is output growth: deeper layers tend to produce larger outputs to remain influential inside an ever-growing accumulated state, which can destabilize training.
This is the research team’s main framing: standard residuals behave like a compressed recurrence over layers. AttnRes replaces that fixed recurrence with explicit attention over previous layer outputs.
Full AttnRes: Attention Over All Previous Layers
In Full AttnRes, each layer computes attention weights over all preceding depth sources. The default design does not use an input-conditioned query. Instead, each layer has a learned layer-specific pseudo-query vector wl ∈ Rd, while keys and values come from the token embedding and previous layer outputs after RMSNorm. The RMSNorm step is important because it prevents large-magnitude layer outputs from dominating the depth-wise attention weights.
Full AttnRes is straightforward, but it increases cost. Per token, it requires O(L2 d) arithmetic and (O(Ld)) memory to store layer outputs. In standard training this memory largely overlaps with activations already needed for backpropagation, but under activation re-computation and pipeline parallelism the overhead becomes more significant because those earlier outputs must remain available and may need to be transmitted across stages.
Block AttnRes: A Practical Variant for Large Models
To make the method usable at scale, Moonshot AI research team introduces Block AttnRes. Instead of attending over every earlier layer output, the model partitions layers into N blocks. Within each block, outputs are accumulated into a single block representation, and attention is applied only over those block-level representations plus the token embedding. This reduces memory and communication overhead from O(Ld) to O(Nd).
The research team describes cache-based pipeline communication and a two-phase computation strategy that make Block AttnRes practical in distributed training and inference. This results in less than 4% training overhead under pipeline parallelism, while the repository reports less than 2% inference latency overhead on typical workloads.
Scaling Results
The research team evaluates five model sizes and compares three variants at each size: a PreNorm baseline, Full AttnRes, and Block AttnRes with about eight blocks. All variants within each size group share the same hyperparameters chosen under the baseline, which the research team note makes the comparison conservative. The fitted scaling laws are reported as:
Baseline: L = 1.891 x C-0.057
Block AttnRes: L = 1.870 x C-0.058
Full AttnRes: L = 1.865 x C-0.057
The practical implication is that AttnRes achieves lower validation loss across the tested compute range, and the Block AttnRes matches the loss of a baseline trained with about 1.25× more compute.
Integration into Kimi Linear
Moonshot AI also integrates AttnRes into Kimi Linear, its MoE architecture with 48B total parameters and 3B activated parameters, and pre-trains it on 1.4T tokens. According to the research paper, AttnRes mitigates PreNorm dilution by keeping output magnitudes more bounded across depth and distributing gradients more uniformly across layers. Another implementation detail is that all pseudo-query vectors are initialized to zero so the initial attention weights are uniform across source layers, effectively reducing AttnRes to equal-weight averaging at the start of training and avoiding early instability.
On downstream evaluation, the reported gains are consistent across all listed tasks. It reports improvements from 73.5 to 74.6 on MMLU, 36.9 to 44.4 on GPQA-Diamond, 76.3 to 78.0 on BBH, 53.5 to 57.1 on Math, 59.1 to 62.2 on HumanEval, 72.0 to 73.9 on MBPP, 82.0 to 82.9 on CMMLU, and 79.6 to 82.5 on C-Eval.
Key Takeaways
- Attention Residuals replaces fixed residual accumulation with softmax attention over previous layers.
- The default AttnRes design uses a learned layer-specific pseudo-query, not an input-conditioned query.
- Block AttnRes makes the method practical by reducing depth-wise memory and communication from O(Ld) to O(Nd).
- Moonshot research teamreports lower scaling loss than the PreNorm baseline, with Block AttnRes matching about 1.25× more baseline compute.
- In Kimi Linear, AttnRes improves results across reasoning, coding, and evaluation benchmarks with limited overhead.
Check out Paper and Repo. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.















