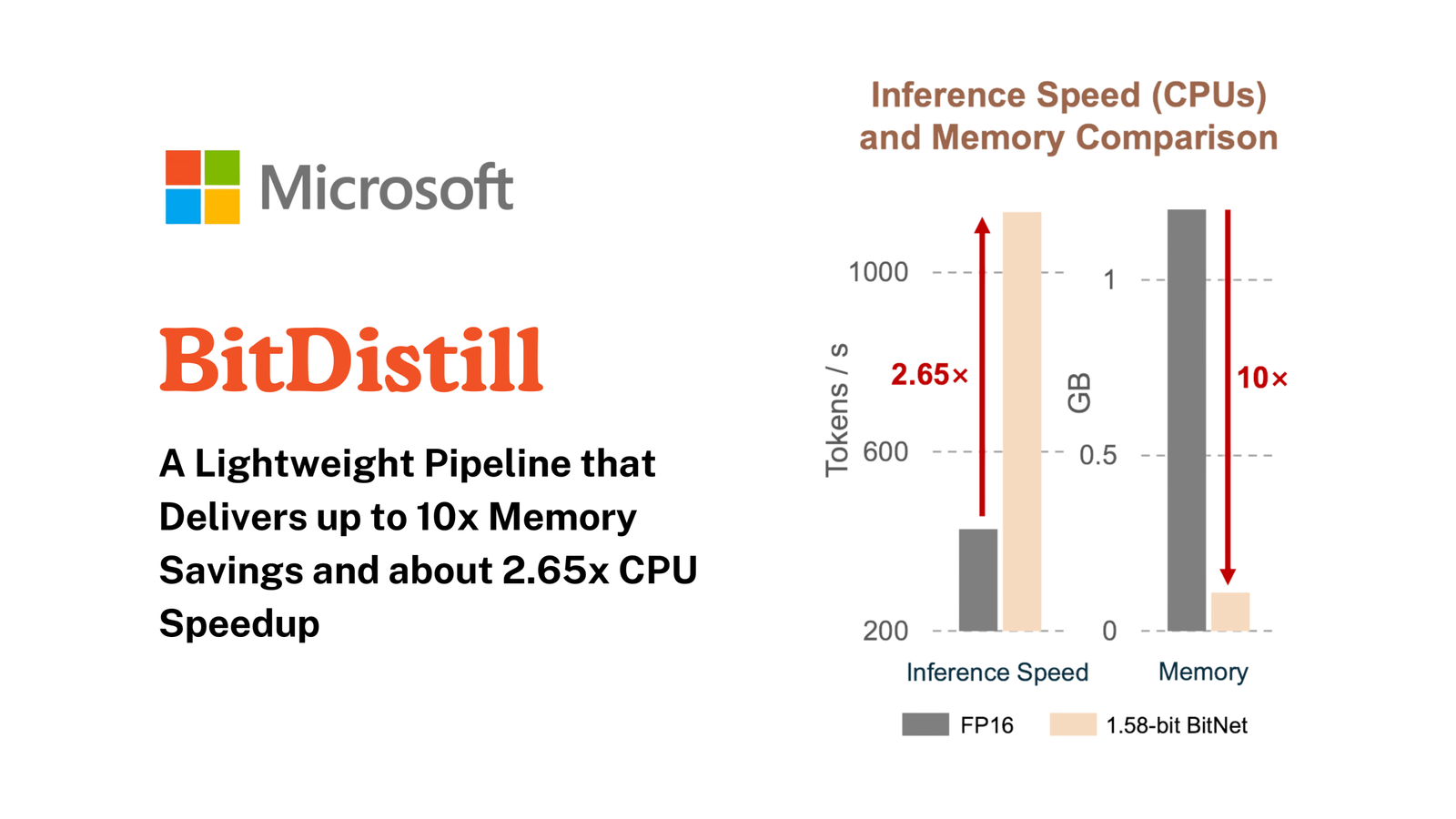
Microsoft Research proposes BitNet Distillation, a pipeline that converts existing full precision LLMs into 1.58 bit BitNet students for specific tasks, while keeping accuracy close to the FP16 teacher and improving CPU efficiency. The method combines SubLN based architectural refinement, continued pre training, and dual signal distillation from logits and multi head attention relations. Reported results show up to 10× memory savings and about 2.65× faster CPU inference, with task metrics comparable to FP16 across multiple sizes.
What BitNet Distillation changes?
The community already showed that BitNet b1.58 can match full precision quality when trained from scratch, but converting a pretrained FP16 model directly to 1.58 bit often loses accuracy, and the gap grows as model size increases. BitNet Distillation targets this conversion problem for practical downstream deployment. It is designed to preserve accuracy while delivering CPU friendly ternary weights with INT8 activations.
Stage 1: Modeling refinement with SubLN
Low bit models suffer from large activation variance. The research team inserts SubLN normalization inside each Transformer block, specifically before the output projection of the MHSA module and before the output projection of the FFN. This stabilizes hidden state scales that flow into quantized projections, which improves optimization and convergence once weights are ternary. The training loss curves in the analysis section support this design.
Stage 2: Continued pre training to adapt weight distributions
Direct task fine tuning at 1.58 bit gives the student only a small number of task tokens, which is not enough to reshape the FP16 weight distribution for ternary constraints. BitNet Distillation performs a short continued pre training on a general corpus, the research team uses 10B tokens from the FALCON corpus, to push weights toward BitNet like distributions. The visualization shows the mass concentrating near transition boundaries, which makes small gradients flip weights among [-1, 0, 1] during downstream task training. This improves learning capacity without a full pretraining run.
Stage 3: Distillation based fine tuning with two signals
The student learns from the FP16 teacher using logits distillation and multi head self attention relation distillation. The logits path uses temperature softened KL between teacher and student token distributions. The attention path follows the MiniLM and MiniLMv2 formulations, which transfer relations among Q, K, V without requiring the same number of heads, and let you choose a single layer to distill. Ablations show that combining both signals works best, and that selecting one well chosen layer preserves flexibility.
Understanding the results
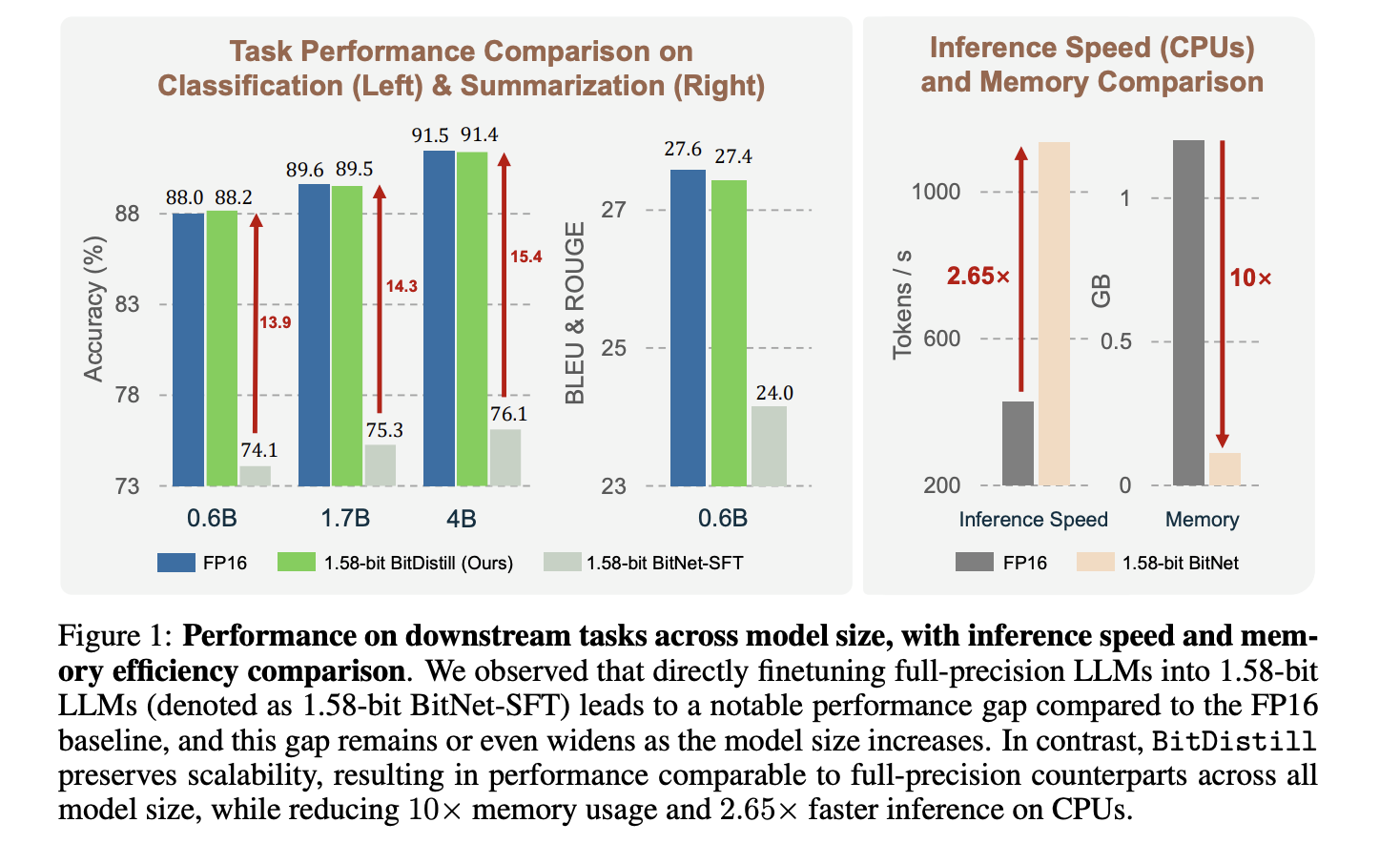
The research team evaluates classification, MNLI, QNLI, SST 2, and summarization on CNN/DailyMail dataset. It compares three settings, FP16 task fine tuning, direct 1.58 bit task fine tuning, and BitNet Distillation. Figure 1 shows that BitNet Distillation matches FP16 accuracy for Qwen3 backbones at 0.6B, 1.7B, 4B, while the direct 1.58 bit baseline lags more as model size grows. On CPU, tokens per second improve by about 2.65×, and memory drops by about 10× for the student. The research team quantizes activations to INT8 and uses the Straight Through Estimator for gradients through the quantizer.
The framework is compatible with post training quantization methods such as GPTQ and AWQ, which provide additional gains on top of the pipeline. Distilling from a stronger teacher helps more, which suggests pairing small 1.58 bit students with larger FP16 teachers when available.
Key Takeaways
- BitNet Distillation is a 3 stage pipeline, SubLN insertion, continued pre training, and dual distillation from logits and multi head attention relations.
- The research reports near FP16 accuracy with about 10× lower memory and about 2.65× faster CPU inference for 1.58 bit students.
- The method transfers attention relations using MiniLM and MiniLMv2 style objectives, which do not require matching head counts.
- Evaluations cover MNLI, QNLI, SST 2, and CNN/ DailyMail, and include Qwen3 backbones at 0.6B, 1.7B, and 4B parameters.
- Deployment targets ternary weights with INT8 activations, with optimized CPU and GPU kernels available in the official BitNet repository.
BitNet Distillation is a pragmatic step toward 1.58 bit deployment without a full retrain, the three stage design, SubLN, continual pre training, and MiniLM family attention distillation, maps cleanly to known failure modes in extreme quantization. The reported 10× memory reduction and about 2.65× CPU speedup at near FP16 accuracy indicate solid engineering value for on premise and edge targets. The reliance on attention relation distillation is well grounded in prior MiniLM work, which helps explain the stability of results. The presence of bitnet.cpp with optimized CPU and GPU kernels lowers integration risk for production teams.
Check out the Technical Paper and GitHub Repo. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.