
As LLM-powered agents move from research to production, one design tension is becoming harder to ignore: the more useful cloud-hosted memory becomes, the more private user data it exposes. Researchers from MemTensor (Shanghai), HONOR Device and Tongji University have introduced MemPrivacy, a framework that attempts to resolve this tension without sacrificing the utility that makes personalized memory worthwhile in the first place.
The Core Problem With Cloud Memory
When you interact with an AI agent, your conversation often contains sensitive details like health conditions, email addresses, financial figures, passwords, and more. In a typical edge-cloud deployment, the user’s device (the edge) handles input, while computation-heavy memory management and reasoning happen in the cloud. This architecture is efficient, but it means raw, unfiltered user data travels to and persists in cloud systems.
The risk is not theoretical. Prior studies show that multi-turn memory attacks can induce privacy violations with success rates up to 69%, and leakage attacks against memory systems can reach 75% success. Indirect prompt injection can even manipulate agents into actively eliciting private information from users. Once sensitive content enters cloud logs, vector databases, or external memory stores, it can remain accessible through subsequent storage, retrieval, and reuse stages well beyond the original interaction.
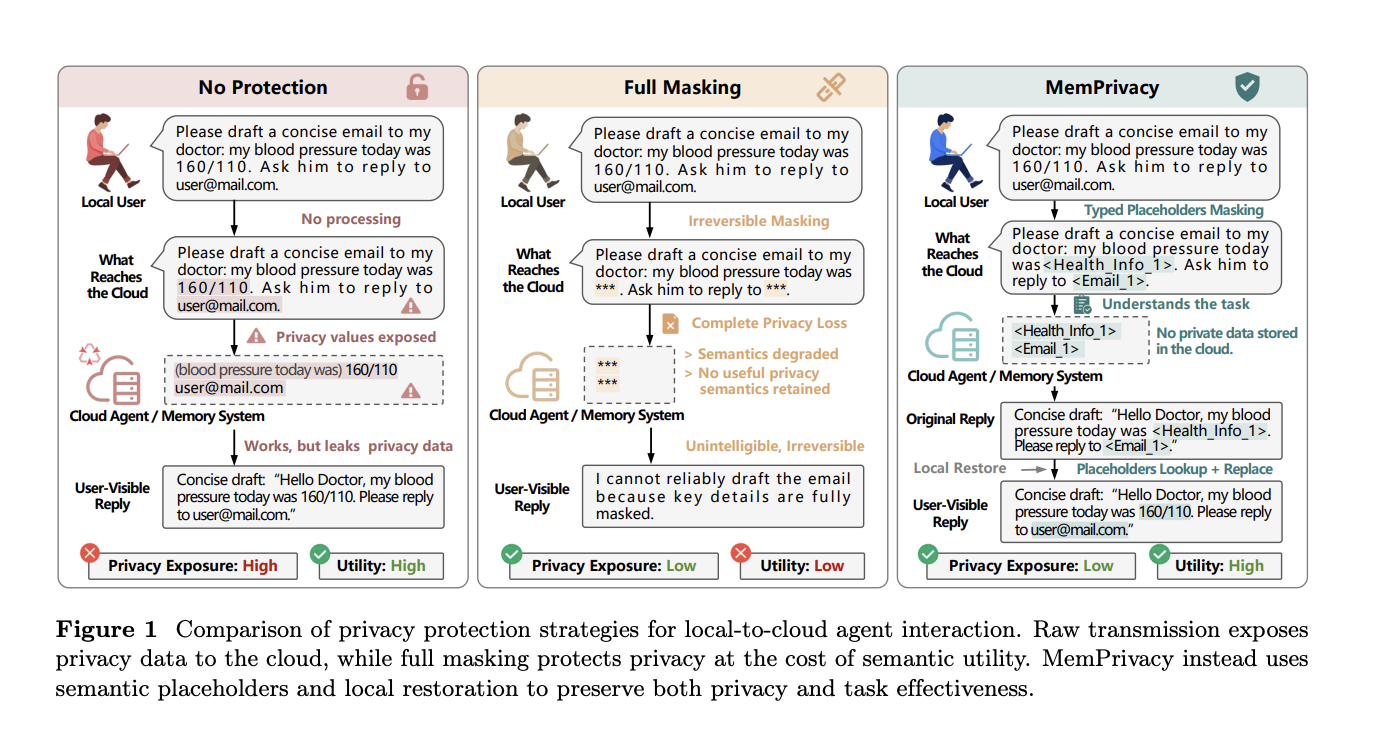
Prior works have tried to address this with masking — replacing sensitive values with tokens like ***. The problem is that masking destroys semantics. If a user asks an agent to draft a doctor’s email and their blood pressure reading and email address are both replaced with ***, the cloud model cannot complete the task meaningfully. More principled techniques such as differential privacy and cryptographic protection offer stronger guarantees but are difficult to integrate into interactive memory pipelines without degrading response quality.
What MemPrivacy Does Differently
Rather than masking private content, MemPrivacy replaces it with typed placeholders — structured tokens like <Health_Info_1> or <Email_1> — before the input leaves the local device. The cloud model receives semantically intact text and can reason and store memories normally; it just never sees the actual values. When the cloud returns a response containing placeholders, the local device looks up the originals from a secure local database and substitutes them back in. The user sees a fully coherent, personalized response.
This design is called local reversible pseudonymization, and the full pipeline operates in three stages. Stage 1 (Uplink Desensitization): A lightweight on-device model identifies privacy-sensitive spans in the input, classifies each by type and sensitivity level, and replaces them with typed placeholders. The original-to-placeholder mappings are stored locally and persist across sessions so the same value always gets the same placeholder. Stage 2 (Cloud Processing): The sanitized input is sent to the cloud agent or memory system. The typed placeholders preserve enough semantic structure for memory formation and retrieval to function correctly. Stage 3 (Downlink Restoration): The cloud response, which may contain placeholders, is restored locally via lightweight database lookup and string substitution, adding negligible latency.
A Four-Level Privacy Taxonomy
A key contribution by the research team is a four-level privacy taxonomy (PL1–PL4) that defines what gets protected and at what threshold:
- PL1 covers general preferences, habits, and stylistic choices that do not identify a person and carry low risk. These are not protected by default.
- PL2 includes identifiable PII — real names, phone numbers, email addresses, detailed addresses, account usernames, and combinations that could identify or trace a specific individual.
- PL3 covers highly sensitive PII: government document numbers, financial account details, health records, precise location and trajectory data, biometrics, raw communication content, and sensitive identity attributes such as religious beliefs or ethnicity.
- PL4 is the highest tier — credentials and secrets that are immediately exploitable: passwords, PINs, verification codes, session tokens, API keys, private keys, seed phrases, and undisclosed business materials. Exposure at this level can directly result in account takeover, financial loss, or large-scale data exfiltration.
Users can configure the masking threshold for example, protecting only PL3 and PL4, or applying full protection across PL2–PL4 — giving granular control over the privacy–utility trade-off.

MemPrivacy-Bench and Model Training
To train and evaluate their approach, the research team constructed MemPrivacy-Bench, a dataset covering 200 synthetic user profiles and over 155,000 privacy instances (125,776 training, 29,967 test) across balanced Chinese and English dialogue, spanning 7 high-level scenario categories and 23 fine-grained subcategories. The test set contains 615 question-answer pairs across six memory task types: basic memory, temporal reasoning, adversarial questioning, dynamic updating, implicit inference, and information aggregation. Annotations were first generated by a dual-model pipeline using Gemini-3.1-Pro and GPT-5.2, then verified by six human annotators, achieving a final annotation accuracy of 98.08%.
The MemPrivacy extraction models are fine-tuned from Qwen3 base models at 0.6B, 1.7B, and 4B parameter scales using supervised fine-tuning (SFT) followed by reinforcement learning with Group Relative Policy Optimization (GRPO). GRPO estimates advantages based on relative rewards across multiple sampled outputs per input, using F1 score as the reward signal, avoiding the computational overhead of a separately trained critic. Training used 160 users for the training split and 40 users for the test split.
Experimental Results
On MemPrivacy-Bench, the best-performing model — MemPrivacy-4B-RL — achieves an F1 score of 85.97%, compared to 78.41% for Gemini-3.1-Pro, the strongest general-purpose model tested. Even the smallest model, MemPrivacy-0.6B-SFT, reaches 83.09% F1, outperforming all general-purpose models evaluated. On the out-of-distribution PersonaMem-v2 benchmark, MemPrivacy-4B-RL achieves 94.48% F1, compared to 92.18% for DeepSeek-V3.2-Think, the best general model on that set.
OpenAI’s recently released Privacy-Filter, a bidirectional token-classification model for PII detection open-sourced. It achieves 35.50% F1 on MemPrivacy-Bench, a gap of over 50 percentage points behind the best MemPrivacy model, though it operates at significantly lower latency (0.34s versus roughly 2s for MemPrivacy models on MemPrivacy-Bench).
On downstream memory utility, MemPrivacy was tested across three widely used memory systems: LangMem, Mem0, and Memobase. When protecting all PL2–PL4 content, accuracy drops on MemPrivacy-Bench are contained to 0.73%–1.30% and 0.71%–1.60% on PersonaMem-v2, relative to no-protection baselines. By contrast, irreversible masking causes accuracy drops of 16.99%–41.87% on MemPrivacy-Bench, while untyped placeholder masking causes drops of 4.72%–6.67% on MemPrivacy-Bench and 2.67%–8.71% on PersonaMem-v2.
Key Takeaways
- MemPrivacy replaces sensitive user data with semantically typed placeholders (e.g.,
<Health_Info_1>) on-device before cloud transmission, so the cloud memory system never receives raw private values. - The framework introduces a four-level privacy taxonomy (PL1–PL4) ranging from general preferences to immediately exploitable credentials, with user-configurable masking thresholds.
- MemPrivacy-4B-RL achieves 85.97% F1 on MemPrivacy-Bench and 94.48% on PersonaMem-v2, outperforming GPT-5.2 (68.99%) and Gemini-3.1-Pro (78.41%) on privacy span extraction.
- Across LangMem, Mem0, and Memobase, applying MemPrivacy at the PL2–PL4 level limits memory utility loss to within 1.6%, compared to accuracy drops of up to 41.87% with irreversible masking.
- Models range from 0.6B to 4B parameters, with per-message inference under two seconds, making the framework suitable for on-device deployment without noticeable latency.
Marktechpost’s Visual Explainer
Check out the Paper and Model Weights. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
















