
How do you design an LLM agent that decides for itself what to store in long term memory, what to keep in short term context and what to discard, without hand tuned heuristics or extra controllers? Can a single policy learn to manage both memory types through the same action space as text generation?
Researchers from Alibaba Group and Wuhan University introduce Agentic Memory, or AgeMem, a framework that lets large language model agents learn how to manage both long term and short term memory as part of a single policy. Instead of relying on hand written rules or external controllers, the agent decides when to store, retrieve, summarize and forget, using memory tools that are integrated into the action space of the model.
Why current LLM agents struggle with memory
Most agent frameworks treat memory as two loosely coupled systems.
Long term memory stores user profiles, task information and previous interactions across sessions. Short term memory is the current context window, which holds the active dialogue and retrieved documents.
Existing systems design these two parts in isolation. Long term memory is handled through external stores such as vector databases with simple add and retrieve triggers. Short term memory is managed with retrieval augmented generation, sliding windows or summarization schedules.
This separation creates several issues.
- Long term and short term memory are optimized independently. Their interaction is not trained end to end.
- Heuristics decide when to write to memory and when to summarize. These rules are brittle and miss rare but important events.
- Additional controllers or expert models increase cost and system complexity.
AgeMem removes the external controller and folds memory operations into the agent policy itself.
Memory as tools in the agent action space
In AgeMem, memory operations are exposed as tools. At each step, the model can emit either normal text tokens or a tool call. The framework defines 6 tools.
For long term memory:
ADDstores a new memory item with content and metadata.UPDATEmodifies an existing memory entry.DELETEremoves obsolete or low value items.
For short term memory:
RETRIEVEperforms semantic search over long term memory and injects the retrieved items into the current context.SUMMARYcompresses spans of the dialogue into shorter summaries.FILTERremoves context segments that are not useful for future reasoning.
The interaction protocol has a structured format. Each step starts with a <think> block where the model reasons privately. Then the model either emits a <tool_call> block with a JSON list of tool invocations, or an <answer> block with the user facing response. Memory actions are therefore first class decisions, not side effects.
Three stage reinforcement learning for unified memory
AgeMem is trained with reinforcement learning in a way that couples long term and short term memory behavior.
The state at time t includes the current conversational context, the long term memory store and the task specification. The policy chooses either a token or a tool call as the action. The training trajectory for each sample is divided into 3 stages:
- Stage 1, long term memory construction: The agent interacts in a casual setting and observes information that will later become relevant. It uses
ADD,UPDATEandDELETEto build and maintain long term memory. The short term context grows naturally during this stage. - Stage 2, short term memory control under distractors: The short term context is reset. Long term memory persists. The agent now receives distractor content that is related but not necessary. It must manage short term memory using
SUMMARYandFILTERto keep useful content and remove noise. - Stage 3, integrated reasoning: The final query arrives. The agent retrieves from long term memory using
RETRIEVE, controls the short term context, and produces the answer.
The crucial detail is that long term memory persists across all stages while short term memory is cleared between Stage 1 and Stage 2. This design forces the model to rely on retrieval rather than on residual context and exposes realistic long horizon dependencies.
Reward design and step wise GRPO
AgeMem uses a step wise variant of Group Relative Policy Optimization (GRPO). For each task, the system samples multiple trajectories that form a group. A terminal reward is computed for each trajectory, then normalized within the group to obtain an advantage signal. This advantage is broadcast to all steps in the trajectory so that intermediate tool choices are trained using the final outcome.
The total reward has three main components:
- A task reward that scores answer quality between 0 and 1 using an LLM judge.
- A context reward that measures the quality of short term memory operations, including compression, early summarization and preservation of query relevant content.
- A memory reward that measures long term memory quality, including the fraction of high quality stored items, the usefulness of maintenance operations and the relevance of retrieved items to the query.
Uniform weights are used for these three components so that each contributes equally to the learning signal. A penalty term is added when the agent exceeds the maximum allowed dialogue length or when the context overflows the limit.
Experimental setup and main results
The research team fine-tune AgeMem on the HotpotQA training split and evaluate on 5 benchmarks:
- ALFWorld for text based embodied tasks.
- SciWorld for science themed environments.
- BabyAI for instruction following.
- PDDL tasks for planning.
- HotpotQA for multi hop question answering.
Metrics include success rate for ALFWorld, SciWorld and BabyAI, progress rate for PDDL tasks, and an LLM judge score for HotpotQA. They also define a Memory Quality metric using an LLM evaluator that compares stored memories to the supporting facts of HotpotQA.
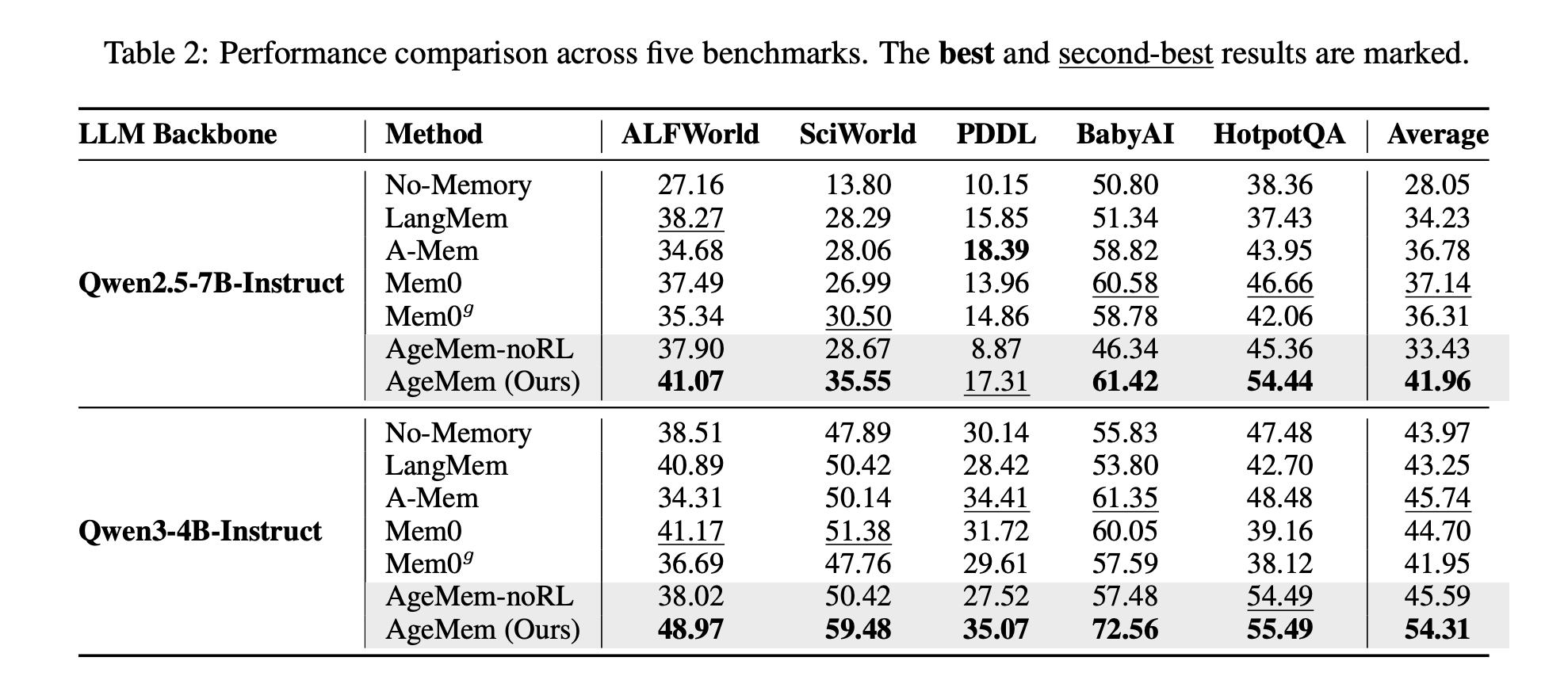
Baselines include LangMem, A Mem, Mem0, Mem0g and a no memory agent. Backbones are Qwen2.5-7B-Instruct and Qwen3-4B-Instruct.
On Qwen2.5-7B-Instruct, AgeMem reaches an average score of 41.96 across the 5 benchmarks, while the best baseline, Mem0, reaches 37.14. On Qwen3-4B-Instruct, AgeMem reaches 54.31, compared to 45.74 for the best baseline, A Mem.
Memory quality also improves. On HotpotQA, AgeMem reaches 0.533 with Qwen2.5-7B and 0.605 with Qwen3-4B, which is higher than all baselines.
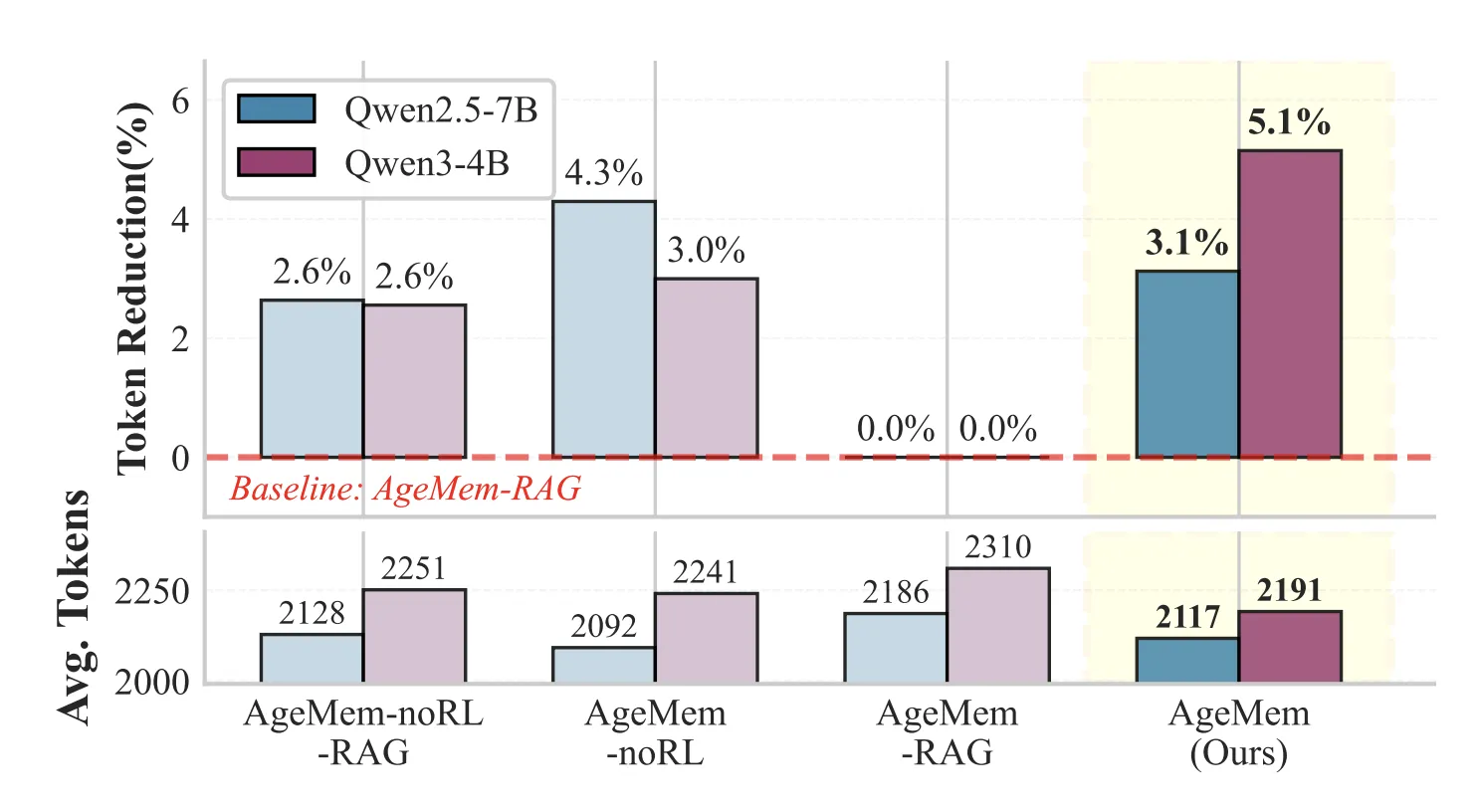
Short term memory tools reduce prompt length while preserving performance. On HotpotQA, configurations with STM tools use about 3 to 5 percent fewer tokens per prompt than variants that replace STM tools with a retrieval pipeline.
Ablation studies confirm that each component matters. Adding only long term memory tools on top of a no memory baseline already yields clear gains. Adding reinforcement learning on these tools improves scores further. The full system with both long term and short term tools plus RL gives up to 21.7 percentage points improvement over the no memory baseline on SciWorld.
Implications for LLM agent design
AgeMem suggests a design pattern for future agentic systems. Memory should be handled as part of the learned policy, not as two external subsystems. By turning storage, retrieval, summarization and filtering into explicit tools and training them jointly with language generation, the agent learns when to remember, when to forget and how to manage context efficiently across long horizons.
Key Takeaways
- AgeMem turns memory operations into explicit tools, so the same policy that generates text also decides when to
ADD,UPDATE,DELETE,RETRIEVE,SUMMARYandFILTERmemory. - Long term and short term memory are trained jointly through a three stage RL setup where long term memory persists across stages and short term context is reset to enforce retrieval based reasoning.
- The reward function combines task accuracy, context management quality and long term memory quality with uniform weights, plus penalties for context overflow and excessive dialogue length.
- Across ALFWorld, SciWorld, BabyAI, PDDL tasks and HotpotQA, AgeMem on Qwen2.5-7B and Qwen3-4B consistently outperforms memory baselines such as LangMem, A Mem and Mem0 on average scores and memory quality metrics.
- Short term memory tools reduce prompt length by about 3 to 5 percent compared to RAG style baselines while keeping or improving performance, showing that learned summarization and filtering can replace handcrafted context handling rules.
Check out the FULL PAPER here. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Check out our latest release of ai2025.dev, a 2025-focused analytics platform that turns model launches, benchmarks, and ecosystem activity into a structured dataset you can filter, compare, and export.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.














