
In this article, you will learn what guardrails are for non-deterministic AI agents and how simple statistical methods can be used to implement them effectively.
Topics we will cover include:
- What guardrails are and why they matter when working with non-deterministic agents and large language models.
- How semantic drift detection, based on cosine distance z-scores, can flag off-topic or unsafe agent responses.
- How confidence thresholding, based on Shannon entropy, can detect when a model is uncertain or likely hallucinating.
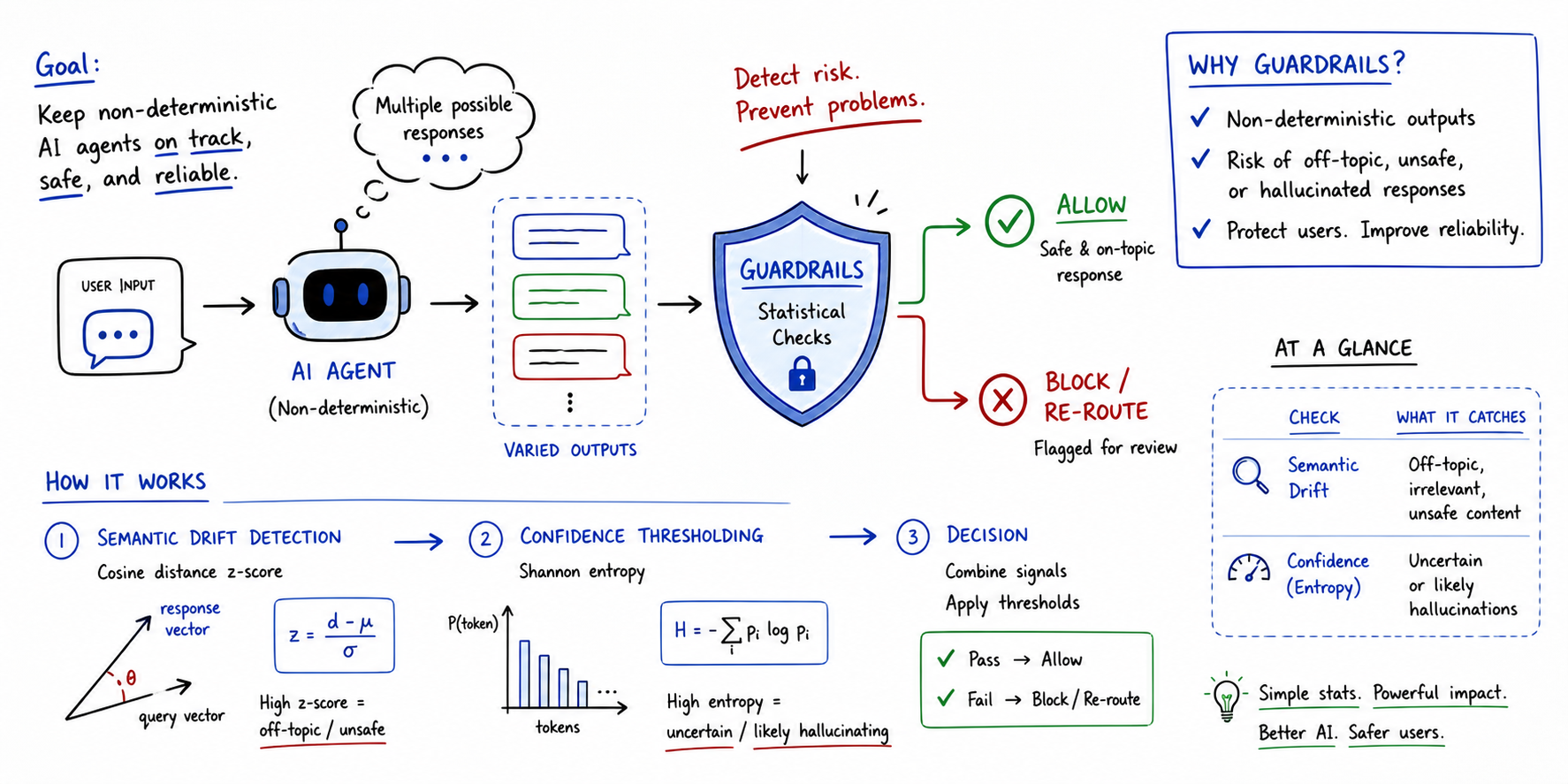
Implementing Statistical Guardrails for Non-Deterministic Agents (click to enlarge)
Introduction
Non-deterministic agents are those where the same input can lead to distinct outputs across multiple runs. In other words, their behavior is probabilistic, making standard evaluation methods like unit testing impossible to run. Statistical, threshold-based approaches beyond exact matching are therefore needed not only to assess these agents’ performance, but most importantly, to ensure safe AI guardrails sit between non-deterministic agents and end users.
This article takes a look at guardrails for non-deterministic agent evaluation, helping understand their significance and illustrating how simple statistical mechanisms can lay the foundations for robust evaluation guardrails.
Understanding Guardrails in Agent Evaluation
Guardrails are programmatic constraints that act as an automated safety layer sitting between a non-deterministic agent and the end user. Nowadays, the symbiotic use of AI agents alongside large language models makes them particularly important, as large language models can yield hallucinations or unpredictable outputs.
In a broad sense, a guardrail assesses the agent’s response in real-time. The assessment involves checking for aspects like topic relevance, factual alignment, and potential safety violations — all before the output is displayed to the end user.
Developers can implement them and make agents more reliable, even with probabilistic behavior — the key is to rely on quantitative statistical thresholds. Let’s see how through a couple of examples.
Statistical Guardrails for Non-Deterministic Agents
Statistical guardrails take a significant step beyond abstract safety concerns. They convert those concerns into automated checks driven by rigor. Measures widely used in statistics can be utilized, for instance, to identify situations when the agent becomes erratic or “confused”.
Let’s outline two simple yet effective approaches: semantic drift based on cosine distance and confidence thresholding based on log-probability entropy.
Semantic Drift
This guardrail is designed to measure what the agent says, compared to a “safe” baseline.
It consists of embedding the output text into a vector space and computing the cosine distance to the known baseline data. A z-score of the cosine distance is calculated: if its value is high, this means the response is a statistical outlier, consequently flagging the response.
This strategy is best applied when off-topic drifts should be avoided, along with hallucinations or toxic shifts in agent persona and behavior.
Confidence Thresholding
This guardrail measures certainty — more specifically, how certain the agent is about the words chosen to build its response.
To measure it, the log-probabilities of generated tokens are extracted to calculate the Shannon entropy of the underlying distribution:
$$H = -\sum p(x) \log p(x)$$
When the entropy H is high, the agent’s model has been guessing between many low-probability tokens to choose the next one to generate: a clear sign of factual failure and low confidence in response generation.
This strategy is best used for detecting when the model might be inventing facts or struggling with complex logic workflows.
Statistical Guardrails Implementation
Below, we provide a concise example of the implementation of these two guardrails in Python, assuming a readily available agent output text.
Start by importing the necessary modules and classes:
|
import numpy as np from sentence_transformers import SentenceTransformer from scipy.spatial.distance import cosine |
The pre-trained sentence transformer we will load is used to construct embeddings for the safe baseline example responses and the agent’s actual response to evaluate.
|
# Initialize Model model = SentenceTransformer(‘all-MiniLM-L6-v2’) safe_examples = [“The system is operational.”, “Access is granted to authorized users.”] baseline_embs = model.encode(safe_examples) |
We define a check_guardrails() function that evaluates the agent’s output using the two methods described above: a semantic guardrail based on cosine distance z-scores, and a confidence guardrail based on entropy.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
def check_guardrails(output, token_probs): # 1. Semantic Guardrail (Cosine Distance) output_emb = model.encode([output])[0] distances = np.array([cosine(output_emb, b) for b in baseline_embs]) mean_dist = np.mean(distances) std_dist = np.std(distances) + 1e–9 # avoid division by zero z_score = (np.min(distances) – mean_dist) / std_dist
# 2. Confidence Guardrail (Entropy) # token_probs is a list of probabilities for each generated token entropy = –np.sum(token_probs * np.log(token_probs + 1e–9))
# Decision Logic is_off_topic = z_score > 2.0 # Statistical outlier is_confused = entropy > 3.5 # High uncertainty
if is_off_topic or is_confused: return “REJECT”, {“z_score”: z_score, “entropy”: entropy} return “PASS”, {“z_score”: z_score, “entropy”: entropy}
# Example usage with mock token probabilities print(check_guardrails(“The moon is made of blue cheese.”, np.array([0.1, 0.2, 0.1, 0.5]))) |
To see how the guardrails behave in different scenarios, try replacing the response string in the last line with anything of your choice. You can also tweak the token probabilities array to increase or decrease uncertainty. In the example above, the semantic guardrail triggers &emdash; the z-score well exceeds the 2.0 threshold &emdash; so the response is rejected:
|
(‘REJECT’, {‘z_score’: np.float64(3.847), ‘entropy’: np.float64(1.1289781873656017)}) |
Summary
Simple, traditional statistical methods and measures can become effective pillars for implementing safety guardrails in AI applications involving agents and large language models. They can analyze different desirable properties of responses and support decision-making, making these systems more trustworthy.
















