Transformer models consist of stacked transformer layers, each containing an attention sublayer and a feed-forward sublayer. These sublayers are not directly connected; instead, skip connections combine the input with the processed output in each sublayer. In this post, you will explore skip connections in transformer models. Specifically:
- Why skip connections are essential for training deep transformer models
- How residual connections enable gradient flow and prevent vanishing gradients
- The differences between pre-norm and post-norm transformer architectures
Let’s get started.

Skip Connections in Transformer Models
Photo by David Emrich. Some rights reserved.
Overview
This post is divided into three parts; they are:
- Why Skip Connections are Needed in Transformers
- Implementation of Skip Connections in Transformer Models
- Pre-norm vs Post-norm Transformer Architectures
Why Skip Connections are Needed in Transformers
Transformer models, like other deep learning models, stack many layers on top of each other. As the number of layers increases, training becomes increasingly difficult due to the vanishing gradient problem. When gradients flow backward through many layers, they can become exponentially small, making it nearly impossible for early layers to learn effectively.
The key to successful deep learning models is maintaining good gradient flow. Skip connections, also known as residual connections, create direct paths for information and gradients to flow through the network. They allow the model to learn residual functions, the difference between the desired output and the input, rather than learning complete transformations from scratch. This concept was first introduced in the ResNet paper. Mathematically, this means:
$$y = F(x) + x$$
where the function $F(x)$ is learned. Notice that setting $F(x) = 0$ makes the output $y$ equal to the input $x$. This is called identity mapping. Starting from this baseline, the model can gradually shape $y$ away from $x$ rather than searching for a completely new function $F(x)$. This is the motivation for using skip connections.
During backpropagation, the gradient with respect to the input becomes:
$$\frac{\partial L}{\partial x} = \frac{\partial L}{\partial y} \cdot \frac{\partial y}{\partial x} = \frac{\partial L}{\partial y} \cdot \left(\frac{\partial F(x)}{\partial x} + 1\right)$$
The “+1” term ensures the gradient doesn’t diminish even when $\partial F/\partial x$ is small. This is why skip connections mitigate the vanishing gradient problem.
In transformer models, skip connections are applied around each sublayer (attention and feed-forward networks). This design provides a path for gradients to flow backward, enabling transformer models to converge faster: a crucial advantage given their typically deep architecture and long training times.
The figure below illustrates typical skip connection usage:
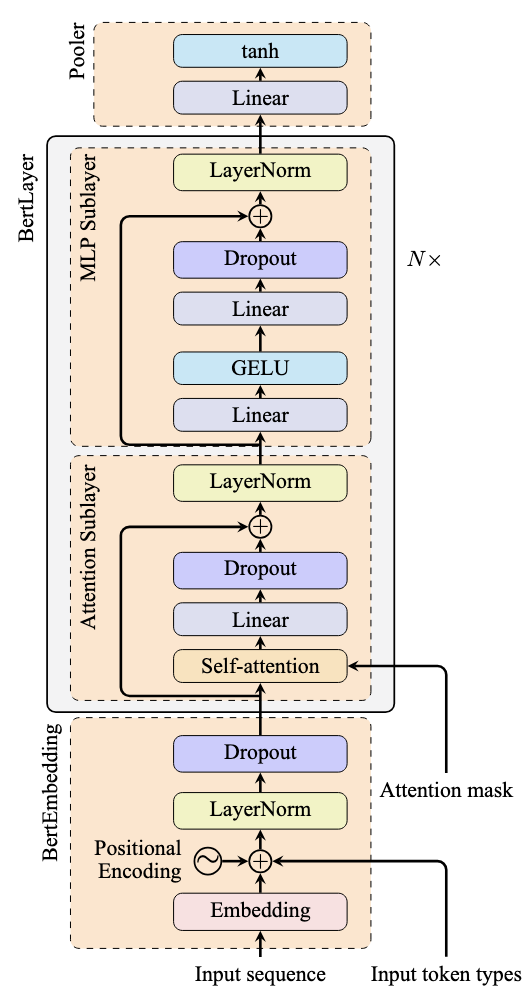
Note how the arrows represent skip connections that bypass the attention and feed-forward sublayers. These connections add the input directly to the output of each sublayer, creating a residual learning framework.
Implementation of Skip Connections in Transformer Models
Here’s how residual connections are typically implemented in transformer models:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import torch.nn as nn
class BertLayer(nn.Module): def __init__(self, dim, intermediate_dim, num_heads): super().__init__() self.attention = nn.MultiheadAttention(dim, num_heads) self.linear1 = nn.Linear(dim, intermediate_dim) self.linear2 = nn.Linear(intermediate_dim, dim) self.act = nn.GELU() self.norm1 = nn.LayerNorm(dim) self.norm2 = nn.LayerNorm(dim)
def forward(self, x): # Skip connection around attention sub-layer attn_output = self.attention(x, x, x)[0] # extract first element of the tuple x = x + attn_output # Residual connection x = self.norm1(x) # Layer normalization
# Skip connection around MLP sub-layer mlp_output = self.linear1(x) mlp_output = self.act(mlp_output) mlp_output = self.linear2(mlp_output) x = x + mlp_output # Residual connection x = self.norm2(x) # Layer normalization return x |
This PyTorch implementation represents one layer of the BERT model, as illustrated in the previous figure. The nn.MultiheadAttention module replaces the self-attention and linear layers in the attention sublayer.
In the forward() method, the attention module output is saved as attn_output and added to the input x before applying layer normalization. This addition implements the skip connection. Similarly, in the MLP sublayer, the input x (the input to the MLP sublayer, not the entire transformer layer) is added to mlp_output.
Pre-norm vs Post-norm Transformer Architectures
The placement of layer normalization relative to skip connections significantly impacts training stability and model performance. Two main architectures have emerged: pre-norm and post-norm transformers.
The original “Attention Is All You Need” paper used post-norm architecture, where layer normalization is applied after the residual connection. The code above implements the post-norm architecture, applying normalization after the skip connection addition.
Most modern transformer models use pre-norm architecture instead, where normalization is applied before the sublayer:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
class PreNormTransformerLayer(nn.Module): def __init__(self, dim, intermediate_dim, num_heads): super().__init__() self.attention = nn.MultiheadAttention(dim, num_heads) self.linear1 = nn.Linear(dim, intermediate_dim) self.linear2 = nn.Linear(intermediate_dim, dim) self.act = nn.GELU() self.norm1 = nn.LayerNorm(dim) self.norm2 = nn.LayerNorm(dim)
def forward(self, x): # Pre-norm: normalize before sub-layer normalized_x = self.norm1(x) attn_output = self.attention(normalized_x, normalized_x, normalized_x)[0] x = x + attn_output # Residual connection
normalized_x = self.norm2(x) mlp_output = self.linear1(normalized_x) mlp_output = self.act(mlp_output) mlp_output = self.linear2(mlp_output) x = x + mlp_output # Residual connection return x |
In this pre-norm implementation, normalization is applied to the input x before the attention and MLP operations, with skip connections applied afterward.
The choice between pre-norm and post-norm architectures affects training and performance:
- Training Stability: Post-norm can be unstable during training, especially for very deep models, as gradient variance can grow exponentially with depth. Pre-norm models are more robust to train.
- Convergence Speed: Pre-norm models generally converge faster and are less sensitive to learning rate choices. Post-norm models require carefully designed learning rate scheduling and warm-up periods.
- Model Performance: Despite training challenges, post-norm models typically perform better when successfully trained.
Most modern transformer models use pre-norm architecture because they are too deep and large. In these cases, faster convergence is more valuable than slightly better performance.
Further Readings
Below are some resources that you may find useful:
Summary
In this post, you learned about skip connections in transformer models. Specifically, you learned about:
- Why skip connections are essential for training deep transformer models
- How residual connections enable gradient flow and prevent vanishing gradients
- The differences between pre-norm and post-norm transformer architectures
- When to use each architectural variant based on your specific requirements
Skip connections are a fundamental component that enables the training of very deep transformer models. The choice between pre-norm and post-norm architectures can significantly impact training stability and model performance, with pre-norm being the preferred choice for most modern applications.
Learn Transformers and Attention!

Teach your deep learning model to read a sentence
…using transformer models with attention
Discover how in my new Ebook:
Building Transformer Models with Attention
It provides self-study tutorials with working code to guide you into building a fully-working transformer models that can
translate sentences from one language to another…