

Researchers at Meta’s FAIR lab have released NeuralSet, a Python framework designed to eliminate one of the most persistent bottlenecks in Neuro-AI research: the painful, fragmented process of getting brain data into a deep learning pipeline.
The Problem: Neuroscience Data Is Stuck in the Pre-Deep-Learning Era
Neuroscience already has excellent, battle-tested software. Tools like MNE-Python, EEGLAB, FieldTrip, Brainstorm, Nilearn, and fMRIPrep are the gold standard for signal processing across electrophysiology and neuroimaging. The trouble is that these tools were designed for a pre-deep-learning world: they rely on eager loading, assuming entire datasets fit into RAM, and they lack native abstractions to temporally align neural time series with high-dimensional embeddings from modern AI frameworks like HuggingFace Transformers.
The result? Researchers spend enormous effort building ad-hoc pipelines that require manual data wrangling, manual caching, and complex backend configurations — just to get brain signals paired with, say, GPT-2 text embeddings for a single experiment. As public datasets on platforms like OpenNeuro now reach the terabyte scale, and experimental protocols increasingly incorporate continuous speech and video stimuli, this infrastructure gap is no longer just inconvenient — it is a scientific bottleneck.

What NeuralSet Actually Does
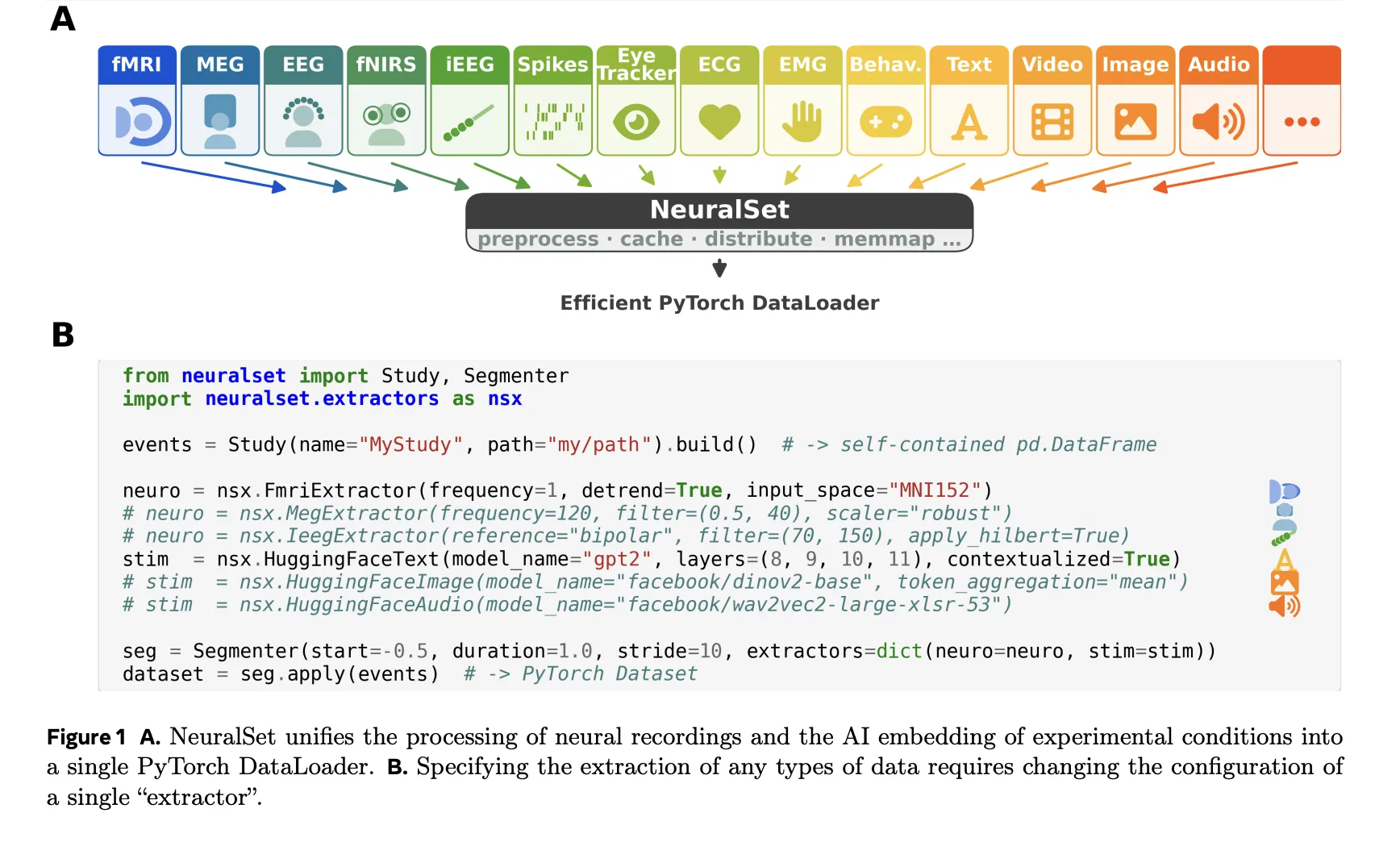
NeuralSet’s core design principle is structure–data decoupling. Instead of loading raw signals upfront, NeuralSet represents the logical structure of any experiment as lightweight, event-driven metadata — completely separate from the memory- and compute-intensive extraction of actual signals. The framework is organized around five core abstractions: Events, Extractors, Segments, Batch Data, and a Backend layer.
In practice, everything in an experiment — an fMRI run, a word spoken during a task, a video stimulus — is modeled as an Event: a lightweight Python dictionary defined by a type, a start time, a duration, and a timeline (a unique identifier for a continuous recording session). A Study object assembles all events in an entire dataset into a single pandas DataFrame. Importantly, NeuralSet supports BIDS-compliant datasets, though it is not restricted to them. Because the DataFrame contains only lightweight metadata — not the raw signals themselves — engineers can filter, explore, and recombine massive datasets using standard pandas operations without loading a single byte of raw data into memory.
Composable EventsTransform operations can then be chained to enrich or filter events — for example, annotating words with their sentence context, assigning cross-validation splits, or chunking long audio and video events into shorter segments. Multiple Study and Transform steps can also be composed together using a Chain, which creates a single reproducible, cacheable pipeline object.
When it’s actually time to work with data, NeuralSet uses Extractors to bridge the gap between the metadata layer and numerical arrays required by machine learning models. For neural recordings, NeuralSet wraps the preprocessing stacks of domain-specific libraries directly: an FmriExtractor delegates to Nilearn for signal cleaning, spatial smoothing, and surface or atlas-based projection, while a MegExtractor or EegExtractor delegates to MNE-Python for filtering, re-referencing, and resampling. The same unified interface covers iEEG, fNIRS, EMG, and spike recordings — switching modalities requires only changing a configuration parameter, not rewriting a pipeline.
For experimental stimuli, NeuralSet provides native integration with the HuggingFace ecosystem. A single HuggingFaceImage extractor can embed stimulus frames through DINOv2 or CLIP; analogous extractors exist for audio (Wav2Vec, Whisper), text (GPT-2, LLaMA), and video (VideoMAE). Critically, NeuralSet can expand a static embedding — say, a single vector per image — into a time series at an arbitrary frequency, so that stimulus representations are always temporally aligned with neural recordings.
Extractors follow a three-phase execution model: configure (parameter validation at construction time), prepare (pre-compute and cache heavy outputs for all events), and extract (lazy retrieval from cache during model training). This means expensive computations — like running a large language model over every word in a corpus — are performed once and reused across experiments. The output of an Extractor for a single segment is Batch Data: a dictionary of tensors keyed by extractor name, along with the corresponding segments.
Segmenter, DataLoader, and Cluster-Ready Infrastructure
A Segmenter slices the events DataFrame into Segments — contiguous temporal windows representing single training examples — either on a sliding window grid or anchored to specific trigger events such as image or word onsets. The resulting SegmentDataset is a standard PyTorch Dataset, directly compatible with DataLoader, PyTorch Lightning, or any PyTorch-based framework.
NeuralSet is built on the exca package, which handles deterministic, hash-based caching, full computational provenance, and hardware-agnostic execution. Changing a single preprocessing parameter invalidates only the affected downstream cache, leaving independent branches untouched. Full provenance is maintained, meaning any processed tensor can be traced back to the exact version of the raw data and the specific preprocessing chain used to generate it. Researchers can prototype on a single subject on their laptop, then dispatch 100 subjects to a SLURM-based HPC cluster by changing a single configuration flag — no infrastructure-specific code required.
NeuralSet uses Pydantic to enforce strict schema validation at initialization time across every configurable object — Events, Studies, Extractors, Segmenters, and Transforms are all Pydantic BaseModel subclasses. This means a misconfigured parameter (for example, a negative filter frequency or an invalid BIDS directory path) raises a clear error immediately, before any job is submitted, rather than failing hours into a processing run.
How It Stacks Up Against Existing Tools
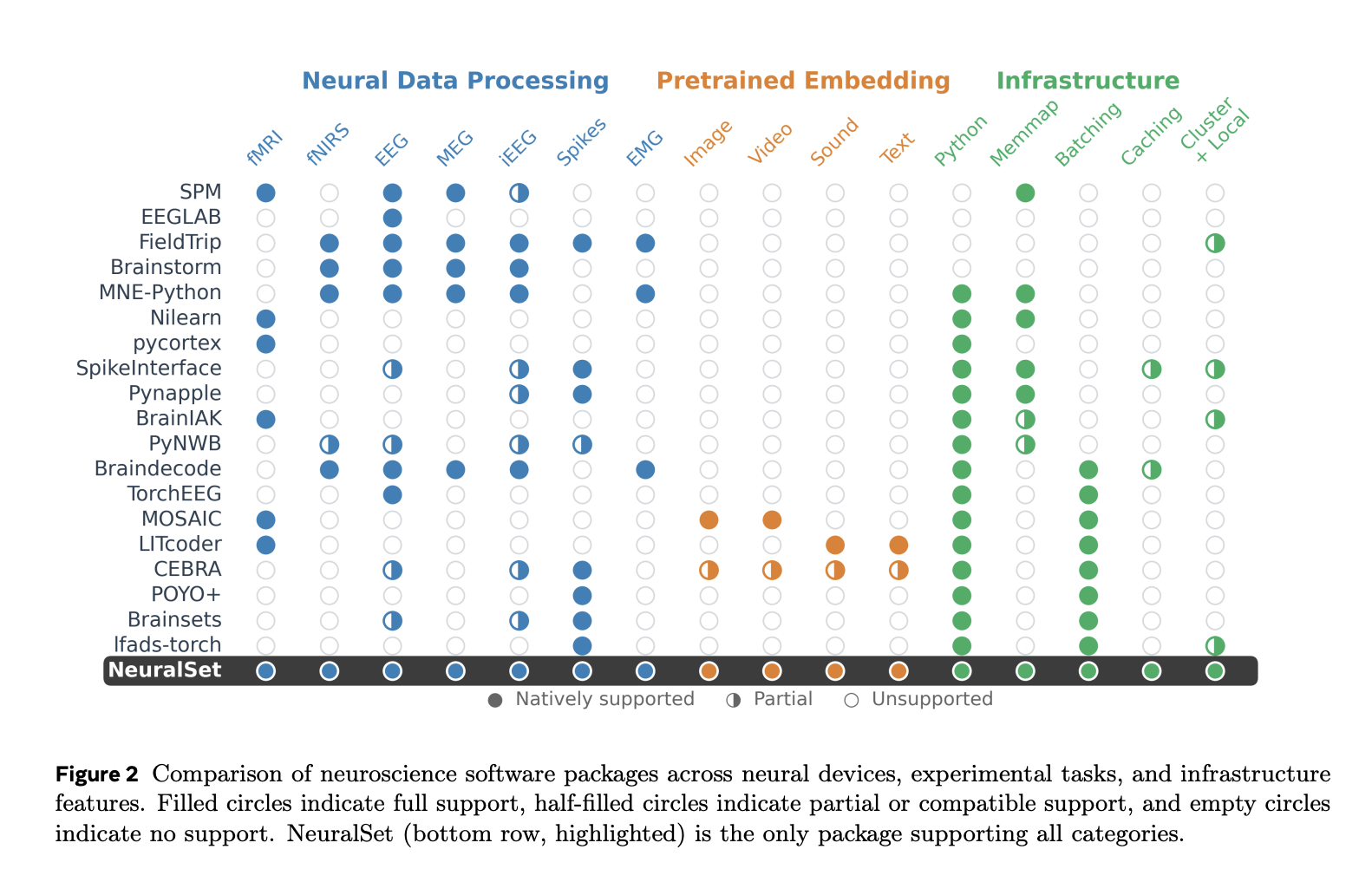
In the research paper, the research team presents a detailed comparison of NeuralSet against 18 existing neuroscience software packages across neural devices (fMRI, EEG, MEG, iEEG, spikes, and more), experimental task types (image, video, sound, text), and infrastructure features (Python support, memmap, batching, caching, cluster execution). NeuralSet is the only package in the comparison that achieves full support across all categories.
Key Takeaways
- NeuralSet unifies brain data and AI in one pipeline. Researchers at Meta FAIR built NeuralSet to bridge the gap between diverse neural recordings (fMRI, M/EEG, spikes) and modern deep learning frameworks, delivering a single PyTorch-ready DataLoader for both.
- Structure–data decoupling eliminates memory bottlenecks. NeuralSet separates lightweight event metadata from heavy signal extraction, so AI devs and researchers can filter and explore terabyte-scale datasets without loading a single byte of raw data into RAM.
- Switching recording modalities requires changing only one config parameter. A unified Extractor interface wraps MNE-Python, Nilearn, and HuggingFace models — covering fMRI, EEG, MEG, iEEG, fNIRS, EMG, spikes, text, audio, and video — with no pipeline rewriting needed.
- Pydantic validation and deterministic caching prevent wasted compute. Configuration errors are caught at initialization before any job runs, and a hash-based caching system ensures expensive computations like LLM embeddings are performed once and reused across all experiments.
- The same code runs on a laptop or a SLURM cluster. NeuralSet’s hardware-agnostic backend, powered by the
excapackage, lets researchers and AI devs scale seamlessly from local prototyping to high-performance cluster execution by updating a single configuration flag.
Check out the Paper and GitHub Page. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
















