In this article, you will learn how TurboQuant, a novel algorithmic suite recently launched by Google, achieves advanced compression of large language models and vector search engines with no loss of accuracy.
Topics we will cover include:
- What TurboQuant is and why it represents a meaningful advance over prior quantization techniques.
- How the two-stage compression process — PolarQuant followed by QJL — works together to eliminate memory overhead and hidden bias.
- Why TurboQuant’s approach to KV cache compression is grounded in strong theoretical foundations rather than purely practical engineering.

Effective KV Compression with TurboQuant
Image by Editor
Introduction
TurboQuant has recently been launched by Google as a novel algorithmic suite and library for applying advanced quantization and compression to large language models (LLMs) and vector search engines — an indispensable element of RAG systems. Put simply, the goal is to drastically improve the efficiency of these massive AI systems. TurboQuant has been shown to successfully reduce cache memory consumption down to just 3 bits, without requiring retraining the model or sacrificing accuracy.
This article takes a look at the steps behind the core TurboQuant algorithm for advanced compression, with particular focus on how Key-Value (KV) cache compression works — recall that Keys (K) and Values (V) are two of the three core projections of text embeddings applied inside LLMs’ attention mechanisms, playing a crucial role in autoregressive text generation models.
TurboQuant in a Nutshell
LLMs and vector search engines use high-dimensional vectors to process information with impressive results. However, this process demands vast amounts of memory, which usually causes major bottlenecks in so-called key-value (KV) cache — a quick-access “digital cheat sheet” containing frequently utilized information for real-time retrieval. Since managing larger context lengths scales KV cache access in a linear fashion, memory capacity and computing speed can become severely limited.
Vector quantization (VQ) techniques utilized in recent years alongside LLMs and RAG systems help reduce the size of text vectors to alleviate bottlenecks, but they frequently introduce a “memory overhead” side effect. They also require computing full-precision quantization constants on small blocks of data. For these reasons, the potential advantages of compression may ultimately be partially negated.
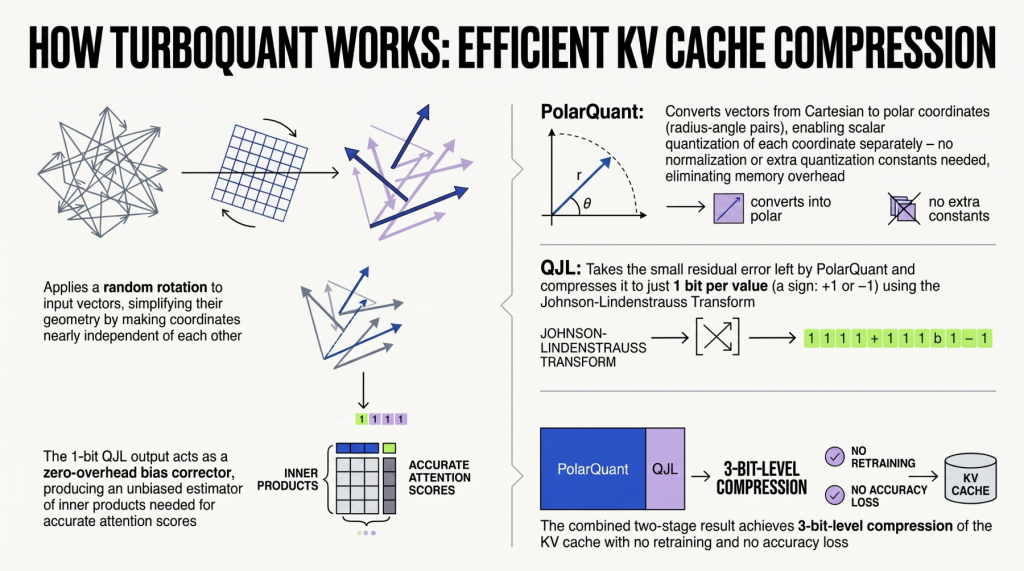
TurboQuant was proposed by Google as a suite of next-generation algorithms for advanced compression with zero loss of accuracy, accompanied by a Python library. TurboQuant optimally tackles the memory overhead issue by employing a two-stage process aided by two complementary techniques:
- PolarQuant: This is the compression technique applied at the first stage. It compresses high-dimensional data by mapping vector coordinates to a polar coordinate system. This simplifies data geometry and removes the need for storing extra quantization constants — the main cause of memory overhead.
- QJL (Quantized Johnson-Lindenstrauss): The second stage of the compression process. It focuses on removing possible biases introduced in the previous stage, acting as a mathematical checker that applies a minimal one-bit compression to remove hidden errors or residual biases resulting from PolarQuant.
Inside the KV Compression Process
To fully understand why TurboQuant’s KV compression is so highly effective, we need a closer look at its methodological stages. The algorithm addresses a fundamental mathematical challenge: when quantizers are optimized solely based on mean-squared error, hidden biases are inherently introduced during the estimation of inner products among vector data objects — an essential operation when calculating accurate attention scores inside LLMs, for instance.
To address this bias challenge, the first stage of the algorithm (PolarQuant) applies a random rotation to the data vectors. As a result, the data geometry is simplified by inducing a compact Beta distribution on each coordinate. In high-dimensional vectors, distinct coordinates become almost fully independent of each other. This high level of independence is key to easily and optimally applying a standard scalar quantizer to every part of the vector separately. PolarQuant converts the vector into polar coordinates described by a radius-angle pair, instead of using Cartesian coordinates, such that data is mapped onto a “circular grid”, eliminating the need for costly data normalization and the associated memory overhead. In short, most of the compression effort takes place in this first stage, capturing the main semantics and intensity of the original vector.
The second stage (QJL) is aimed at removing biases and hidden errors, since the MSE-optimization-driven first stage may leave a small residual error that potentially causes bias in attention score calculations. It applies a minimal level of compression — just 1-bit — using the QJL algorithm directly on the leftover error. The Johnson-Lindenstrauss Transform shrinks the high-dimensional residual data while preserving essential relationships, properties, and distances between data points. Each resulting number is reduced to just one sign bit (+1 or -1), behaving as a zero-overhead mathematical error checker. The result is an unbiased estimator that fully removes hidden leftover biases introduced in the first stage, yielding highly accurate attention scores.
Final Considerations
The methods underlying the TurboQuant algorithm for KV compression go beyond mere practical engineering solutions. They represent fundamental algorithmic solutions backed by strong theoretical proofs. TurboQuant has set a new benchmark for achievable efficiency near theoretical lower cost bounds, maintaining high precision compared to classical quantization while operating under an astounding 3-bit-level efficiency approach.
About Iván Palomares Carrascosa
Iván Palomares Carrascosa is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.