

The landscape of multimodal large language models (MLLMs) has shifted from experimental ‘wrappers’—where separate vision or audio encoders are stitched onto a text-based backbone—to native, end-to-end ‘omnimodal’ architectures. Alibaba Qwen team latest release, Qwen3.5-Omni, represents a significant milestone in this evolution. Designed as a direct competitor to flagship models like Gemini 3.1 Pro, the Qwen3.5-Omni series introduces a unified framework capable of processing text, images, audio, and video simultaneously within a single computational pipeline.
The technical significance of Qwen3.5-Omni lies in its Thinker-Talker architecture and its use of Hybrid-Attention Mixture of Experts (MoE) across all modalities. This approach enables the model to handle massive context windows and real-time interaction without the traditional latency penalties associated with cascaded systems.
Model Tiers
The series is offered in three sizes to balance performance and cost:
- Plus: High-complexity reasoning and maximum accuracy.
- Flash: Optimized for high-throughput and low-latency interaction.
- Light: A smaller variant for efficiency-focused tasks.
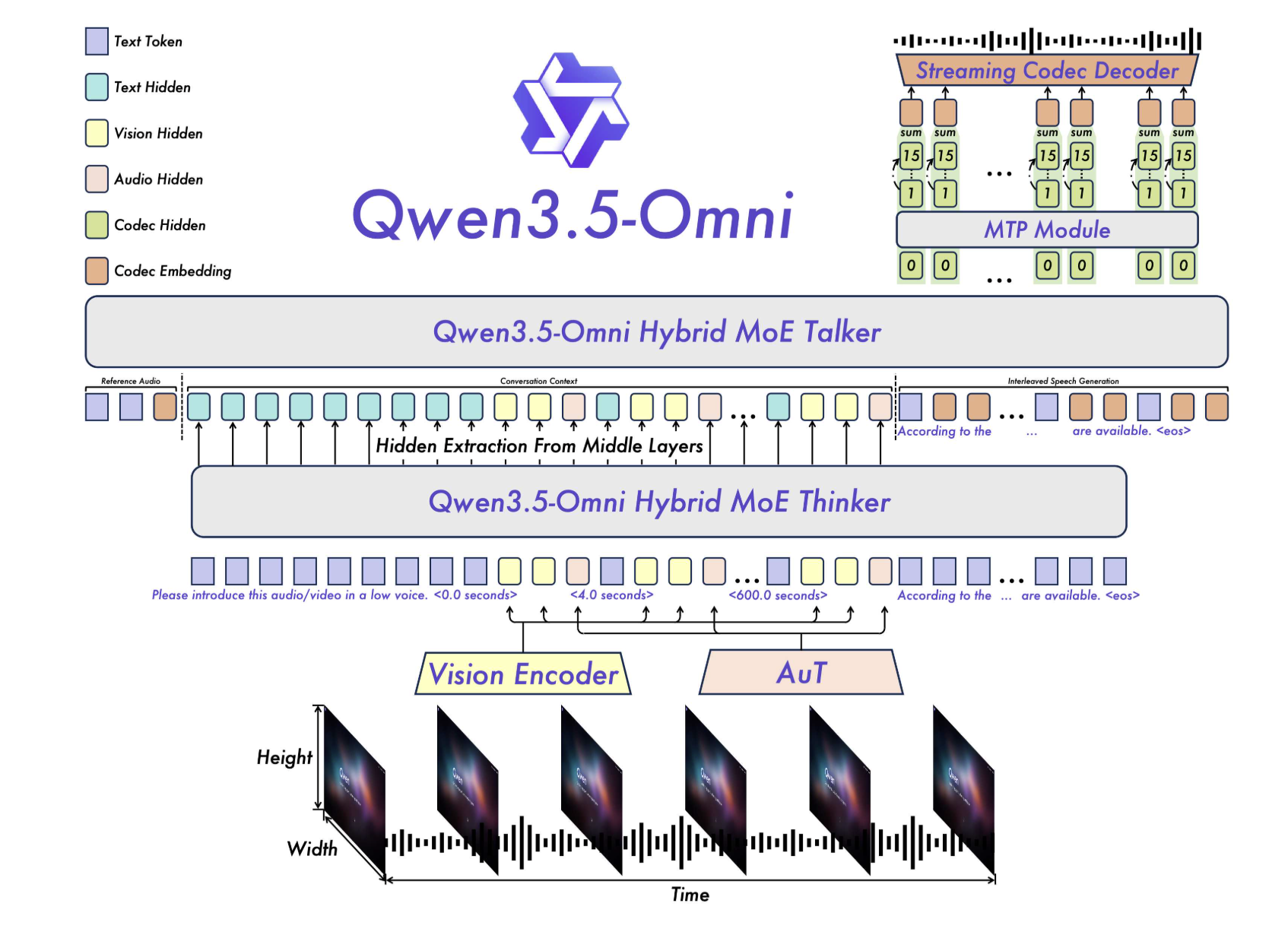
The Thinker-Talker Architecture: A Unified MoE Framework
At the core of Qwen3.5-Omni is a bifurcated yet tightly integrated architecture consisting of two main components: the Thinker and the Talker.
In previous iterations, multimodal models often relied on external pre-trained encoders (such as Whisper for audio). Qwen3.5-Omni moves beyond this by utilizing a native Audio Transformer (AuT) encoder. This encoder was pre-trained on more than 100 million hours of audio-visual data, providing the model with a grounded understanding of temporal and acoustic nuances that traditional text-first models lack.
Hybrid-Attention Mixture of Experts (MoE)
Both the Thinker and the Talker leverage Hybrid-Attention MoE. In a standard MoE setup, only a subset of parameters (the ‘experts’) are activated for any given token, which allows for a high total parameter count with lower active computational costs. By applying this to a hybrid-attention mechanism, Qwen3.5-Omni can effectively weigh the importance of different modalities (e.g., focusing more on visual tokens during a video analysis task) while maintaining the throughput required for streaming services.
This architecture supports a 256k long-context input, enabling the model to ingest and reason over:
- Over 10 hours of continuous audio.
- Over 400 seconds of 720p audio-visual content (sampled at 1 FPS).
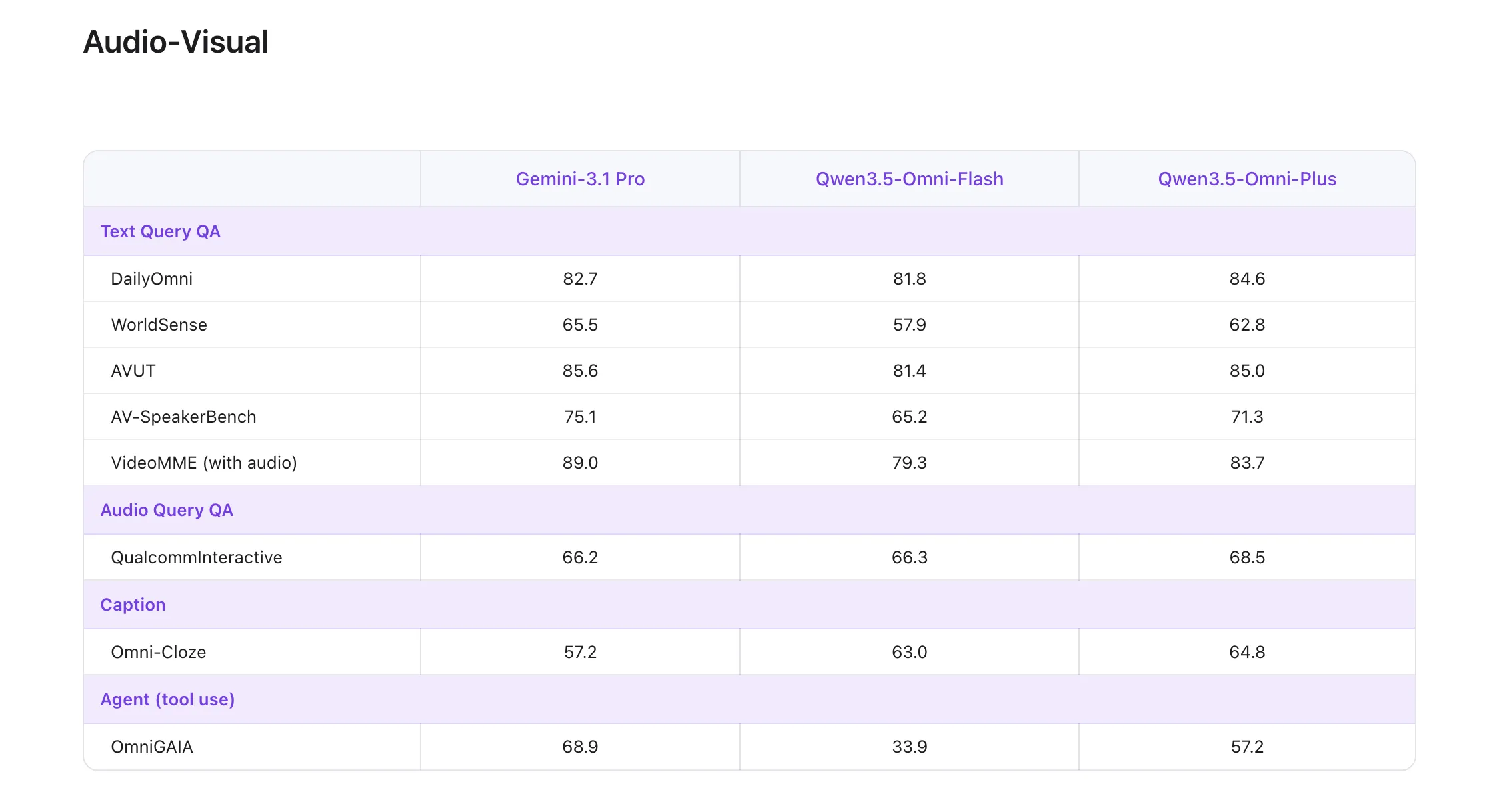
Benchmarking Performance: The ‘215 SOTA’ Milestone
One of the most highlighted technical claims regarding the flagship Qwen3.5-Omni-Plus model is its performance on the global leaderboard. The model achieved State-of-the-Art (SOTA) results on 215 audio and audio-visual understanding, reasoning, and interaction subtasks.
These 215 SOTA wins are not merely a measure of broad evaluation but span specific technical benchmarks, including:
- 3 audio-visual benchmarks and 5 general audio benchmarks.
- 8 ASR (Automatic Speech Recognition) benchmarks.
- 156 language-specific Speech-to-Text Translation (S2TT) tasks.
- 43 language-specific ASR tasks.
According to their official technical reports, Qwen3.5-Omni-Plus surpasses Gemini 3.1 Pro in general audio understanding, reasoning, recognition, and translation. In audio-visual understanding, it achieves parity with Google’s flagship, while maintaining the core text and visual performance of the standard Qwen3.5 series.
Technical Solutions for Real-Time Interaction
Building a model that can ‘talk’ and ‘hear’ in real-time requires solving specific engineering challenges related to streaming stability and conversational flow.
ARIA: Adaptive Rate Interleave Alignment
A common failure mode in streaming voice interaction is ‘speech instability.’ Because text tokens and speech tokens have different encoding efficiencies, a model may misread numbers or stutter when attempting to synchronize its text reasoning with its audio output.
To address this, Alibaba Qwen team developed ARIA (Adaptive Rate Interleave Alignment). This technique dynamically aligns text and speech units during generation. By adjusting the interleave rate based on the density of the information being processed, ARIA improves the naturalness and robustness of speech synthesis without increasing latency.
Semantic Interruption and Turn-Taking
For AI developers building voice assistants, handling interruptions is notoriously difficult. Qwen3.5-Omni introduces native turn-taking intent recognition. This allows the model to distinguish between ‘backchanneling’ (non-meaningful background noise or listener feedback like ‘uh-huh’) and an actual semantic interruption where the user intends to take the floor. This capability is baked directly into the model’s API, enabling more human-like, full-duplex conversations.
Emergent Capability: Audio-Visual Vibe Coding
Perhaps the most unique feature identified during the native multimodal scaling of Qwen3.5-Omni is Audio-Visual Vibe Coding. Unlike traditional code generation that relies on text prompts, Qwen3.5-Omni can perform coding tasks based directly on audio-visual instructions.
For instance, a developer could record a video of a software UI, verbally describe a bug while pointing at specific elements, and the model can directly generate the fix. This emergence suggests that the model has developed a cross-modal mapping between visual UI hierarchies, verbal intent, and symbolic code logic.
Key Takeaways
- Qwen3.5-Omni uses a native Thinker-Talker multimodal architecture for unified text, audio, and video processing.
- The model supports 256k context, 10+ hours of audio, and 400+ seconds of 720p video at 1 FPS.
- Alibaba reports speech recognition in 113 languages/dialects and speech generation in 36 languages/dialects.
- Key system features include semantic interruption, turn-taking intent recognition, TMRoPE, and ARIA for realtime interaction.
Check out the Technical details, Qwenchat, Online demo on HF and Offline demo on HF. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.















