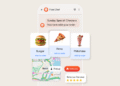
What Is a Robots.txt File?
A robots.txt file is a set of rules that tells web crawlers which pages or sections of a website they should crawl and which to avoid.
It looks like this:

Robots.txt files may look complicated.
But the syntax (computer language) is straightforward—“Allow” means the web crawler should crawl it, while “disallow” means the crawler should not crawl it.
But keep in mind:
While robots.txt guides crawler behavior, it doesn’t guarantee that a page won’t appear in search results. Other factors (like external links) can still cause it to be indexed by Google.
To block indexing, you should use Meta Robots and X-Robots-Tag.
Robots.txt vs. Meta Robots vs. X-Robots
Robots.txt tells search engines what not to crawl—meta robots tags and s-tobots-tags tell them what not to index.
Knowing the difference helps you apply the right tool for the right situation.
Here’s how they compare:
- Robots.txt: This file is located in the website’s root directory and provides site-wide instructions to search engine crawlers on which areas of the site they should and shouldn’t crawl
- Meta robots tags: These tags are snippets of code in the <head> sections of individual webpages and provide page-specific instructions to search engines on whether to index (include in search results) and follow (crawl the links on) each page
- X-robot tags: These code snippets are used primarily for non-HTML files (like PDFs and images) and are implemented in the file’s HTTP header
If you want to keep something out of search results, use a noindex meta tag (on a crawlable page) or password-protect the page.
Why Does Robots.txt Matter?
A robots.txt file helps control how bots interact with your site.
SEOs often use it to manage crawl load and improve efficiency by blocking unimportant or duplicate pages. It can also be used to deter scraping and prevent content from being used to train AI models.
Here’s a breakdown of why robots.txt files matter specifically for SEO:
It Optimizes Your Crawl Budget
A robots.txt file helps search engines focus their crawl budgets on your most valuable pages.
Blocking low-value pages (like cart, login, or filter pages) helps bots prioritize crawling content that actually drives traffic and rankings, especially on large sites with thousands of URLs.
For example:
Blocking “/cart/” or “/login/” pages helps bots focus on your blog posts or product pages instead.
It Can Be Used to Control Search Appearance
Robots.txt gives you some control over how your site appears in search by managing what gets crawled.
While it doesn’t directly affect indexing, it works with the below to guide search engines toward your important content:
- Sitemap: A file that lists the important pages on your site to help search engines discover and crawl them more efficiently
- Canonical tags: An HTML tag that tells search engines which version of a page is the preferred one to index when duplicate or similar content exists
- Noindex directives: A signal (via a meta tag or HTTP header) that tells search engines not to include a specific page or pages in the index used for search results
It Helps Deter Scrapers and Unwanted Bots
Robots.txt is the first line of defense against unwanted crawlers, such as scrapers or bots harvesting content for training AI models.
For example, many sites now disallow AI bots’ user-agents via robots.txt.
This sends a clear signal to bots that respect the protocol and helps reduce server load from non-essential crawlers.
We partnered with SEO Consultant Bill Widmer to run a quick experiment and demonstrate how robots.txt rules impact crawler behavior in real-world conditions.
Here’s what happened:
Bill had a rule in his robots.txt file blocking a number of crawlers.
He used Semrush’s Site Audit tool to crawl the entire site, setting the crawl limit high enough to catch all live pages.
But his website wasn’t crawled due to the robots.txt directives.

After adjusting the robots.txt file, he ran the crawl again.
This time, his website was successfully crawled and included in the report.

How to Create a Robots.txt File
A robots.txt file is easy to create—decide what to block, write your rules in a text file, and upload it to your site’s root directory.
Just follow these steps:
1. Decide What to Control
Identify which parts of your site should or shouldn’t be crawled.
Consider blocking:
- Login and user account pages (e.g., /login/) that don’t offer public value and can waste crawl budget
- Cart and checkout pages (e.g., /cart/) you don’t want in search results
- Thank-you pages or form submission confirmation screens (e.g., /thank-you/) that aren’t useful to searchers
If you’re unsure, it’s best to err on the side of allowing rather than disallowing.
Incorrect disallow rules can cause search engines to miss important content or fail to render your pages correctly.
2. Target Specific Bots (Optional)
You can write rules for all bots (User-agent: *) or target specific ones like Googlebot (User-agent: Googlebot) or Bingbot (User-agent: Bingbot), depending on your specific needs.
Here are two situations when this makes sense:
- Controlling aggressive or less important bots: Some bots crawl frequently and can put an unnecessary load on your server. You might want to limit or block these types of bots.
- Blocking AI crawlers used for training generative models: If you don’t want your content included in the training data for tools like ChatGPT or other LLMs, you can block their crawlers (e.g., GPTBot) in your robots.txt file.
3. Create a Robots.txt File and Add Directives
Use a simple text editor like Notepad (Windows) or TextEdit (Mac) to create your file and save it as “robots.txt.”
In this file, you’ll add your directives—the syntax that tells search engine crawlers which parts of your site they should and shouldn’t access.
A robots.txt file contains one or more groups of directives, and each group includes multiple lines of instructions.
Each group starts with a user-agent and specifies:
- Which user-agent(s) the group applies to
- Which directories (pages) or files the user-agent(s) should access
- Which directories or files the user-agent(s) shouldn’t access
Optionally, include a sitemap to tell search engines which pages and files are most important. Just don’t forget to submit your sitemap directly in Google Search Console.
Imagine you don’t want Google to crawl your “/clients/” directory because it’s primarily for internal use and doesn’t provide value for searchers.
The first group in your file would look like this block:
User-agent: Googlebot
Disallow: /clients/
You can add more instructions for Google after that, like this:
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-google
Then press enter twice to start a new group of directives.
For example, to prevent access to “/archive/” and “/support/” directories for all search engines.
Here’s a block preventing access to those directories:
User-agent: *
Disallow: /archive/
Disallow: /support/
Once you’re finished, add your sitemap:
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-google
User-agent: *
Disallow: /archive/
Disallow: /support/
Sitemap: https://www.yourwebsite.com/sitemap.xml
Feeling unsure?
Use a free robots.txt generator to help you generate the text for your robots.txt file. Then, copy and paste the output to a text editor.

4. Upload the File to Your Site’s Root Directory
Search engines will only read your robots.txt file if it’s placed in the root directory of your domain.
This means the file must be at the top level of your site—not in a subfolder.
To upload the file correctly, use your web hosting file manager, FTP client, or CMS settings to upload the file to the root directory (usually called “public_html” or “/www”).
If you’re using WordPress, you can use a plugin like Yoast SEO or Rank Math to upload the file to your site’s root directory for you.
Just open the plugin’s settings, navigate to the robots.txt option, and upload your file.

5. Confirm the File Was Uploaded Successfully
Use Google’s robots.txt report in Search Console to check for errors and confirm your rules work as intended.
In Search Console, navigate to the “Settings” page and click “Open Report” next to “robots.txt.”

It should have a green checkmark next to “Fetched” under the status column.
But if there was an error, you’ll see a red exclamation mark next to “Not Fetched.” In that case, check Google’s guidelines to determine what the error was and how to fix it.
It can be difficult to understand Google’s solutions to errors if you’re new to robots.txt.
If you want an easier way, use Semrush’s Site Audit tool to check your robots.txt file for technical issues and get detailed instructions on how to fix them.
Set up a project and run an audit.
When the tool is ready, navigate to the “Issues” tab and search for “robots.txt.”

Click “Robots.txt file has format errors” if it appears.

View the list of invalid lines to determine exactly what needs to be addressed.

Check your robots.txt file regularly. Even small errors can affect your site’s indexability.
Robots.txt Best Practices
Follow these best practices to ensure your robots.txt file helps your SEO and site performance:
Use Wildcards Carefully
Wildcards (* and $) let you match broad patterns in URLs, and using them precisely is important to avoid accidentally blocking important pages.
- * matches any sequence of characters, including slashes. It’s used to block multiple URLs that share a pattern. (Example: “Disallow: /search*” blocks “/search,” “/search?q=shoes,” and “/search/results/page/2.”)
- $ matches the end of a URL. It’s used when you want to block only URLs that end in a specific way. (Example: “Disallow: /thank-you$” blocks “/thank-you” but not /thank-you/page.)
Here are some examples of how not to use them:
Disallow: /*.php blocks every URL ending in “.php,” which could include important pages like “/product.php” or “/blog-post.php”
Disallow: /.html$ blocks all pages ending in “.html,” which might include all your main site content
If you’re unsure, it’s wise to consult a professional before using wildcards in your robots.txt file.
Avoid Blocking Important Resources
Don’t block CSS, JavaScript, or API endpoints required to render your site. Google needs them to understand layout, functionality, and mobile-readiness.
So, let crawlers access:
- /assets/
- /js/
- /css/
- /api/
Blocking these could cause Google to see a broken version of your pages and hurt your rankings.
Always test your site in Google’s URL Inspection Tool to ensure blocked assets aren’t interfering with rendering.
Enter a URL you want to test.
You should see a green checkmark if it’s done properly. If you see “Blocked by robots.txt,” the page (or an asset it depends on) is blocked from crawling.

Don’t Use Robots.txt to Keep Pages Out of Search Results
If a URL is linked from elsewhere, Google can still index it and show it in search results—even if you’ve disallowed it in robots.txt.
That means you shouldn’t rely on robots.txt to hide:
- Sensitive or private data (e.g., admin dashboards, internal reports)
- Duplicate content (e.g., filtered or paginated URLs)
- Staging or test sites
- Any page you don’t want appearing in Google
Add Comments
Use comments to document your rules, so others (or future you) can understand your intentions.
Start a comment by adding a “#”. Anything after it on the same line will be ignored by crawlers.
For example:
# Block internal search results but allow all other pages for all crawlers
User-agent: *
Disallow: /search/
Allow: /
Comments are especially important for growing teams and complex sites.
Robots.txt and AI: Should You Block LLMs?
AI tools like ChatGPT and those built on other large language models (LLMs) are trained on web content—and your robots.txt file is the primary way for you to manage how they crawl your site.
To allow or block AI crawlers used to train models, add user-agent directives to your robots.txt file just like you would for Googlebot.
For example, OpenAI’s GPTBot is used to collect publicly available data that can be used for training large language models. To block it, you can include a line like “User-agent: GPTBot” followed by your chosen disallow rule.
When should you allow or block AI crawlers?
You should allow AI crawlers if:
- You want to increase exposure and don’t mind your content being used in generative tools
- You believe the benefits of increased visibility and brand awareness outweigh control over how your content is used to train generative AI tools
You should consider blocking AI crawlers if:
- You’re concerned about your intellectual property
- You want to maintain full control over how your content is used
A new file called llms.txt is being proposed to offer more granular control over how AI models access your content.
We wanted to see how many .com websites have an llms.txt file to see how commonly used this new file type is.
This rough experiment shows that only ~2,830 of .com websites indexed in Google have an llms.txt file.

As new updates come out, llms.txt files may become more important. Only time will tell.
Check Your Website for Robots.txt and Other Technical Issues
A well-configured robots.txt file is a powerful tool for guiding search engines, protecting your resources, and keeping your site efficient.
But it’s important to ensure your file is free from technical errors.
Use Site Audit to automatically check for robots.txt errors, crawl issues, broken links, and other technical SEO issues.