
Retrieval is where most RAG systems quietly break. Traditional pipelines rely on vector similarity—embedding queries and document chunks into the same space and fetching the “closest” matches. But similarity is a weak proxy for what we actually need: relevance grounded in reasoning. In long, professional documents—like financial reports, research papers, or legal texts—the right answer often isn’t in the most semantically similar paragraph. It requires navigating structure, understanding context, and performing multi-step reasoning across sections. This is exactly where vector-based RAG starts to fall apart.
PageIndex is designed to solve this gap by rethinking retrieval from first principles. Instead of chunking documents and searching via embeddings, it builds a hierarchical table-of-contents-style tree index and uses LLMs to reason over that structure—much like a human expert scanning sections, drilling down, and connecting ideas. This enables a vectorless, reasoning-driven retrieval process that is more interpretable, traceable, and aligned with how knowledge is actually extracted from complex documents. By replacing similarity search with structured exploration and tree-based reasoning, PageIndex delivers significantly higher retrieval accuracy—demonstrated by its strong performance on benchmarks like FinanceBench—making it particularly effective for domains that demand precision and deep understanding.

In this article, we’ll use PageIndex to index the seminal Transformer paper — “Attention Is All You Need” — and run two cross-cutting queries against it without a single vector or embedding. Instead of chunking the PDF and retrieving by similarity, PageIndex builds a hierarchical tree of the document’s sections, then uses GPT-5.4 to reason over node summaries and identify exactly which sections contain the answer — before reading a single word of full text.

Setting up the dependencies
For this tutorial, you would require PageIndex & OpenAI API keys. You can get the same from https://dash.pageindex.ai/api-keys and https://platform.openai.com/api-keys respectively.
pip install pageindex openai requestsfrom pageindex import PageIndexClient
import pageindex.utils as utils
import os
from getpass import getpass
PAGEINDEX_API_KEY = getpass('Enter PageIndex API Key: ')
pi_client = PageIndexClient(api_key=PAGEINDEX_API_KEY)We import the OpenAI client and configure it with an API key to enable access to LLMs. Then, we define an asynchronous helper function that sends prompts to the model and returns the generated response.
import openai
OPENAI_API_KEY = getpass('Enter OpenAI API Key: ')
async def call_llm(prompt, model="gpt-5.4", temperature=0):
client = openai.AsyncOpenAI(api_key=OPENAI_API_KEY)
response = await client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature
)
return response.choices[0].message.content.strip()Building the PageIndex Tree
In this chunk, we download the Transformer paper directly from arXiv and submit it to PageIndex, which processes the PDF and builds a hierarchical tree of its sections — each node storing a title, a summary, and the full section text. Once the tree is ready, we print it out to inspect the structure PageIndex has inferred: every chapter, subsection, and nested heading becomes a node in the tree, preserving the document’s natural organization exactly as the authors intended it.
# ─────────────────────────────────────────────
# Step 1: Build the PageIndex Tree
# ─────────────────────────────────────────────
# 1.1 Download the Transformer paper and submit it
import os, requests
pdf_url = "https://arxiv.org/pdf/1706.03762.pdf"
pdf_path = os.path.join("data", pdf_url.split("/")[-1])
os.makedirs("data", exist_ok=True)
print("Downloading 'Attention Is All You Need'...")
response = requests.get(pdf_url)
with open(pdf_path, "wb") as f:
f.write(response.content)
print(f"✅ Saved to {pdf_path}")
doc_id = pi_client.submit_document(pdf_path)["doc_id"]
print(f"📄 Document submitted. doc_id: {doc_id}")
# 1.2 Retrieve the tree (poll until ready)
import time
print("\nWaiting for PageIndex tree to be ready", end="")
while not pi_client.is_retrieval_ready(doc_id):
print(".", end="", flush=True)
time.sleep(5)
tree = pi_client.get_tree(doc_id, node_summary=True)["result"]
print("\n\n📂 Document Tree Structure:")
utils.print_tree(tree)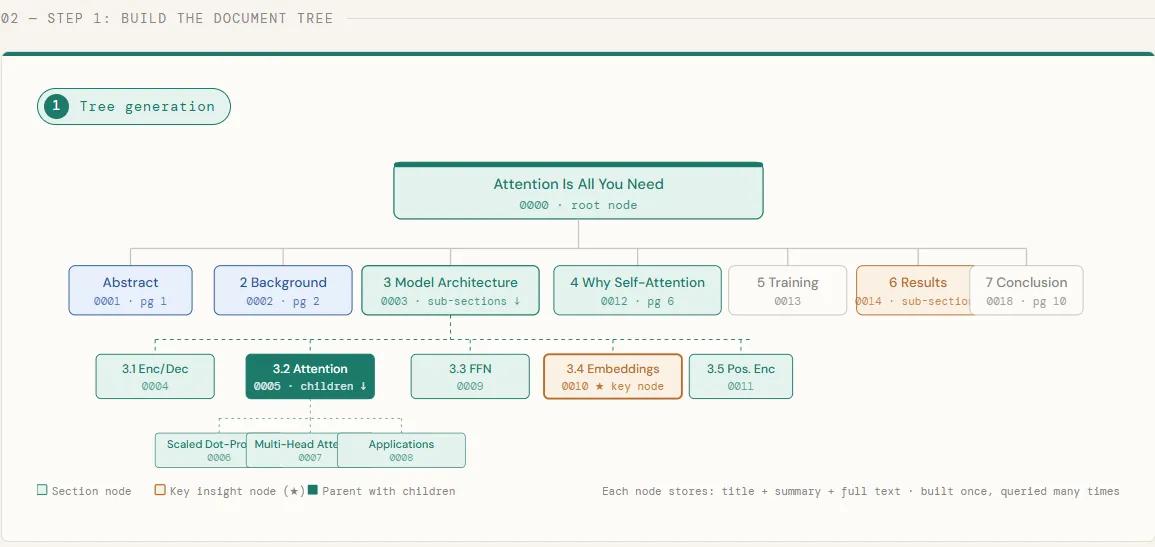
Reasoning-Based Retrieval
With the tree built, we now run a query that is intentionally cross-cutting — one that can’t be answered by a single section of the paper. We strip the full text from each node, leaving only titles and summaries, and pass the entire tree structure to GPT-5.4. The model then reasons over these summaries to identify every node likely to contain a relevant answer, returning both its step-by-step thinking and a list of matched node IDs. This is the core of what makes PageIndex different: the LLM decides where to look before any full text is loaded.
# ─────────────────────────────────────────────
# Step 2: Reasoning-Based Retrieval
# ─────────────────────────────────────────────
# 2.1 Define a query that requires navigating across sections
import json
# This query is intentionally cross-cutting -- it can't be answered
# by a single section, which is where tree search shines over top-k.
query = "Why did the authors choose self-attention over recurrence, and what are the complexity trade-offs they compared?"
tree_without_text = utils.remove_fields(tree.copy(), fields=["text"])
search_prompt = f"""
You are given a question and a hierarchical tree structure of a research paper.
Each node has a node_id, title, and a summary of its content.
Your task: identify ALL nodes that are likely to contain information relevant to answering the question.
Think carefully -- the answer may be spread across multiple sections.
Question: {query}
Document tree:
{json.dumps(tree_without_text, indent=2)}
Reply ONLY in this JSON format, no preamble:
{{
"thinking": "<step-by-step reasoning about which nodes are relevant and why>",
"node_list": ["node_id_1", "node_id_2", ...]
}}
"""
print(f'🔍 Query: "{query}"\n')
print("Running tree search with GPT-5.4...")
tree_search_result = await call_llm(search_prompt)
# 2.2 Inspect the retrieval reasoning and matched nodes
node_map = utils.create_node_mapping(tree)
result_json = json.loads(tree_search_result)
print("\n🧠 LLM Reasoning:")
utils.print_wrapped(result_json["thinking"])
print("\n📌 Retrieved Nodes:")
for node_id in result_json["node_list"]:
node = node_map[node_id]
print(f" • [{node['node_id']}] Page {node['page_index']:>2} -- {node['title']}")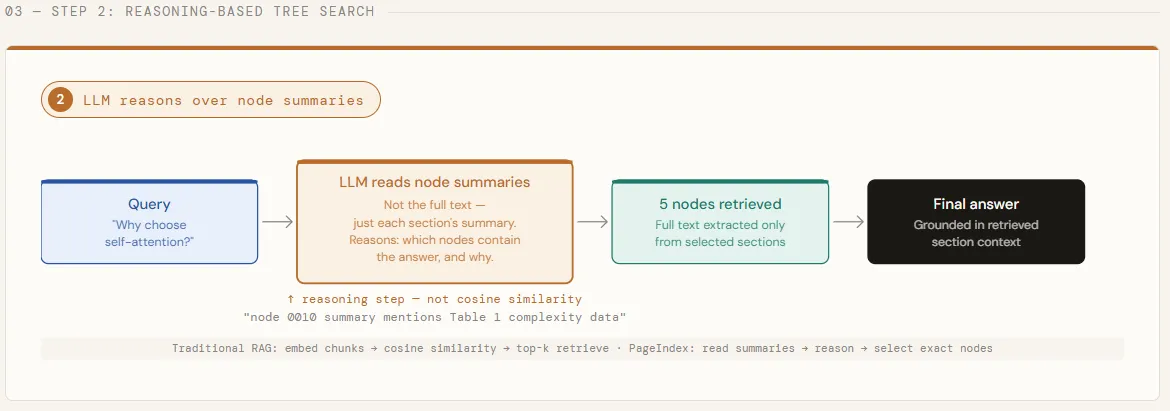
Answer Generation
Once the relevant nodes are identified, we pull their full text and stitch it together into a single context block — each section clearly labeled so the model knows where each piece of information comes from. That combined context is then handed to GPT-5.4 with a structured prompt that asks for the core motivation, the specific complexity numbers, and any caveats the authors acknowledged. The model answers using only what was retrieved, grounding every claim directly in the paper’s text.
# ─────────────────────────────────────────────
# Step 3: Answer Generation
# ─────────────────────────────────────────────
# 3.1 Stitch together context from all retrieved nodes
node_list = result_json["node_list"]
relevant_content = "\n\n---\n\n".join(
f"[Section: {node_map[nid]['title']}]\n{node_map[nid]['text']}"
for nid in node_list
)
print(f"\n📖 Retrieved Context Preview (first 1200 chars):\n")
utils.print_wrapped(relevant_content[:1200] + "...\n")
# 3.2 Generate a structured answer grounded in the retrieved sections
answer_prompt = f"""
You are a technical assistant. Answer the question below using ONLY the provided context.
Be specific -- reference actual design choices, numbers, and trade-offs mentioned in the text.
Question: {query}
Context:
{relevant_content}
Structure your answer as:
1. The core motivation for choosing self-attention
2. The specific complexity comparisons made (include any tables or numbers)
3. Any caveats or limitations the authors acknowledged
"""
print("💬 Generating answer...\n")
answer = await call_llm(answer_prompt)
print("─" * 60)
print("✅ Final Answer:\n")
utils.print_wrapped(answer)
print("─" * 60)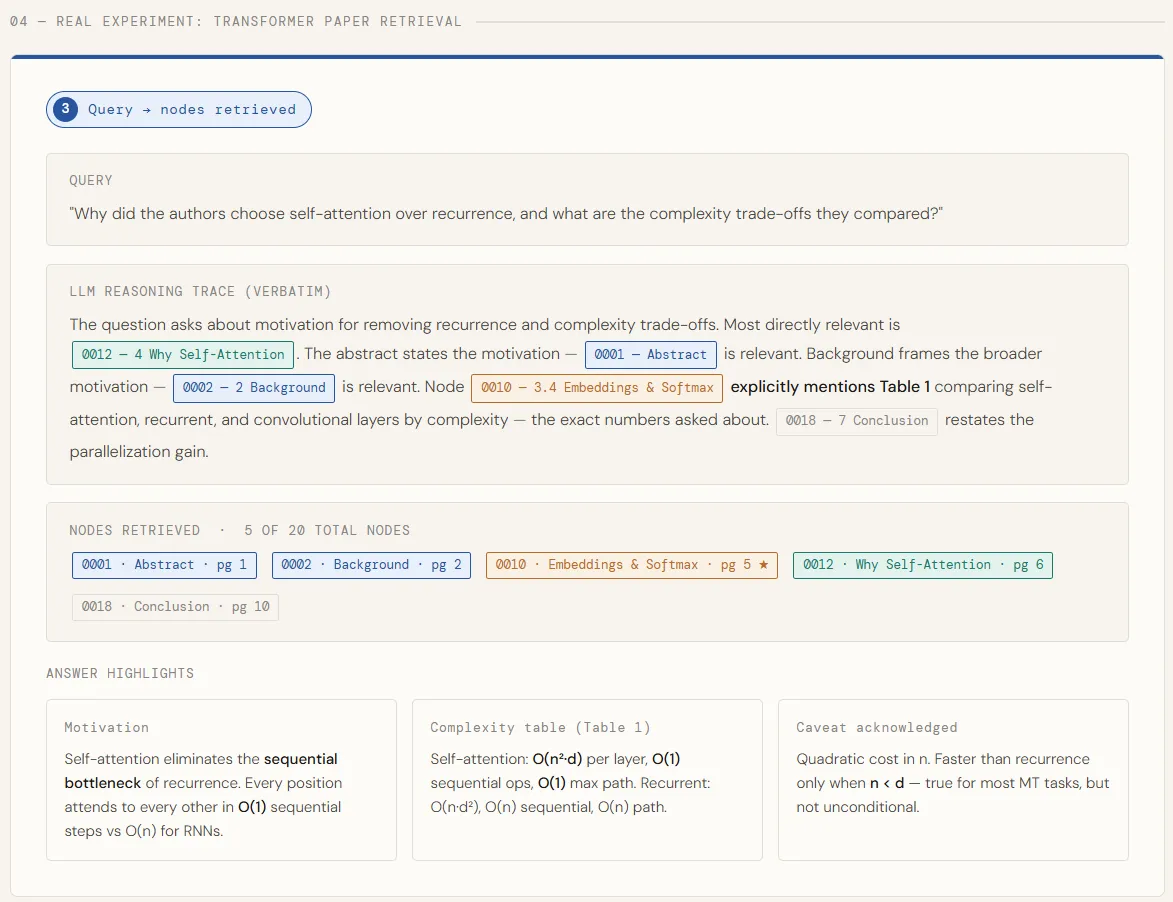

Testing with a Second Query
To show that the tree is built once and reused at no extra cost, we run a second query — this time targeting a localized mechanism rather than a cross-cutting design decision. The same tree structure is passed to GPT-5.4, which narrows its search to just the attention subsections, retrieves their full text, and generates a clean explanation of how multi-head attention works and why the scaling factor matters. No re-indexing, no re-embedding — just a new question against the same tree.
query2 = "How does the multi-head attention mechanism work, and what is the role of scaling in dot-product attention?"
search_prompt2 = f"""
You are given a question and a hierarchical tree structure of a research paper.
Identify all nodes likely to contain the answer.
Question: {query2}
Document tree:
{json.dumps(tree_without_text, indent=2)}
Reply ONLY in this JSON format:
{{
"thinking": "<reasoning>",
"node_list": ["node_id_1", ...]
}}
"""
print(f'\n\n🔍 Second Query: "{query2}"\n')
result2_raw = await call_llm(search_prompt2)
result2 = json.loads(result2_raw)
print("🧠 Reasoning:")
utils.print_wrapped(result2["thinking"])
relevant_content2 = "\n\n---\n\n".join(
f"[Section: {node_map[nid]['title']}]\n{node_map[nid]['text']}"
for nid in result2["node_list"]
)
answer_prompt2 = f"""
Answer the following question using ONLY the provided context.
Explain the mechanism clearly, as if for a technical blog post.
Question: {query2}
Context: {relevant_content2}
"""
answer2 = await call_llm(answer_prompt2)
print("\n✅ Answer:\n")
utils.print_wrapped(answer2)
Check out the Full Codes here. Find 100s of ML/Data Science Colab Notebooks here. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us

I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various areas.













