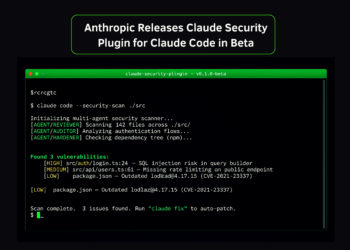
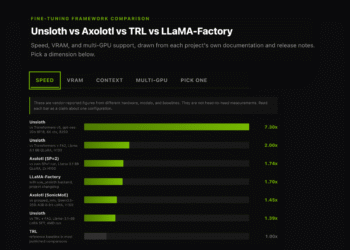
“”“Process the WikiText dataset for training the BERT model. Using Hugging Face
datasets library.
““”
import time
import random
from typing import Iterator
import tokenizers
from datasets import load_dataset, Dataset
# path and name of each dataset
DATASETS = {
“wikitext-2”: (“wikitext”, “wikitext-2-raw-v1”),
“wikitext-103”: (“wikitext”, “wikitext-103-raw-v1”),
}
PATH, NAME = DATASETS[“wikitext-103”]
TOKENIZER_PATH = “wikitext-103_wordpiece.json”
def create_docs(path: str, name: str, tokenizer: tokenizers.Tokenizer) -> list[list[list[int]]]:
“”“Load wikitext dataset and extract text as documents”“”
dataset = load_dataset(path, name, split=“train”)
docs: list[list[list[int]]] = []
for line in dataset[“text”]:
line = line.strip()
if not line or line.startswith(“=”):
docs.append([]) # new document encountered
else:
tokens = tokenizer.encode(line).ids
docs[–1].append(tokens)
docs = [doc for doc in docs if doc] # remove empty documents
return docs
def create_dataset(
docs: list[list[list[int]]],
tokenizer: tokenizers.Tokenizer,
max_seq_length: int = 512,
doc_repeat: int = 10,
mask_prob: float = 0.15,
short_seq_prob: float = 0.1,
max_predictions_per_seq: int = 20,
) -> Iterator[dict]:
“”“Generate samples from all documents”“”
doc_indices = list(range(len(docs))) * doc_repeat
for doc_idx in doc_indices:
yield from generate_samples(doc_idx, docs, tokenizer, max_seq_length, mask_prob, short_seq_prob, max_predictions_per_seq)
def generate_samples(
doc_idx: int,
all_docs: list[list[list[int]]],
tokenizer: tokenizers.Tokenizer,
max_seq_length: int = 512,
mask_prob: float = 0.15,
short_seq_prob: float = 0.1,
max_predictions_per_seq: int = 20,
) -> Iterator[dict]:
“”“Generate samples from a given document”“”
# number of tokens to extract from this doc, excluding [CLS], [SEP], [SEP]
target_length = max_seq_length – 3
if random.random() < short_seq_prob:
# shorter sequence is used 10% of the time
target_length = random.randint(2, target_length)
# copy the document
chunks = []
for chunk in all_docs[doc_idx]:
chunks.append(chunk)
# exhaust chunks and create samples
while chunks:
# scan until target token length
running_length = 0
end = 1
while end < len(chunks) and running_length < target_length:
running_length += len(chunks[end–1])
end += 1
# randomly separate the chunk into two segments
sep = random.randint(1, end–1) if end > 1 else 1
sentence_a = [tok for chunk in chunks[:sep] for tok in chunk]
sentence_b = [tok for chunk in chunks[sep:end] for tok in chunk]
# sentence B: may be from another document
if not sentence_b or random.random() < 0.5:
# find another document (must not be the same as doc_idx)
b_idx = random.randint(0, len(all_docs)–2)
if b_idx >= doc_idx:
b_idx += 1
# sentence B starts from a random position in the new document
sentence_b = []
running_length = len(sentence_a)
i = random.randint(0, len(all_docs[b_idx])–1)
while i < len(all_docs[b_idx]) and running_length < target_length:
sentence_b.extend(all_docs[b_idx][i])
running_length += len(all_docs[b_idx][i])
i += 1
is_random_next = True
chunks = chunks[sep:]
else:
is_random_next = False
chunks = chunks[end:]
# create a sample from the pair
yield create_sample(sentence_a, sentence_b, is_random_next, tokenizer, max_seq_length, mask_prob, max_predictions_per_seq)
def create_sample(
sentence_a: list[list[int]],
sentence_b: list[list[int]],
is_random_next: bool,
tokenizer: tokenizers.Tokenizer,
max_seq_length: int = 512,
mask_prob: float = 0.15,
max_predictions_per_seq: int = 20,
) -> dict:
“”“Create a sample from a pair of sentences”“”
# Collect id of special tokens
cls_id = tokenizer.token_to_id(“[CLS]”)
sep_id = tokenizer.token_to_id(“[SEP]”)
mask_id = tokenizer.token_to_id(“[MASK]”)
pad_id = tokenizer.padding[“pad_id”]
# adjust length to fit the max sequence length
truncate_seq_pair(sentence_a, sentence_b, max_seq_length–3)
num_pad = max_seq_length – len(sentence_a) – len(sentence_b) – 3
# create unmodified tokens sequence
tokens = [cls_id] + sentence_a + [sep_id] + sentence_b + [sep_id] + ([pad_id] * num_pad)
seg_id = [0] * (len(sentence_a) + 2) + [1] * (len(sentence_b) + 1) + [–1] * num_pad
assert len(tokens) == len(seg_id) == max_seq_length
# create the prediction targets
cand_indices = [i for i, tok in enumerate(tokens) if tok not in [cls_id, sep_id, pad_id]]
random.shuffle(cand_indices)
num_predictions = int(round((len(sentence_a) + len(sentence_b)) * mask_prob))
num_predictions = min(max_predictions_per_seq, max(1, num_predictions))
mlm_positions = sorted(cand_indices[:num_predictions])
mlm_labels = []
for i in mlm_positions:
mlm_labels.append(tokens[i])
# prob 0.8 replace with [MASK], prob 0.1 replace with random word, prob 0.1 keep original
if random.random() < 0.8:
tokens[i] = mask_id
elif random.random() < 0.5:
tokens[i] = random.randint(4, tokenizer.get_vocab_size()–1)
# randomly mask some tokens
ret = {
“tokens”: tokens,
“segment_ids”: seg_id,
“is_random_next”: is_random_next,
“masked_positions”: mlm_positions,
“masked_labels”: mlm_labels,
}
return ret
def truncate_seq_pair(sentence_a: list[int], sentence_b: list[int], max_num_tokens: int) -> None:
“”“Truncate a pair of sequences until below a maximum sequence length.”“”
while len(sentence_a) + len(sentence_b) > max_num_tokens:
# pick the longer sentence to remove tokens from
candidate = sentence_a if len(sentence_a) > len(sentence_b) else sentence_b
# remove one token from either end in equal probabilities
if random.random() < 0.5:
candidate.pop(0)
else:
candidate.pop()
if __name__ == “__main__”:
print(time.time(), “started”)
tokenizer = tokenizers.Tokenizer.from_file(TOKENIZER_PATH)
print(time.time(), “loaded tokenizer”)
docs = create_docs(PATH, NAME, tokenizer)
print(time.time(), “created docs with %d documents” % len(docs))
dataset = Dataset.from_generator(create_dataset, gen_kwargs={“docs”: docs, “tokenizer”: tokenizer})
print(time.time(), “created dataset from generator”)
# Save dataset to parquet file
dataset.to_parquet(“wikitext-103_train_data.parquet”)
print(time.time(), “saved dataset to parquet file”)
# Load dataset from parquet file
dataset = Dataset.from_parquet(“wikitext-103_train_data.parquet”, streaming=True)
print(time.time(), “loaded dataset from parquet file”)
# Print a few samples
for i, sample in enumerate(dataset):
print(i)
print(sample)
print()
if i >= 3:
break
print(time.time(), “finished”)