Miso Labs has released MisoTTS, an open-weights 8-billion-parameter text-to-speech model. It generates expressive speech from both text and audio context. The model uses residual vector quantization (RVQ) to widen its sonic range. This avoids scaling a single flat vocabulary while keeping parameter count fixed.
What is MisoTTS
MisoTTS is an 8B-parameter text-to-dialogue RVQ Transformer. It is inspired by the Sesame CSM architecture. It pairs a Llama 3.2-style backbone with a smaller audio decoder. It generates Mimi audio codes from text and optional audio context. The model conditions on both text and prior audio. That second input lets it respond to the speaker’s tone.
The text vocabulary is 128,256 tokens, and there are 32 audio codebooks. Mimi is the audio tokenizer, and max sequence length is 2,048. Default inference runs in torch.bfloat16.
Miso Labs claims 110ms latency. It lists ElevenLabs at 700ms and Sesame at 300ms.
The Vocabulary Size Problem
Standard transformers generate from a fixed vocabulary of discrete tokens. That works when a small vocabulary covers the target space. Human speech does not fit that assumption. It varies across pitch, rhythm, emphasis, emotion, and accent.
Expanding the audio vocabulary is the obvious fix. But larger vocabularies need more parameters in a standard transformer. Each token must be represented and predicted by the model. Miso Labs calls this the vocabulary size problem.
The second issue is conditioning. Most TTS models condition only on text. They ignore the interlocutor’s tone. Miso Labs argues this contributes to the “uncanny valley” effect.
Residual Vector Quantization: The Core Idea
MisoTTS addresses both problems with residual vector quantization (RVQ). Miso Labs traces RVQ to image-generation research and to Sesame’s CSM for audio. Instead of one token index, the model emits a vector of indices.
Each audio token is 32 codebook indices over 2048-way codebooks. The model keeps a separate codebook for each position in the vector. To recover the sound, it sums the looked-up vectors. Each codebook adds another refinement to the signal.
This is what makes the scaling work. Addressable vocabulary equals codebook size raised to the depth. Growing the depth adds no parameters to the model. So MisoTTS reaches about 204832, or roughly 10105 addressable tokens. Miso Labs notes naive scaling would require a far larger network.
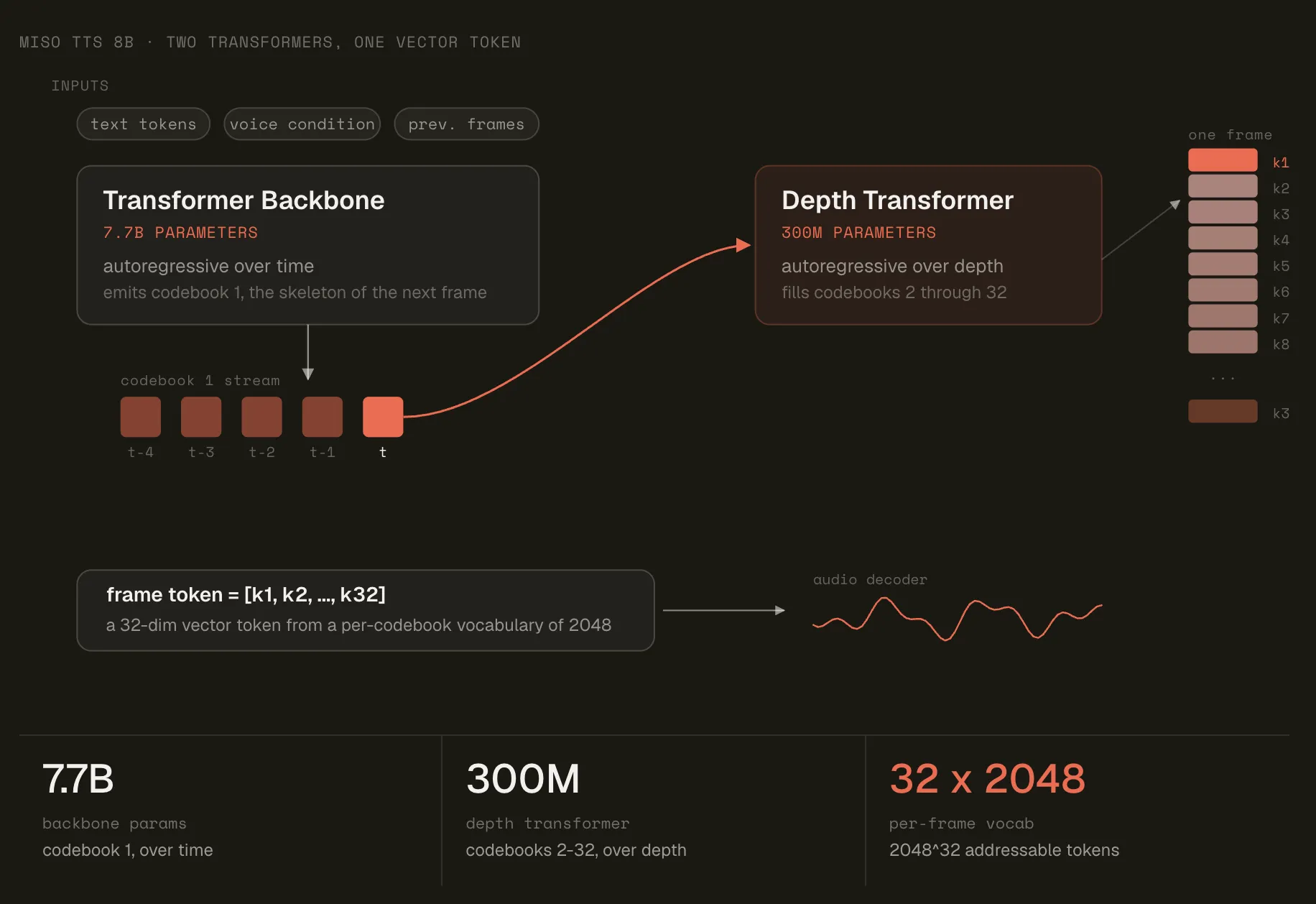
The Two-Transformer Architecture
The model splits into a backbone and a decoder. The backbone is a 7.7B-parameter transformer, autoregressive over time. It predicts the first codebook index and a final hidden state.
A 300M-parameter decoder then runs autoregressively over depth. It predicts the remaining codebook indices, one position at a time. Each prediction conditions on the indices already chosen in the frame. The same 300M parameters are reused for every position.
Embeddings follow the same logic. Text tokens use a single lookup. An audio token’s embedding is the sum of per-position codebook lookups. Interleaving text and audio lets the backbone use conversation history. That is how it carries context across turns.
Strengths and Challenges
Strengths:
- Open weights on day one, under a modified MIT license.
- RVQ scales the sonic range without scaling parameter count.
- Conditions on audio context, not text alone.
- Local deployment keeps sensitive audio data in-house.
- The architecture and math are documented in a public blog post.
Challenges:
- Half-duplex only, with no turn-taking yet.
- The large model needs a capable CUDA GPU.
- API access is announced but not yet available.
- Latency and quality claims still need third-party testing.
Marktechpost’s Visual Explainer
Marktechpost · Model Brief
01 / 09
Key Takeaways
- Miso Labs open-sourced MisoTTS, an 8B text-to-speech model, under a modified MIT license.
- It conditions on both text and audio context, making generations responsive to speaker tone.
- Residual vector quantization (32 codebooks × 2048-way) scales vocabulary to ~2048³² without adding parameters.
- Architecture splits a 7.7B backbone (over time) and a 300M decoder (over depth).
- It is half-duplex and single-turn only today; API access is still pending.
Check out the Model Weights, Repo and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us