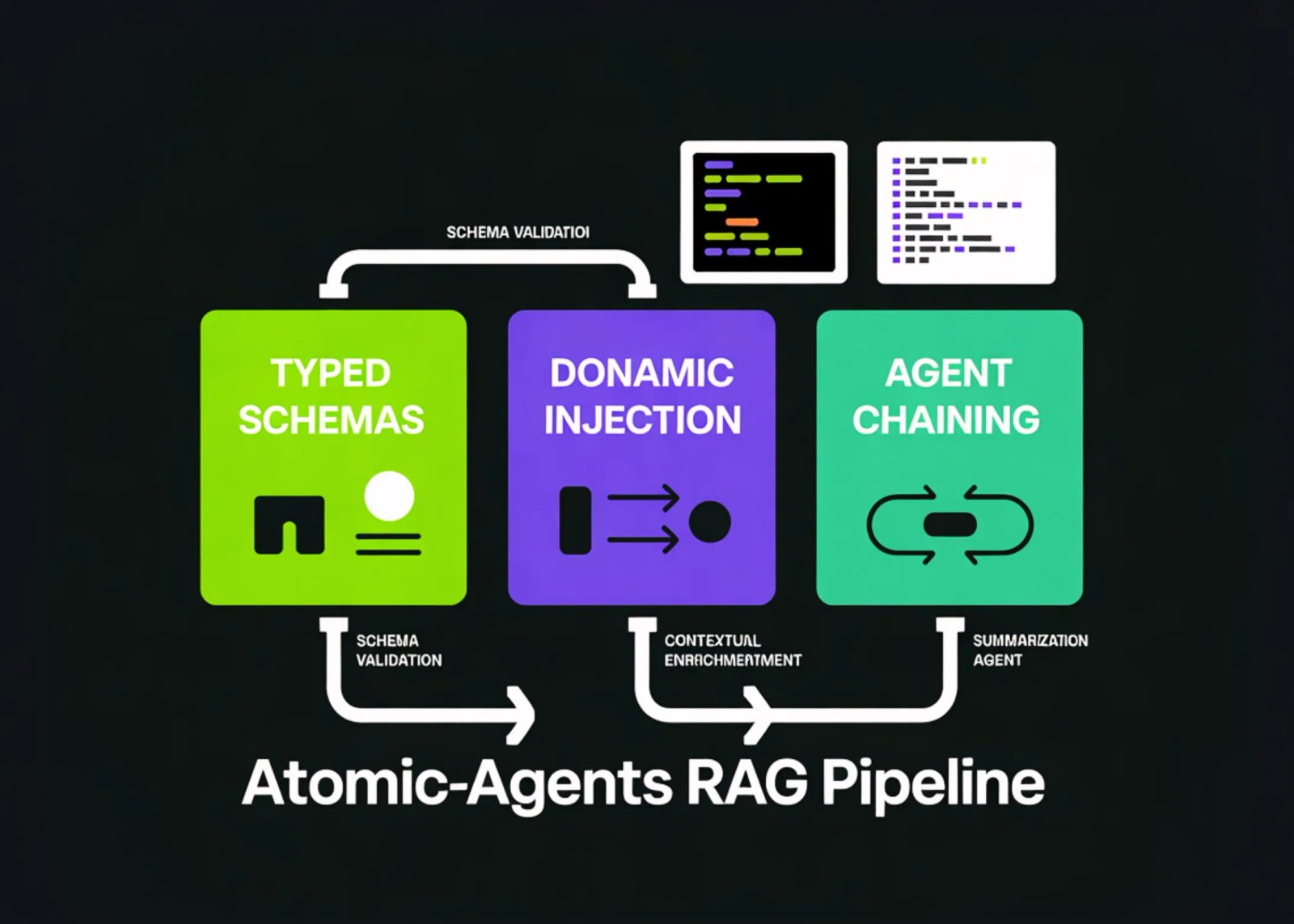
In this tutorial, we build an advanced, end-to-end learning pipeline around Atomic-Agents by wiring together typed agent interfaces, structured prompting, and a compact retrieval layer that grounds outputs in real project documentation. Also, we demonstrate how to plan retrieval, retrieve relevant context, inject it dynamically into an answering agent, and run an interactive loop that turns the setup into a reusable research assistant for any new Atomic Agents question. Check out the FULL CODES here.
import os, sys, textwrap, time, json, re
from typing import List, Optional, Dict, Tuple
from dataclasses import dataclass
import subprocess
subprocess.check_call([sys.executable, "-m", "pip", "install", "-q",
"atomic-agents", "instructor", "openai", "pydantic",
"requests", "beautifulsoup4", "scikit-learn"])
from getpass import getpass
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass("Enter OPENAI_API_KEY (input hidden): ").strip()
MODEL = os.environ.get("OPENAI_MODEL", "gpt-4o-mini")
from pydantic import Field
from openai import OpenAI
import instructor
from atomic_agents import AtomicAgent, AgentConfig, BaseIOSchema
from atomic_agents.context import SystemPromptGenerator, ChatHistory, BaseDynamicContextProvider
import requests
from bs4 import BeautifulSoupWe install all required packages, import the core Atomic-Agents primitives, and set up Colab-compatible dependencies in one place. We securely capture the OpenAI API key from the keyboard and store it in the environment so downstream code never hardcodes secrets. We also lock in a default model name while keeping it configurable via an environment variable.
def fetch_url_text(url: str, timeout: int = 20) -> str:
r = requests.get(url, timeout=timeout, headers={"User-Agent": "Mozilla/5.0"})
r.raise_for_status()
soup = BeautifulSoup(r.text, "html.parser")
for tag in soup(["script", "style", "nav", "header", "footer", "noscript"]):
tag.decompose()
text = soup.get_text("\n")
text = re.sub(r"[ \t]+", " ", text)
text = re.sub(r"\n{3,}", "\n\n", text).strip()
return text
def chunk_text(text: str, max_chars: int = 1400, overlap: int = 200) -> List[str]:
if not text:
return []
chunks = []
i = 0
while i < len(text):
chunk = text[i:i+max_chars].strip()
if chunk:
chunks.append(chunk)
i += max_chars - overlap
return chunks
def clamp(s: str, n: int = 800) -> str:
s = (s or "").strip()
return s if len(s) <= n else s[:n].rstrip() + "…"We fetch web pages from the Atomic Agents repo and docs, then clean them into plain text so retrieval becomes reliable. We chunk long documents into overlapping segments, preserving context while keeping each chunk small enough for ranking and citation. We also add a small helper to clamp long snippets so our injected context stays readable.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
@dataclass
class Snippet:
doc_id: str
url: str
chunk_id: int
text: str
score: float
class MiniCorpusRetriever:
def __init__(self, docs: Dict[str, Tuple[str, str]]):
self.items: List[Tuple[str, str, int, str]] = []
for doc_id, (url, raw) in docs.items():
for idx, ch in enumerate(chunk_text(raw)):
self.items.append((doc_id, url, idx, ch))
if not self.items:
raise RuntimeError("No documents were fetched; cannot build TF-IDF index.")
self.vectorizer = TfidfVectorizer(stop_words="english", max_features=50000)
self.matrix = self.vectorizer.fit_transform([it[3] for it in self.items])
def search(self, query: str, k: int = 6) -> List[Snippet]:
qv = self.vectorizer.transform([query])
sims = cosine_similarity(qv, self.matrix).ravel()
top = sims.argsort()[::-1][:k]
out = []
for j in top:
doc_id, url, chunk_id, txt = self.items[j]
out.append(Snippet(doc_id=doc_id, url=url, chunk_id=chunk_id, text=txt, score=float(sims[j])))
return out
class RetrievedContextProvider(BaseDynamicContextProvider):
def __init__(self, title: str, snippets: List[Snippet]):
super().__init__(title=title)
self.snippets = snippets
def get_info(self) -> str:
blocks = []
for s in self.snippets:
blocks.append(
f"[{s.doc_id}#{s.chunk_id}] (score={s.score:.3f}) {s.url}\n{clamp(s.text, 900)}"
)
return "\n\n".join(blocks)We build a mini retrieval system using TF-IDF and cosine similarity over the chunked documentation corpus. We wrap each retrieved chunk in a structured Snippet object to track doc IDs, chunk IDs, and citation scores. We then inject top-ranked chunks into the agent’s runtime via a dynamic context provider, keeping the answering agent grounded. Check out the FULL CODES here.
class PlanInput(BaseIOSchema):
"""Input schema for the planner agent: describes the user's task and how many retrieval queries to draft."""
task: str = Field(...)
num_queries: int = Field(4)
class PlanOutput(BaseIOSchema):
"""Output schema from the planner agent: retrieval queries, coverage checklist, and safety checks."""
queries: List[str]
must_cover: List[str]
safety_checks: List[str]
class AnswerInput(BaseIOSchema):
"""Input schema for the answering agent: user question plus style constraints."""
question: str
style: str = "concise but advanced"
class AnswerOutput(BaseIOSchema):
"""Output schema for the answering agent: grounded answer, next steps, and which citations were used."""
answer: str
next_steps: List[str]
used_citations: List[str]
client = instructor.from_openai(OpenAI(api_key=os.environ["OPENAI_API_KEY"]))
planner_prompt = SystemPromptGenerator(
background=[
"You are a rigorous research planner for a small RAG system.",
"You propose retrieval queries that are diverse (lexical + semantic) and designed to find authoritative info.",
"You do NOT answer the task; you only plan retrieval."
],
steps=[
"Read the task.",
"Propose diverse retrieval queries (not too long).",
"List must-cover aspects and safety checks."
],
output_instructions=[
"Return strictly the PlanOutput schema.",
"Queries must be directly usable as search strings.",
"Must-cover should be 4–8 bullets."
]
)
planner = AtomicAgent[PlanInput, PlanOutput](
config=AgentConfig(
client=client,
model=MODEL,
system_prompt_generator=planner_prompt,
history=ChatHistory(),
)
)
answerer_prompt = SystemPromptGenerator(
background=[
"You are an expert technical tutor for Atomic Agents (atomic-agents).",
"You are given retrieved context snippets with IDs like [doc#chunk].",
"You must ground claims in the provided snippets and cite them inline."
],
steps=[
"Read the question and the provided context.",
"Synthesize an accurate answer using only supported facts.",
"Cite claims inline using the provided snippet IDs."
],
output_instructions=[
"Use inline citations like [readme#12] or [docs_home#3].",
"If the context does not support something, say so briefly and suggest what to retrieve next.",
"Return strictly the AnswerOutput schema."
]
)
answerer = AtomicAgent[AnswerInput, AnswerOutput](
config=AgentConfig(
client=client,
model=MODEL,
system_prompt_generator=answerer_prompt,
history=ChatHistory(),
)
)
We define strict-typed schemas for planner and answerer inputs and outputs, and include docstrings to satisfy Atomic Agents’ schema requirements. We create an Instructor-wrapped OpenAI client and configure two Atomic Agents with explicit system prompts and chat history. We enforce structured outputs so the planner produces queries and the answerer produces a cited response with clear next steps.
SOURCES = {
"readme": "https://github.com/BrainBlend-AI/atomic-agents",
"docs_home": "https://brainblend-ai.github.io/atomic-agents/",
"examples_index": "https://brainblend-ai.github.io/atomic-agents/examples/index.html",
}
raw_docs: Dict[str, Tuple[str, str]] = {}
for doc_id, url in SOURCES.items():
try:
raw_docs[doc_id] = (url, fetch_url_text(url))
except Exception:
raw_docs[doc_id] = (url, "")
non_empty = [d for d in raw_docs.values() if d[1].strip()]
if not non_empty:
raise RuntimeError("All source fetches failed or were empty. Check network access in Colab and retry.")
retriever = MiniCorpusRetriever(raw_docs)
def run_atomic_rag(question: str, k: int = 7, verbose: bool = True) -> AnswerOutput:
t0 = time.time()
plan = planner.run(PlanInput(task=question, num_queries=4))
all_snips: List[Snippet] = []
for q in plan.queries:
all_snips.extend(retriever.search(q, k=max(2, k // 2)))
best: Dict[Tuple[str, int], Snippet] = {}
for s in all_snips:
key = (s.doc_id, s.chunk_id)
if (key not in best) or (s.score > best[key].score):
best[key] = s
snips = sorted(best.values(), key=lambda x: x.score, reverse=True)[:k]
ctx = RetrievedContextProvider(title="Retrieved Atomic Agents Context", snippets=snips)
answerer.register_context_provider("retrieved_context", ctx)
out = answerer.run(AnswerInput(question=question, style="concise, advanced, practical"))
if verbose:
print(out.answer)
return out
demo_q = "Teach me Atomic Agents at an advanced level: explain the core building blocks and show how to chain agents with typed schemas and dynamic context."
run_atomic_rag(demo_q, k=7, verbose=True)
while True:
user_q = input("\nYour question> ").strip()
if not user_q or user_q.lower() in {"exit", "quit"}:
break
run_atomic_rag(user_q, k=7, verbose=True)We fetch a small set of authoritative Atomic Agents sources and build a local retrieval index from them. We implement a full pipeline function that plans queries, retrieves relevant context, injects it, and produces a grounded final answer. We finish by running a demo query and launching an interactive loop so we can keep asking questions and getting cited answers.
In conclusion, we completed the Atomic-Agents workflow in Colab, cleanly separating planning, retrieval, answering, and ensuring strong typing. We kept the system grounded by injecting only the highest-signal documentation chunks as dynamic context, and we enforced a citation discipline that makes outputs auditable. From here, we can scale this pattern by adding more sources, swapping in stronger retrievers or rerankers, introducing tool-use agents, and turning the pipeline into a production-grade research assistant that remains both fast and trustworthy.
Check out the FULL CODES here. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.