Transformers use attention and Mixture-of-Experts to scale computation, but they still lack a native way to perform knowledge lookup. They re-compute the same local patterns again and again, which wastes depth and FLOPs. DeepSeek’s new Engram module targets exactly this gap by adding a conditional memory axis that works alongside MoE rather than replacing it.
At a high level, Engram modernizes classic N gram embeddings and turns them into a scalable, O(1) lookup memory that plugs directly into the Transformer backbone. The result is a parametric memory that stores static patterns such as common phrases and entities, while the backbone focuses on harder reasoning and long range interactions.
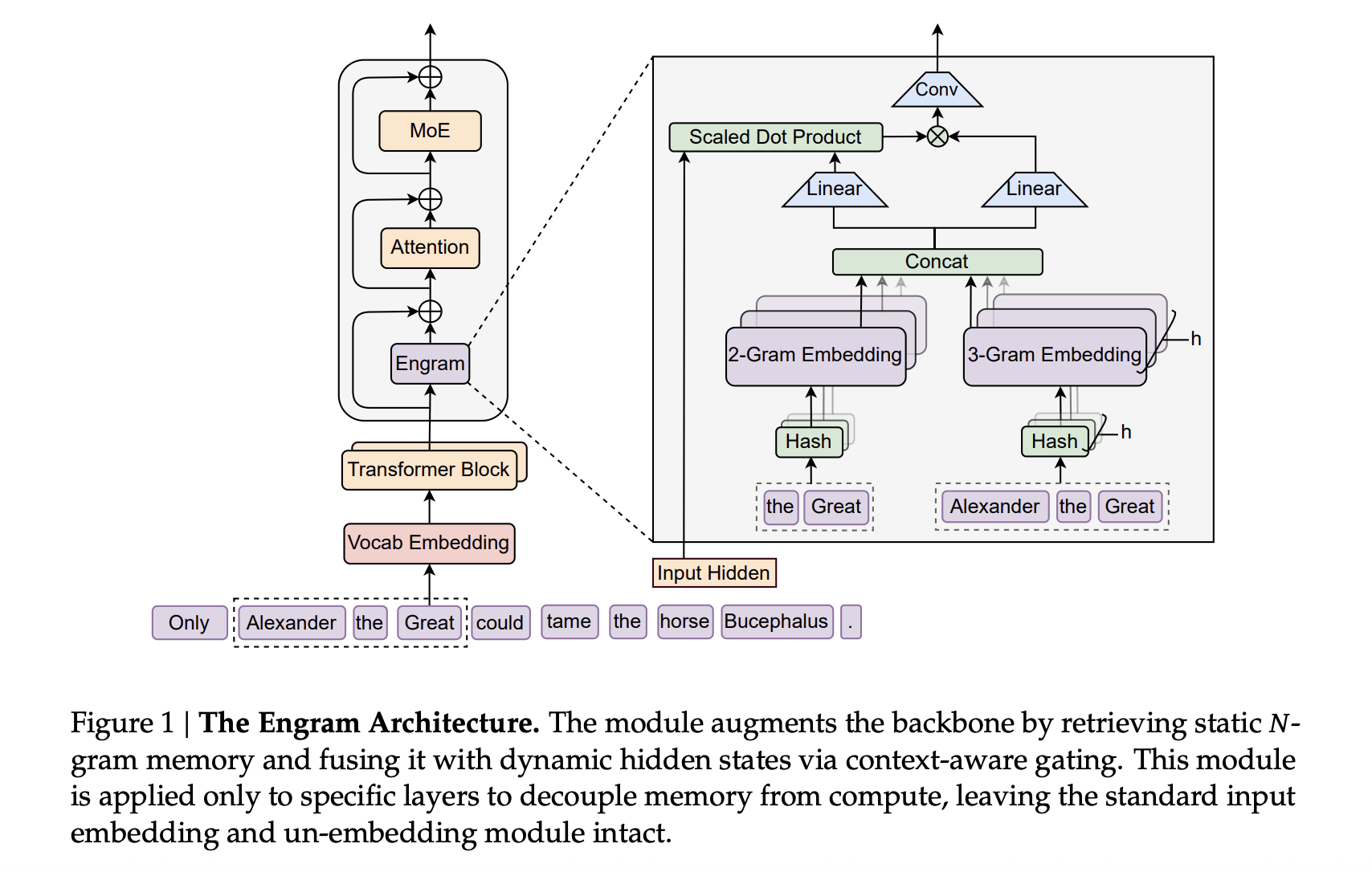
How Engram Fits Into A DeepSeek Transformer
The proposed approach use the DeepSeek V3 tokenizer with a 128k vocabulary and pre-train on 262B tokens. The backbone is a 30 block Transformer with hidden size 2560. Each block uses Multi head Latent Attention with 32 heads and connects to feed forward networks through Manifold Constrained Hyper Connections with expansion rate 4. Optimization uses the Muon optimizer.
Engram attaches to this backbone as a sparse embedding module. It is built from hashed N gram tables, with multi head hashing into prime sized buckets, a small depthwise convolution over the N gram context and a context aware gating scalar in the range 0 to 1 that controls how much of the retrieved embedding is injected into each branch.
In the large scale models, Engram-27B and Engram-40B share the same Transformer backbone as MoE-27B. MoE-27B replaces the dense feed forward with DeepSeekMoE, using 72 routed experts and 2 shared experts. Engram-27B reduces routed experts from 72 to 55 and reallocates those parameters into a 5.7B Engram memory while keeping total parameters at 26.7B. The Engram module uses N equal to {2,3}, 8 Engram heads, dimension 1280 and is inserted at layers 2 and 15. Engram 40B increases the Engram memory to 18.5B parameters while keeping activated parameters fixed.
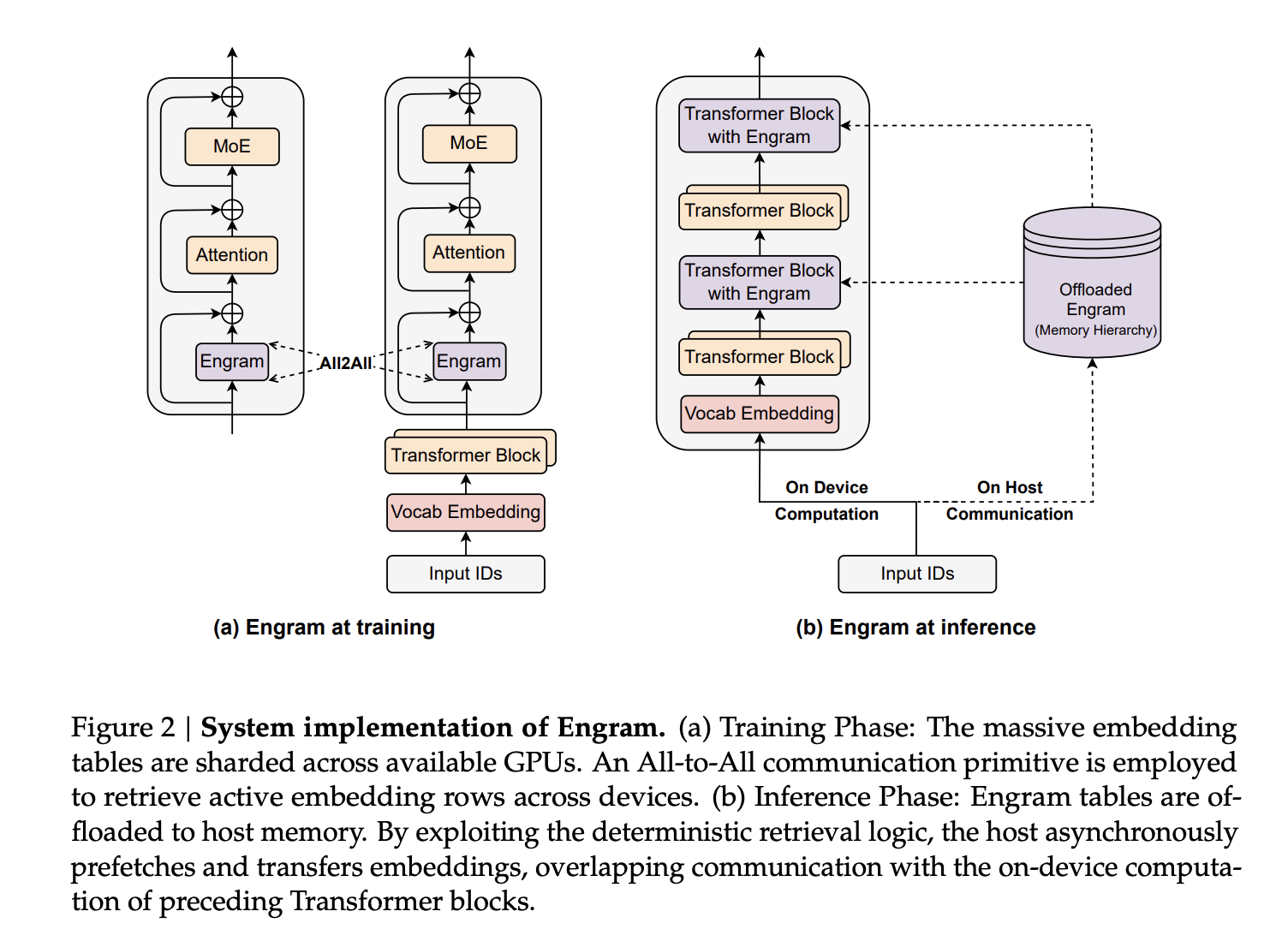
Sparsity Allocation, A Second Scaling Knob Beside MoE
The core design question is how to split the sparse parameter budget between routed experts and conditional memory. The research team formalize this as the Sparsity Allocation problem, with allocation ratio ρ defined as the fraction of inactive parameters assigned to MoE experts. A pure MoE model has ρ equal to 1. Reducing ρ reallocates parameters from experts into Engram slots.
On mid scale 5.7B and 9.9B models, sweeping ρ gives a clear U shaped curve of validation loss versus allocation ratio. Engram models match the pure MoE baseline even when ρ drops to about 0.25, which corresponds to roughly half as many routed experts. The optimum appears when around 20 to 25 percent of the sparse budget is given to Engram. This optimum is stable across both compute regimes, which suggests a robust split between conditional computation and conditional memory under fixed sparsity.
The research team also studied an infinite memory regime on a fixed 3B MoE backbone trained for 100B tokens. They scale the Engram table from roughly 2.58e5 to 1e7 slots. Validation loss follows an almost perfect power law in log space, meaning that more conditional memory keeps paying off without extra compute. Engram also outperforms OverEncoding, another N gram embedding method that averages into the vocabulary embedding, under the same memory budget.
Large Scale Pre Training Results
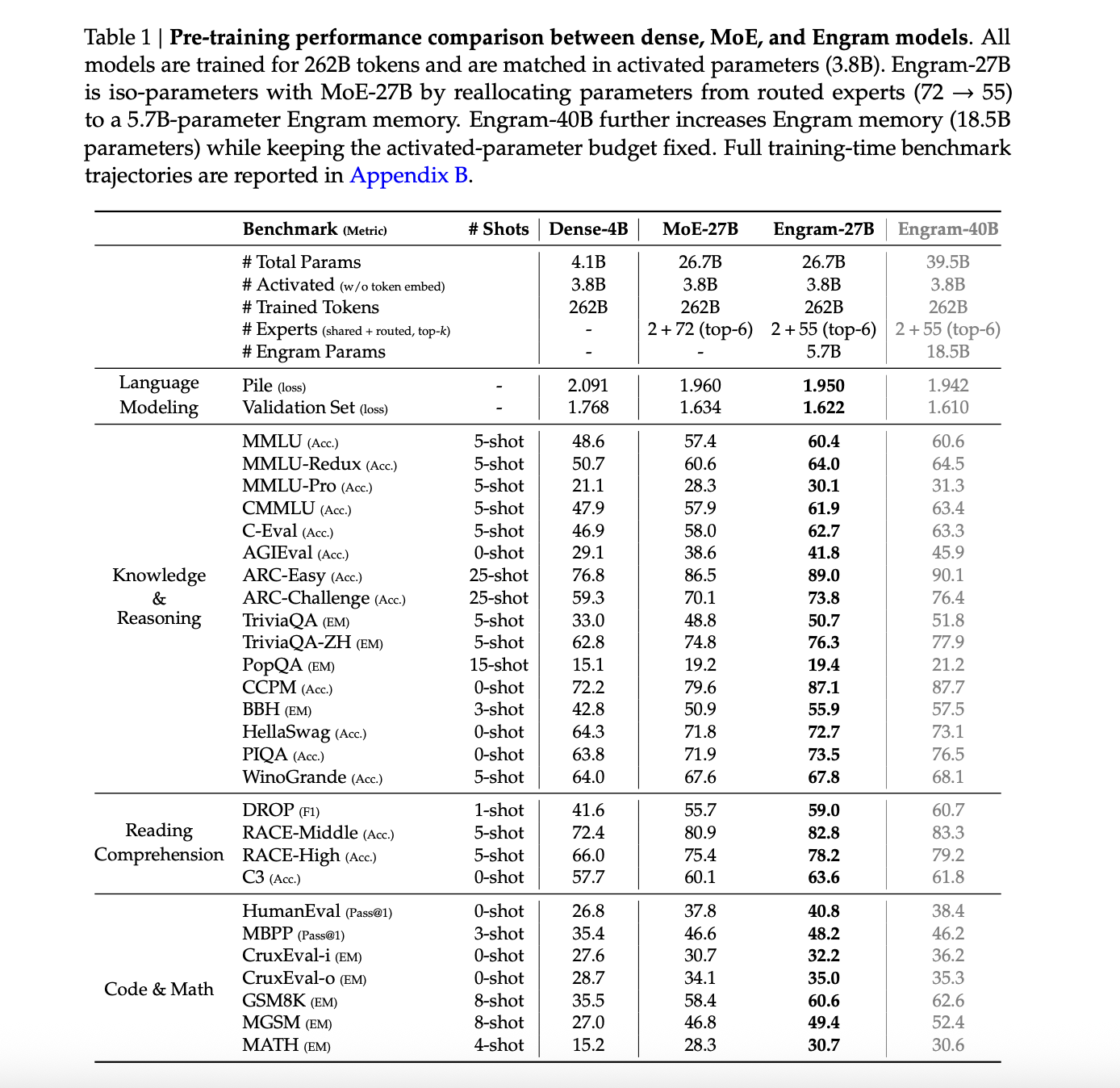
The main comparison involves four models trained on the same 262B token curriculum, with 3.8B activated parameters in all cases. These are Dense 4B with 4.1B total parameters, MoE 27B and Engram 27B at 26.7B total parameters, and Engram 40B at 39.5B total parameters.
On The Pile test set, language modeling loss is 2.091 for MoE 27B, 1.960 for Engram 27B, 1.950 for the Engram 27B variant and 1.942 for Engram 40B. The Dense 4B Pile loss is not reported. Validation loss on the internal held out set drops from 1.768 for MoE 27B to 1.634 for Engram 27B and to 1.622 and 1.610 for the Engram variants.
Across knowledge and reasoning benchmarks, Engram-27B consistently improves over MoE-27B. MMLU increases from 57.4 to 60.4, CMMLU from 57.9 to 61.9 and C-Eval from 58.0 to 62.7. ARC Challenge rises from 70.1 to 73.8, BBH from 50.9 to 55.9 and DROP F1 from 55.7 to 59.0. Code and math tasks also improve, for example HumanEval from 37.8 to 40.8 and GSM8K from 58.4 to 60.6.
Engram 40B typically pushes these numbers further even though the authors note that it is likely under trained at 262B tokens because its training loss continues to diverge from the baselines near the end of pre training.
Long Context Behavior And Mechanistic Effects
After pre-training, the research team extend the context window using YaRN to 32768 tokens for 5000 steps, using 30B high quality long context tokens. They compare MoE-27B and Engram-27B at checkpoints corresponding to 41k, 46k and 50k pre training steps.
On LongPPL and RULER at 32k context, Engram-27B matches or exceeds MoE-27B under three conditions. With about 82 percent of the pre training FLOPs, Engram-27B at 41k steps matches LongPPL while improving RULER accuracy, for example Multi Query NIAH 99.6 versus 73.0 and QA 44.0 versus 34.5. Under iso loss at 46k and iso FLOPs at 50k, Engram 27B improves both perplexity and all RULER categories including VT and QA.
Mechanistic analysis uses LogitLens and Centered Kernel Alignment. Engram variants show lower layer wise KL divergence between intermediate logits and the final prediction, especially in early blocks, which means representations become prediction ready sooner. CKA similarity maps show that shallow Engram layers align best with much deeper MoE layers. For example, layer 5 in Engram-27B aligns with around layer 12 in the MoE baseline. Taken together, this supports the view that Engram effectively increases model depth by offloading static reconstruction to memory.
Ablation studies on a 12 layer 3B MoE model with 0.56B activated parameters add a 1.6B Engram memory as a reference configuration, using N equal to {2,3} and inserting Engram at layers 2 and 6. Sweeping a single Engram layer across depth shows that early insertion at layer 2 is optimal. The component ablations highlight three key pieces, multi branch integration, context aware gating and tokenizer compression.
Sensitivity analysis shows that factual knowledge relies heavily on Engram, with TriviaQA dropping to about 29 percent of its original score when Engram outputs are suppressed at inference, while reading comprehension tasks retain around 81 to 93 percent of performance, for example C3 at 93 percent.
Key Takeaways
- Engram adds a conditional memory axis to sparse LLMs so that frequent N gram patterns and entities are retrieved via O(1) hashed lookup, while the Transformer backbone and MoE experts focus on dynamic reasoning and long range dependencies.
- Under a fixed parameter and FLOPs budget, reallocating about 20 to 25 percent of the sparse capacity from MoE experts into Engram memory lowers validation loss, showing that conditional memory and conditional computation are complementary rather than competing.
- In large scale pre training on 262B tokens, Engram-27B and Engram-40B with the same 3.8B activated parameters outperform a MoE-27B baseline on language modeling, knowledge, reasoning, code and math benchmarks, while keeping the Transformer backbone architecture unchanged.
- Long context extension to 32768 tokens using YaRN shows that Engram-27B matches or improves LongPPL and clearly improves RULER scores, especially Multi-Query-Needle in a Haystack and variable tracking, even when trained with lower or equal compute compared to MoE-27B.
Check out the Paper and GitHub Repo. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Check out our latest release of ai2025.dev, a 2025-focused analytics platform that turns model launches, benchmarks, and ecosystem activity into a structured dataset you can filter, compare, and export.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.