
In this tutorial, we walk through the complete implementation of an advanced AI agent system powered by Nomic Embeddings and Google’s Gemini. We design the architecture from the ground up, integrating semantic memory, contextual reasoning, and multi-agent orchestration into a single intelligent framework. Using LangChain, Faiss, and LangChain-Nomic, we equip our agents with the ability to store, retrieve, and reason over information using natural language queries. The goal is to demonstrate how we can build a modular and extensible AI system that supports both analytical research and friendly conversation.
!pip install -qU langchain-nomic langchain-core langchain-community langchain-google-genai faiss-cpu numpy matplotlib
import os
import getpass
import numpy as np
from typing import List, Dict, Any, Optional
from dataclasses import dataclass
from langchain_nomic import NomicEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_core.documents import Document
from langchain_google_genai import ChatGoogleGenerativeAI
import json
if not os.getenv("NOMIC_API_KEY"):
os.environ["NOMIC_API_KEY"] = getpass.getpass("Enter your Nomic API key: ")
if not os.getenv("GOOGLE_API_KEY"):
os.environ["GOOGLE_API_KEY"] = getpass.getpass("Enter your Google API key (for Gemini): ")
We begin by installing all the required libraries, including langchain-nomic, langchain-google-genai, and faiss-cpu, to support our agent’s embedding, reasoning, and vector search capabilities. We then import the necessary modules and securely set our Nomic and Google API keys using getpass to ensure smooth integration with the embedding and LLM services. Check out the full Codes.
@dataclass
class AgentMemory:
"""Agent's episodic and semantic memory"""
episodic: List[Dict[str, Any]]
semantic: Dict[str, Any]
working: Dict[str, Any]
class IntelligentAgent:
"""Advanced AI Agent with Nomic Embeddings for semantic reasoning"""
def __init__(self, agent_name: str = "AIAgent", personality: str = "helpful"):
self.name = agent_name
self.personality = personality
self.embeddings = NomicEmbeddings(
model="nomic-embed-text-v1.5",
dimensionality=384,
inference_mode="remote"
)
self.llm = ChatGoogleGenerativeAI(
model="gemini-1.5-flash",
temperature=0.7,
max_tokens=512
)
self.memory = AgentMemory(
episodic=[],
semantic={},
working={}
)
self.knowledge_base = None
self.vector_store = None
self.capabilities = {
"reasoning": True,
"memory_retrieval": True,
"knowledge_search": True,
"context_awareness": True,
"learning": True
}
print(f"🤖 {self.name} initialized with Nomic embeddings + Gemini LLM")
def add_knowledge(self, documents: List[str], metadata: List[Dict] = None):
"""Add knowledge to agent's semantic memory"""
if metadata is None:
metadata = [{"source": f"doc_{i}"} for i in range(len(documents))]
docs = [Document(page_content=doc, metadata=meta)
for doc, meta in zip(documents, metadata)]
if self.vector_store is None:
self.vector_store = InMemoryVectorStore.from_documents(docs, self.embeddings)
else:
self.vector_store.add_documents(docs)
print(f"📚 Added {len(documents)} documents to knowledge base")
def remember_interaction(self, user_input: str, agent_response: str, context: Dict = None):
"""Store interaction in episodic memory"""
memory_entry = {
"timestamp": len(self.memory.episodic),
"user_input": user_input,
"agent_response": agent_response,
"context": context or {},
"embedding": self.embeddings.embed_query(f"{user_input} {agent_response}")
}
self.memory.episodic.append(memory_entry)
def retrieve_similar_memories(self, query: str, k: int = 3) -> List[Dict]:
"""Retrieve similar past interactions"""
if not self.memory.episodic:
return []
query_embedding = self.embeddings.embed_query(query)
similarities = []
for memory in self.memory.episodic:
similarity = np.dot(query_embedding, memory["embedding"])
similarities.append((similarity, memory))
similarities.sort(reverse=True, key=lambda x: x[0])
return [mem for _, mem in similarities[:k]]
def search_knowledge(self, query: str, k: int = 3) -> List[Document]:
"""Search knowledge base for relevant information"""
if self.vector_store is None:
return []
return self.vector_store.similarity_search(query, k=k)
def reason_and_respond(self, user_input: str) -> str:
"""Main reasoning pipeline with context integration"""
similar_memories = self.retrieve_similar_memories(user_input, k=2)
relevant_docs = self.search_knowledge(user_input, k=3)
context = {
"similar_memories": similar_memories,
"relevant_knowledge": [doc.page_content for doc in relevant_docs],
"working_memory": self.memory.working
}
response = self._generate_contextual_response(user_input, context)
self.remember_interaction(user_input, response, context)
self.memory.working["last_query"] = user_input
self.memory.working["last_response"] = response
return response
def _generate_contextual_response(self, query: str, context: Dict) -> str:
"""Generate response using Gemini LLM with context"""
context_info = ""
if context["relevant_knowledge"]:
context_info += f"Relevant Knowledge: {' '.join(context['relevant_knowledge'][:2])}\n"
if context["similar_memories"]:
memory = context["similar_memories"][0]
context_info += f"Similar Past Interaction: User asked '{memory['user_input']}', I responded '{memory['agent_response'][:100]}...'\n"
prompt = f"""You are {self.name}, an AI agent with personality: {self.personality}.
Context Information:
{context_info}
User Query: {query}
Please provide a helpful response based on the context. Keep it concise (under 150 words) and maintain your personality."""
try:
response = self.llm.invoke(prompt)
return response.content.strip()
except Exception as e:
if context["relevant_knowledge"]:
knowledge_summary = " ".join(context["relevant_knowledge"][:2])
return f"Based on my knowledge: {knowledge_summary[:200]}..."
elif context["similar_memories"]:
last_memory = context["similar_memories"][0]
return f"I recall a similar question. Previously: {last_memory['agent_response'][:150]}..."
else:
return "I need more information to provide a comprehensive answer."We define the core structure of our intelligent agent by creating a memory system that mimics episodic and semantic recall. We integrate Nomic embeddings for semantic understanding and use Gemini LLM to generate contextual, personality-driven responses. With built-in capabilities like memory retrieval, knowledge search, and reasoning, we enable the agent to interact intelligently and learn from each conversation. Check out the full Codes.
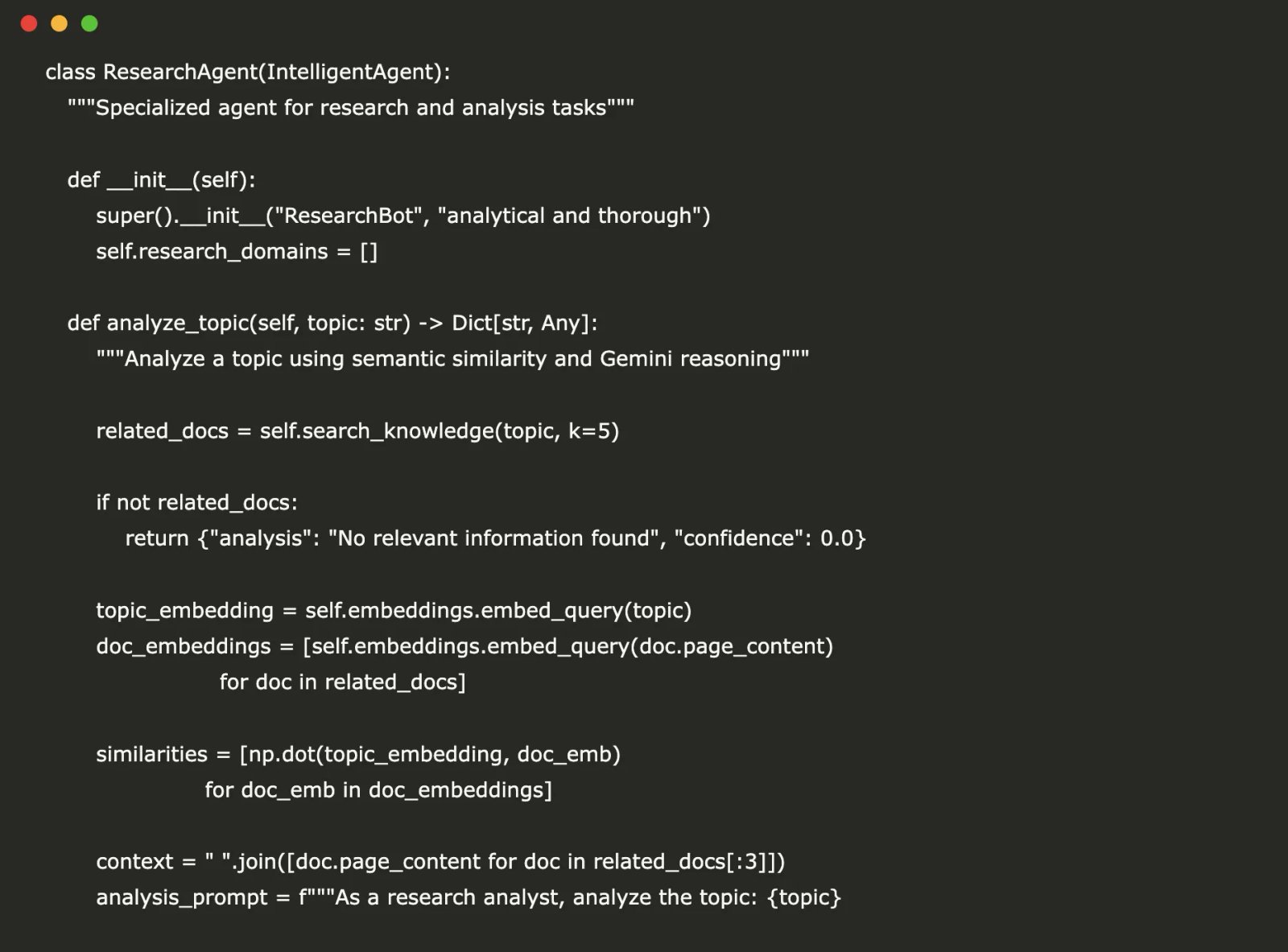
class ResearchAgent(IntelligentAgent):
"""Specialized agent for research and analysis tasks"""
def __init__(self):
super().__init__("ResearchBot", "analytical and thorough")
self.research_domains = []
def analyze_topic(self, topic: str) -> Dict[str, Any]:
"""Analyze a topic using semantic similarity and Gemini reasoning"""
related_docs = self.search_knowledge(topic, k=5)
if not related_docs:
return {"analysis": "No relevant information found", "confidence": 0.0}
topic_embedding = self.embeddings.embed_query(topic)
doc_embeddings = [self.embeddings.embed_query(doc.page_content)
for doc in related_docs]
similarities = [np.dot(topic_embedding, doc_emb)
for doc_emb in doc_embeddings]
context = " ".join([doc.page_content for doc in related_docs[:3]])
analysis_prompt = f"""As a research analyst, analyze the topic: {topic}
Available information:
{context}
Provide a structured analysis including:
1. Key insights (2-3 points)
2. Confidence level assessment
3. Research gaps or limitations
4. Practical implications
Keep response under 200 words."""
try:
gemini_analysis = self.llm.invoke(analysis_prompt)
detailed_analysis = gemini_analysis.content.strip()
except:
detailed_analysis = f"Analysis of {topic} based on available documents with {len(related_docs)} relevant sources."
analysis = {
"topic": topic,
"related_documents": len(related_docs),
"max_similarity": max(similarities),
"avg_similarity": np.mean(similarities),
"key_insights": [doc.page_content[:100] + "..." for doc in related_docs[:3]],
"confidence": max(similarities),
"detailed_analysis": detailed_analysis
}
return analysis
class ConversationalAgent(IntelligentAgent):
"""Agent optimized for natural conversations"""
def __init__(self):
super().__init__("ChatBot", "friendly and engaging")
self.conversation_history = []
def maintain_conversation_context(self, user_input: str) -> str:
"""Maintain conversation flow with context awareness"""
self.conversation_history.append({"role": "user", "content": user_input})
recent_context = " ".join([msg["content"] for msg in self.conversation_history[-3:]])
response = self.reason_and_respond(recent_context)
self.conversation_history.append({"role": "assistant", "content": response})
return responseWe extend our intelligent agent into two specialized versions: a ResearchAgent for structured topic analysis and a ConversationalAgent for natural dialogue. The research agent leverages semantic similarity and Gemini LLM to generate confident, insight-rich analyses, while the conversational agent maintains a history-aware chat experience that feels coherent and engaging. This modular design enables us to tailor AI behaviors to meet specific user needs. Check out the full Codes.
def demonstrate_agent_capabilities():
"""Comprehensive demonstration of agent capabilities"""
print("🎯 Creating and testing AI agents...")
research_agent = ResearchAgent()
chat_agent = ConversationalAgent()
knowledge_documents = [
"Artificial intelligence is transforming industries through automation and intelligent decision-making systems.",
"Machine learning algorithms require large datasets to identify patterns and make predictions.",
"Natural language processing enables computers to understand and generate human language.",
"Computer vision allows machines to interpret and analyze visual information from images and videos.",
"Robotics combines AI with physical systems to create autonomous machines.",
"Deep learning uses neural networks with multiple layers to solve complex problems.",
"Reinforcement learning teaches agents to make decisions through trial and error.",
"Quantum computing promises to solve certain problems exponentially faster than classical computers."
]
research_agent.add_knowledge(knowledge_documents)
chat_agent.add_knowledge(knowledge_documents)
print("\n🔬 Testing Research Agent...")
topics = ["machine learning", "robotics", "quantum computing"]
for topic in topics:
analysis = research_agent.analyze_topic(topic)
print(f"\n📊 Analysis of '{topic}':")
print(f" Confidence: {analysis['confidence']:.3f}")
print(f" Related docs: {analysis['related_documents']}")
print(f" Detailed Analysis: {analysis.get('detailed_analysis', 'N/A')[:200]}...")
print(f" Key insight: {analysis['key_insights'][0] if analysis['key_insights'] else 'None'}")
print("\n💬 Testing Conversational Agent...")
conversation_inputs = [
"Tell me about artificial intelligence",
"How does machine learning work?",
"What's the difference between AI and machine learning?",
"Can you explain neural networks?"
]
for user_input in conversation_inputs:
response = chat_agent.maintain_conversation_context(user_input)
print(f"\n👤 User: {user_input}")
print(f"🤖 Agent: {response}")
print("\n🧠 Memory Analysis...")
print(f"Research Agent memories: {len(research_agent.memory.episodic)}")
print(f"Chat Agent memories: {len(chat_agent.memory.episodic)}")
similar_memories = chat_agent.retrieve_similar_memories("artificial intelligence", k=2)
if similar_memories:
print(f"\n🔍 Similar memory found:")
print(f" Query: {similar_memories[0]['user_input']}")
print(f" Response: {similar_memories[0]['agent_response'][:100]}...")We run a comprehensive demonstration of our AI agents by loading a shared knowledge base and evaluating both research and conversational tasks. We test the ResearchAgent’s ability to generate insightful analyses on key topics and validate the ConversationalAgent’s performance across multi-turn queries. Through introspection, we confirm that the agents effectively retain and retrieve relevant past interactions. Check out the full Codes.
class MultiAgentSystem:
"""Orchestrate multiple specialized agents"""
def __init__(self):
self.agents = {
"research": ResearchAgent(),
"chat": ConversationalAgent()
}
self.coordinator_embeddings = NomicEmbeddings(model="nomic-embed-text-v1.5", dimensionality=256)
def route_query(self, query: str) -> str:
"""Route query to most appropriate agent"""
agent_descriptions = {
"research": "analysis, research, data, statistics, technical information",
"chat": "conversation, questions, general discussion, casual talk"
}
query_embedding = self.coordinator_embeddings.embed_query(query)
best_agent = "chat"
best_similarity = 0
for agent_name, description in agent_descriptions.items():
desc_embedding = self.coordinator_embeddings.embed_query(description)
similarity = np.dot(query_embedding, desc_embedding)
if similarity > best_similarity:
best_similarity = similarity
best_agent = agent_name
return best_agent
def process_query(self, query: str) -> Dict[str, Any]:
"""Process query through appropriate agent"""
selected_agent, confidence = self.route_query_with_confidence(query)
agent = self.agents[selected_agent]
if selected_agent == "research":
if "analyze" in query.lower() or "research" in query.lower():
topic = query.replace("analyze", "").replace("research", "").strip()
result = agent.analyze_topic(topic)
response = f"Research Analysis: {result.get('detailed_analysis', str(result))}"
else:
response = agent.reason_and_respond(query)
else:
response = agent.maintain_conversation_context(query)
return {
"query": query,
"selected_agent": selected_agent,
"response": response,
"confidence": confidence
}
def route_query_with_confidence(self, query: str) -> tuple[str, float]:
"""Route query to most appropriate agent and return confidence"""
agent_descriptions = {
"research": "analysis, research, data, statistics, technical information",
"chat": "conversation, questions, general discussion, casual talk"
}
query_embedding = self.coordinator_embeddings.embed_query(query)
best_agent = "chat"
best_similarity = 0.0
for agent_name, description in agent_descriptions.items():
desc_embedding = self.coordinator_embeddings.embed_query(description)
similarity = np.dot(query_embedding, desc_embedding)
if similarity > best_similarity:
best_similarity = similarity
best_agent = agent_name
return best_agent, best_similarityWe built a multi-agent system that intelligently routes queries to either the research or conversational agent based on semantic similarity. By embedding both the user query and agent specialties using Nomic embeddings, we ensure that the most relevant expert is assigned to each request. This architecture allows us to scale intelligent behavior while maintaining specialization and precision. Check out the full Codes.
if __name__ == "__main__":
print("\n🚀 Advanced AI Agent System with Nomic Embeddings + Gemini LLM")
print("=" * 70)
print("💡 Note: This uses Google's Gemini 1.5 Flash (free tier) for reasoning")
print("📚 Get your free Google API key at: https://makersuite.google.com/app/apikey")
print("🎯 Get your Nomic API key at: https://atlas.nomic.ai/")
print("=" * 70)
demonstrate_agent_capabilities()
print("\n🎛️ Testing Multi-Agent System...")
multi_system = MultiAgentSystem()
knowledge_docs = [
"Python is a versatile programming language used in AI development.",
"TensorFlow and PyTorch are popular machine learning frameworks.",
"Data preprocessing is crucial for successful machine learning projects."
]
for agent in multi_system.agents.values():
agent.add_knowledge(knowledge_docs)
test_queries = [
"Analyze the impact of AI on society",
"How are you doing today?",
"Research machine learning trends",
"What's your favorite color?"
]
for query in test_queries:
result = multi_system.process_query(query)
print(f"\n📝 Query: {query}")
print(f"🎯 Routed to: {result['selected_agent']} agent")
print(f"💬 Response: {result['response'][:150]}...")
print("\n✅ Advanced AI Agent demonstration complete!")We conclude by running a comprehensive demonstration of our AI system, initializing the agents, loading knowledge, and testing real-world queries. We observe how the multi-agent system intelligently routes each query based on its content, showcasing the strength of our modular design. This final execution confirms the agents’ capabilities in reasoning, memory, and adaptive response generation.
In conclusion, we now have a powerful and flexible AI agent framework that leverages Nomic embeddings for semantic understanding and Gemini LLM for contextual response generation. We demonstrate how agents can independently manage memory, retrieve knowledge, and reason intelligently, while the multi-agent system ensures that user queries are routed to the most capable agent. By walking through both research-focused and conversational interactions, we showcase how this setup can serve as a foundation for building truly intelligent and responsive AI assistants.
Check out the Codes. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.