What is catastrophic forgetting in foundation models?
Foundation models excel in diverse domains but are largely static once deployed. Fine-tuning on new tasks often introduces catastrophic forgetting—the loss of previously learned capabilities. This limitation poses a barrier for building long-lived, continually improving AI agents.
Why does online reinforcement learning forget less than supervised fine-tuning?
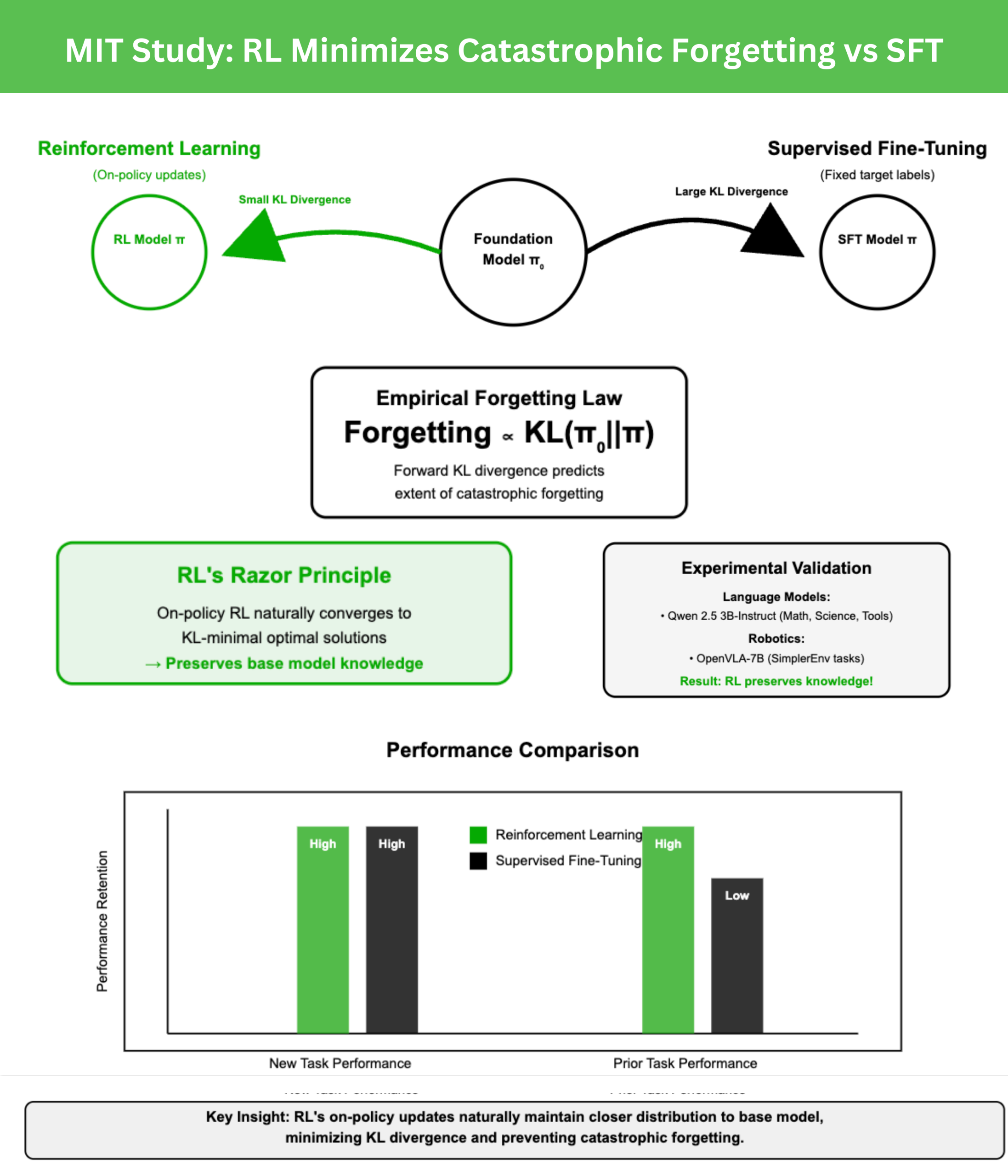
A new MIT study compares reinforcement learning (RL) and supervised fine-tuning (SFT). Both can achieve high performance on new tasks, but SFT tends to overwrite prior abilities. RL, by contrast, preserves them. The key lies in how each method shifts the model’s output distribution relative to the base policy.
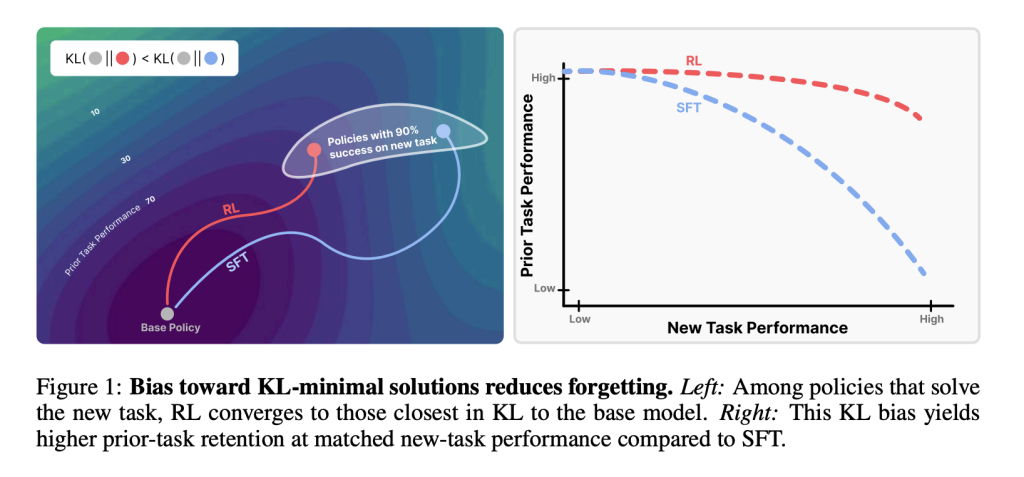
How can forgetting be measured?
The research team proposes an empirical forgetting law:
Forgetting∝KL(π0∣∣π)
where π0 is the base model and π is the fine-tuned model. The forward KL divergence, measured on the new task, strongly predicts the extent of forgetting. This makes forgetting quantifiable without needing data from prior tasks.
What do experiments on large language models reveal?
Using Qwen 2.5 3B-Instruct as the base model, fine-tuning was performed on:
- Math reasoning (Open-Reasoner-Zero),
- Science Q&A (SciKnowEval subset),
- Tool use (ToolAlpaca).
Performance was evaluated on prior benchmarks such as HellaSwag, MMLU, TruthfulQA, and HumanEval. Results showed that RL improved new-task accuracy while keeping prior-task accuracy stable, whereas SFT consistently sacrificed prior knowledge.
How does RL compare to SFT in robotics tasks?
In robotic control experiments with OpenVLA-7B fine-tuned in SimplerEnv pick-and-place scenarios, RL adaptation maintained general manipulation skills across tasks. SFT, while successful on the new task, degraded prior manipulation abilities—again illustrating RL’s conservatism in preserving knowledge.
What insights come from the ParityMNIST study?
To isolate mechanisms, the research team introduced a toy problem, ParityMNIST. Here, RL and SFT both reached high new-task accuracy, but SFT induced sharper declines on the FashionMNIST auxiliary benchmark. Crucially, plotting forgetting against KL divergence revealed a single predictive curve, validating KL as the governing factor.
Why do on-policy updates matter?
On-policy RL samples from the model’s own outputs, incrementally reweighting them by reward. This process constrains learning to distributions already close to the base model. SFT, in contrast, optimizes against fixed labels that may be arbitrarily distant. Theoretical analysis shows policy gradients converge to KL-minimal optimal solutions, formalizing RL’s advantage.
Are other explanations sufficient?
The research team tested alternatives: weight-space changes, hidden representation drift, sparsity of updates, and alternative distributional metrics (reverse KL, total variation, L2 distance). None matched the predictive strength of forward KL divergence, reinforcing that distributional closeness is the critical factor.
What are the broader implications?
- Evaluation: Post-training should consider KL-conservatism, not just task accuracy.
- Hybrid methods: Combining SFT efficiency with explicit KL minimization could yield optimal trade-offs.
- Continual learning: RL’s Razor offers a measurable criterion for designing adaptive agents that learn new skills without erasing old ones.
Conclusion
The MIT research reframes catastrophic forgetting as a distributional problem governed by forward KL divergence. Reinforcement learning forgets less because its on-policy updates naturally bias toward KL-minimal solutions. This principle—RL’s Razor—provides both an explanation for RL’s robustness and a roadmap for developing post-training methods that support lifelong learning in foundation models.
Key Takeaways
- Reinforcement learning (RL) preserves prior knowledge better than Supervised fine-tuning (SFT): Even when both achieve the same accuracy on new tasks, RL retains prior capabilities while SFT erases them.
- Forgetting is predictable by KL divergence: The degree of catastrophic forgetting is strongly correlated with the forward KL divergence between the fine-tuned and base policy, measured on the new task.
- RL’s Razor principle: On-policy RL converges to KL-minimal solutions, ensuring updates remain close to the base model and reducing forgetting.
- Empirical validation across domains: Experiments on LLMs (math, science Q&A, tool use) and robotics tasks confirm RL’s robustness against forgetting, while SFT consistently trades old knowledge for new-task performance.
- Controlled experiments confirm generality: In the ParityMNIST toy setting, both RL and SFT showed forgetting aligned with KL divergence, proving the principle holds beyond large-scale models.
- Future design axis for post-training: Algorithms should be evaluated not only by new-task accuracy but also by how conservatively they shift distributions in KL space, opening avenues for hybrid RL–SFT methods.
Check out the PAPER and PROJECT PAGE. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.