
The Problem with “Thinking Longer”
Large language models have made impressive strides in mathematical reasoning by extending their Chain-of-Thought (CoT) processes—essentially “thinking longer” through more detailed reasoning steps. However, this approach has fundamental limitations. When models encounter subtle errors in their reasoning chains, they often compound these mistakes rather than detecting and correcting them. Internal self-reflection frequently fails, especially when the initial reasoning approach is fundamentally flawed.
Microsoft’s new research report introduces rStar2-Agent, that takes a different approach: instead of just thinking longer, it teaches models to think smarter by actively using coding tools to verify, explore, and refine their reasoning process.
The Agentic Approach
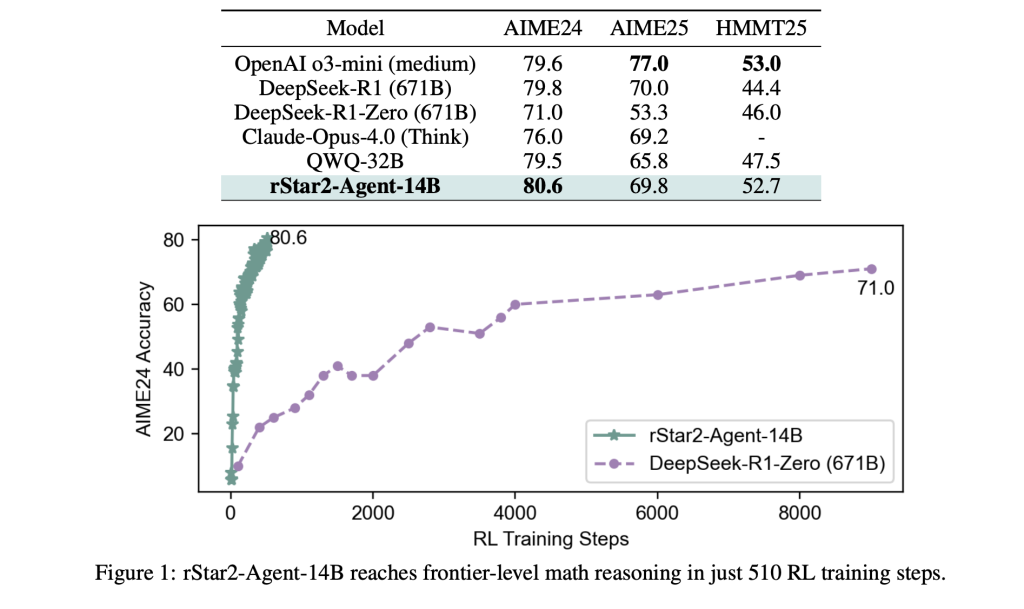
rStar2-Agent represents a shift toward agentic reinforcement learning, where a 14B parameter model interacts with a Python execution environment throughout its reasoning process. Rather than relying solely on internal reflection, the model can write code, execute it, analyze the results, and adjust its approach based on concrete feedback.
This creates a dynamic problem-solving process. When the model encounters a complex mathematical problem, it might generate initial reasoning, write Python code to test hypotheses, analyze execution results, and iterate toward a solution. The approach mirrors how human mathematicians often work—using computational tools to verify intuitions and explore different solution paths.
Infrastructure Challenges and Solutions
Scaling agentic RL presents significant technical hurdles. During training, a single batch can generate tens of thousands of concurrent code execution requests, creating bottlenecks that can stall GPU utilization. The researchers addressed this with two key infrastructure innovations.
First, they built a distributed code execution service capable of handling 45,000 concurrent tool calls with sub-second latency. The system isolates code execution from the main training process while maintaining high throughput through careful load balancing across CPU workers.
Second, they developed a dynamic rollout scheduler that allocates computational work based on real-time GPU cache availability rather than static assignment. This prevents GPU idle time caused by uneven workload distribution—a common problem when some reasoning traces require significantly more computation than others.
These infrastructure improvements enabled the entire training process to complete in just one week using 64 AMD MI300X GPUs, demonstrating that frontier-level reasoning capabilities don’t require massive computational resources when efficiently orchestrated.
GRPO-RoC: Learning from High-Quality Examples
The core algorithmic innovation is Group Relative Policy Optimization with Resampling on Correct (GRPO-RoC). Traditional reinforcement learning in this context faces a quality problem: models receive positive rewards for correct final answers even when their reasoning process includes multiple code errors or inefficient tool usage.
GRPO-RoC addresses this by implementing an asymmetric sampling strategy. During training, the algorithm:
- Oversamples initial rollouts to create a larger pool of reasoning traces
- Preserves diversity in failed attempts to maintain learning from various error modes
- Filters positive examples to emphasize traces with minimal tool errors and cleaner formatting
This approach ensures the model learns from high-quality successful reasoning while still exposure to diverse failure patterns. The result is more efficient tool usage and shorter, more focused reasoning traces.
Training Strategy: From Simple to Complex
The training process unfolds in three carefully designed stages, starting with non-reasoning supervised fine-tuning that focuses purely on instruction following and tool formatting—deliberately avoiding complex reasoning examples that might create early biases.
Stage 1 constrains responses to 8,000 tokens, forcing the model to develop concise reasoning strategies. Despite this limitation, performance jumps dramatically—from near-zero to over 70% on challenging benchmarks.
Stage 2 extends the token limit to 12,000, allowing for more complex reasoning while maintaining the efficiency gains from the first stage.
Stage 3 shifts focus to the most difficult problems by filtering out those the model has already mastered, ensuring continued learning from challenging cases.
This progression from concise to extended reasoning, combined with increasing problem difficulty, maximizes learning efficiency while minimizing computational overhead.
Breakthrough Results
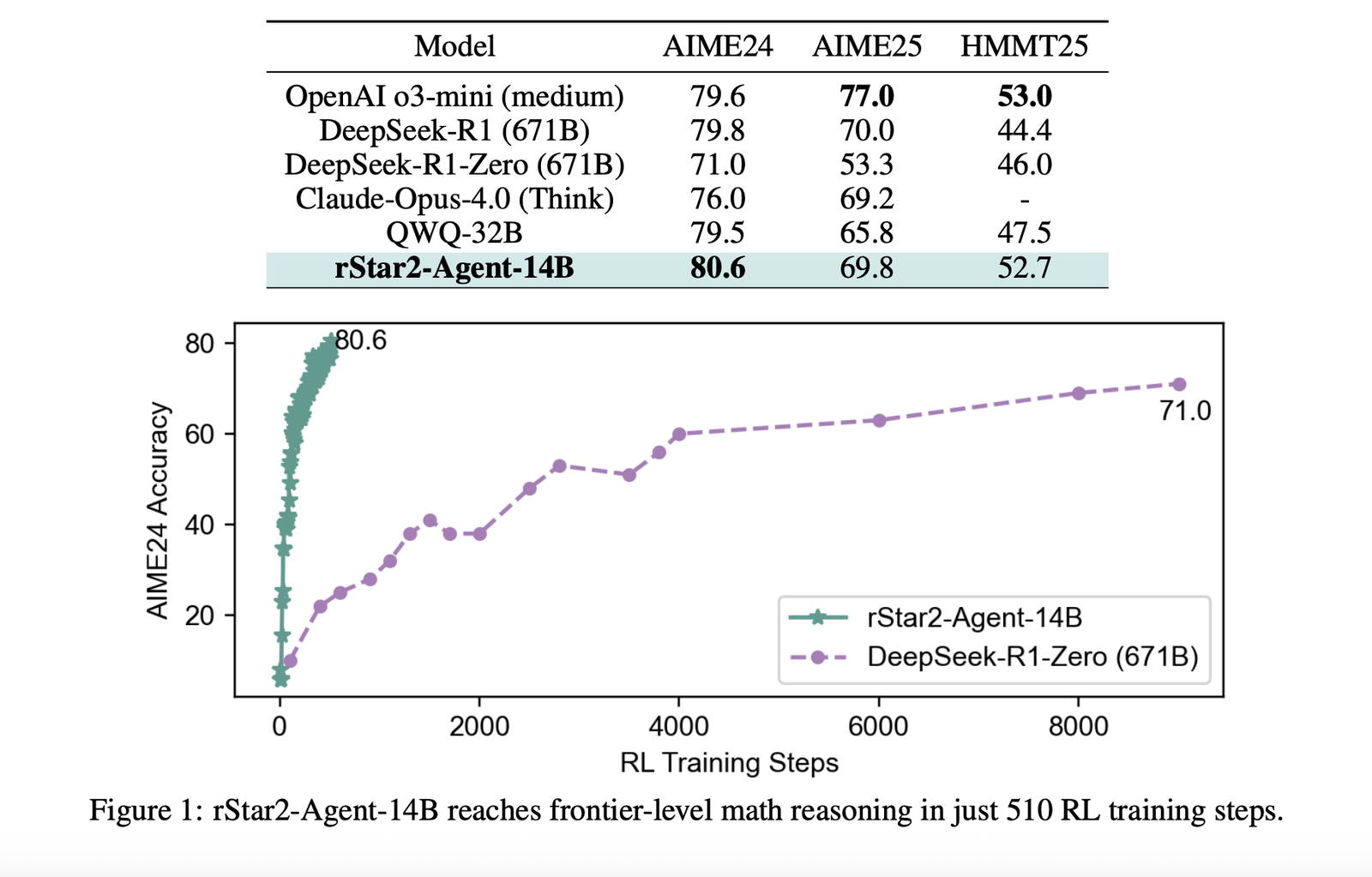
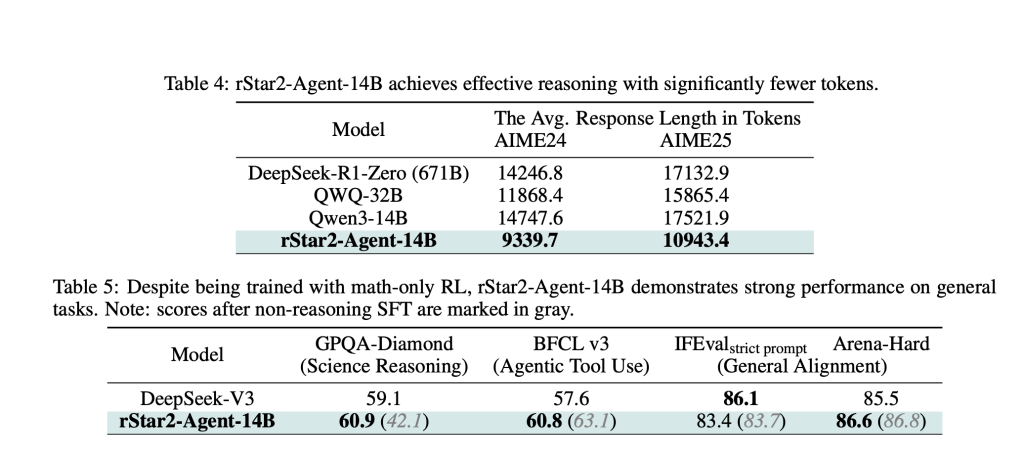
The results are striking. rStar2-Agent-14B achieves 80.6% accuracy on AIME24 and 69.8% on AIME25, surpassing much larger models including the 671B parameter DeepSeek-R1. Perhaps more importantly, it accomplishes this with significantly shorter reasoning traces—averaging around 10,000 tokens compared to over 17,000 for comparable models.
The efficiency gains extend beyond mathematics. Despite training exclusively on math problems, the model demonstrates strong transfer learning, outperforming specialized models on scientific reasoning benchmarks and maintaining competitive performance on general alignment tasks.
Understanding the Mechanisms
Analysis of the trained model reveals fascinating behavioral patterns. High-entropy tokens in reasoning traces fall into two categories: traditional “forking tokens” that trigger self-reflection and exploration, and a new category of “reflection tokens” that emerge specifically in response to tool feedback.
These reflection tokens represent a form of environment-driven reasoning where the model carefully analyzes code execution results, diagnoses errors, and adjusts its approach accordingly. This creates more sophisticated problem-solving behavior than pure CoT reasoning can achieve.
Summary
rStar2-Agent demonstrates that moderate-sized models can achieve frontier-level reasoning through sophisticated training rather than brute-force scaling. The approach suggests a more sustainable path toward advanced AI capabilities—one that emphasizes efficiency, tool integration, and smart training strategies over raw computational power.
The success of this agentic approach also points toward future AI systems that can seamlessly integrate multiple tools and environments, moving beyond static text generation toward dynamic, interactive problem-solving capabilities.
Check out the Paper and GitHub Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.














