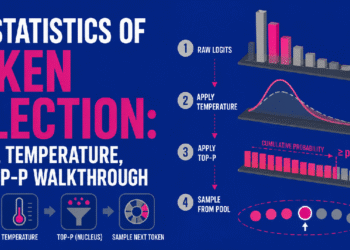
import torch
import torch.nn as nn
import torch.nn.functional as F
class Expert(nn.Module):
def __init__(self, dim, intermediate_dim):
super().__init__()
self.gate_proj = nn.Linear(dim, intermediate_dim)
self.up_proj = nn.Linear(dim, intermediate_dim)
self.down_proj = nn.Linear(intermediate_dim, dim)
self.act = nn.SiLU()
def forward(self, x):
gate = self.gate_proj(x)
up = self.up_proj(x)
swish = self.act(gate)
output = self.down_proj(swish * up)
return output
class MoELayer(nn.Module):
def __init__(self, dim, intermediate_dim, num_experts, top_k=2):
super().__init__()
self.num_experts = num_experts
self.top_k = top_k
self.dim = dim
# Create expert networks
self.experts = nn.ModuleList([
Expert(dim, intermediate_dim) for _ in range(num_experts)
])
self.router = nn.Linear(dim, num_experts)
def forward(self, hidden_states):
batch_size, seq_len, hidden_dim = hidden_states.shape
# Reshape for expert processing, the compute routing probabilities
hidden_states_reshaped = hidden_states.view(–1, hidden_dim)
router_logits = self.router(hidden_states_reshaped) # (batch_size * seq_len, num_experts)
routing_probs = F.softmax(router_logits, dim=–1)
# Select top-k experts, and scale the probabilities to sum to 1
# output shape: (batch_size * seq_len, k)
top_k_probs, top_k_indices = torch.topk(routing_probs, self.top_k, dim=–1)
top_k_probs = top_k_probs / top_k_probs.sum(dim=–1, keepdim=True)
# Process through selected experts
output = []
for i in range(self.top_k):
expert_idx = top_k_indices[:, i]
expert_probs = top_k_probs[:, i]
# Process each vector in the batch and sequence with the selected expert
expert_output = torch.stack([
self.experts[j](hidden_states_reshaped[j])
for j in expert_idx
], dim=0)
# Weighted sum by routing probability
output.sum(expert_probs.unsqueeze(–1) * expert_output)
# Reshape back to original shape
output = sum(output).view(batch_size, seq_len, hidden_dim)
return output
class MoETransformerLayer(nn.Module):
def __init__(self, dim, intermediate_dim, num_experts, top_k=2, num_heads=8):
super().__init__()
self.attention = nn.MultiheadAttention(dim, num_heads, batch_first=True)
self.moe = MoELayer(dim, intermediate_dim, num_experts, top_k)
self.norm1 = nn.RMSNorm(dim)
self.norm2 = nn.RMSNorm(dim)
def forward(self, x):
# Attention sublayer
input_x = x
x = self.norm1(x)
attn_output, _ = self.attention(x, x, x)
input_x = input_x + attn_output
# MoE sublayer
x = self.norm2(input_x)
moe_output = self.moe(x)
return input_x + moe_output