
Key advancements include in-context learning, which enables coherent text generation from prompts, and reinforcement learning from human feedback (RLHF), which fine-tunes models based on human responses. Techniques like prompt engineering have also enhanced LLM performance in tasks such as question answering and conversational interactions, marking a significant leap in natural language processing.
Pre-trained language models like GPT, trained on vast text corpora, learn the fundamental principles of word usage and their arrangement in natural language. However, while LLMs perform well in general, many struggle to efficiently handle task-oriented problems. That’s where LLM fine-tuning plays a crucial role—adapting foundation models to specialized use cases without the need to build them from the ground up.
This analysis explains the importance of fine-tuning as a strategic approach to transform generic LLMs into specialized tools capable of addressing specific enterprise needs with greater precision and reliability.
Training large language models (LLMs)
LLMs like GPT-3, GPT-4, LLaMA, and PaLM are trained on extensive volumes of text data with tens of billions of parameters. Training these models involves a two-stage process—pre-training on a vast corpus followed by fine-tuning with human values—to enable them to understand human input and values better.
Pre-trained language models (PLMs)
A large language model lifecycle is a multi-stage process including pre-training, fine-tuning, evaluation, deployment, and monitoring and maintenance. Pre-trained large language models, such as GPT (Generative Pre-trained Transformer), are initially trained on vast amounts of unlabelled text data to understand fundamental language structures and their arrangement in the natural language. They are then fine-tuned on smaller, task-oriented datasets.
PLMs can understand natural language and produce human-like output based on the input they receive.
What is fine-tuning?
LLM fine-tuning is the process of further training a pre-trained model on a smaller, domain-specific dataset. This technique uses the model’s pre-existing knowledge to make the general-purpose model more accurate and relevant for a particular task or domain, with reduced data and computational requirements.
Instead of building a model from scratch for each task, fine-tuning leverages the pre-trained model’s learned patterns and adapts them to new tasks, boosting performance while reducing training data needs. By bridging the gap between generic pre-trained models and the unique requirements of specific applications, fine-tuning ensures models align closely with human expectations.
Think of a foundation model, such as GPT-3, developed for a broad range of Natural Language Processing (NLP) tasks. Suppose a financial services organization wants to use GPT-3 to assist financial analysts and fraud detection teams in detecting anomalies, such as fraudulent transactions, financial crime, and spoofing in trading, or in delivering personalized investment advice and banking offers based on customer journeys. Despite understanding and creating general text, GPT-3 might struggle with nuanced financial terminology and domain-specific jargon due to its lack of fine-tuning on specialized financial datasets.
Unsupervised fine-tuning
This method involves training the LLM on a large corpus of unlabeled text from the target domain. The model analyzes the statistical properties and relationships between words within the domain-specific data, thereby refining its understanding of the language used in that field. This approach makes LLMs more proficient and useful in specialized fields, such as legal or medical, which they might not have been initially trained on in depth (or at all). It enables the model to recognize general topics, understand unique linguistic structures, and correctly interpret specialized terminology.
Unsupervised fine-tuning is suitable for language modeling tasks where the model learns to predict the next word in a sequence based on context. However, it is less effective for specialized downstream tasks such as classification or summarization.
Supervised Fine-tuning with Data Labeling for LLMs
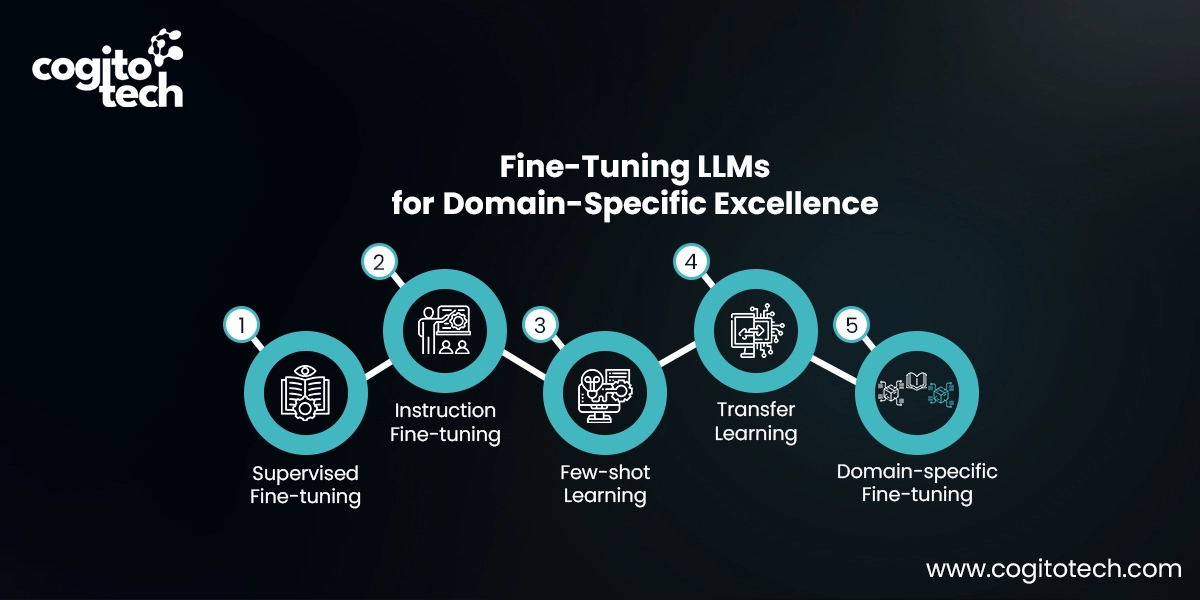
Supervised fine-tuning is the process of training the LLM with domain-specific labeled data. These ground truth datasets are created through data labeling for large language models, where each input is annotated with precise labels relevant to the task. For instance, if a business wants the LLM to automatically categorize emails or customer feedback (text classification), it needs to train the LLM with examples of these texts, each already marked with its correct category (e.g., billing issue, sales inquiry, or technical support).
The model analyzes the labeled data to identify sentence structures and other linguistic patterns associated with specific categories. This enables the model to improve its ability to categorize novel, unseen text from that domain and assign it to one of the predefined labels provided during training. Supervised fine-tuning is an effective technique for domain-specific, nuanced, and contextually accurate learning for specialized task performance, and it requires a significant amount of labeled data.
Instruction fine-tuning
This strategy focuses on providing clear instructions to improve the LLM’s performance on various tasks. The model is trained using examples (prompt-response pairs) demonstrating how the model should respond to the query. The dataset you use for fine-tuning LLMs trains the model to understand and interpret these instructions to execute specific tasks without relying on a large corpus of labeled data for each task.

For example, if you want to fine-tune your model to translate from one language to another. In that case, you should create a dataset of examples that begin with the instructions for translating, followed by text or a similar phrase. For customer query resolution, you should include instructions like “respond to this query.” These prompt-response pairs reduce data dependency and allow your model to think in a domain-specific way, and serve the given particular task.
Other types of fine-tuning
Few-shot learning
In cases where it is impractical to obtain a large volume of labeled data, few-shot learning can be helpful by providing a few completed examples of the required task within the input prompts. This allows the model to have a better context of the task without an extensive fine-tuning process.
Transfer learning
Transfer learning enables a model to perform a task deviating from those it was initially trained on. This approach allows it to leverage the knowledge the model has acquired from a large, general dataset and apply it to a more specific task.
Domain-specific fine-tuning
As the name suggests, this type of fine-tuning involves adapting the model to understand and generate text peculiar to a particular domain or industry. The model is refined using a dataset containing text from the target domain to enhance its context and knowledge of domain-specific tasks. For example, to build a chatbot for an e-commerce app, the model would be trained with customer queries, past transactions, and product-related conversations to fine-tune its language understanding capabilities to the e-commerce field.
Guide to fine-tuning a LLM
When preparing training data to fine-tune a model for a specific task, there is a wealth of data out there that, while not explicitly ‘instructional’, offers insights into user behaviors and preferences. For example, we can take a large volume of data from Apple product reviews and modify them as instruction-prompt datasets for fine-tuning. Prompt template libraries include predefined structures. These templates can be general (e.g., ‘Summarize this text’) or specific (e.g., ‘Extract customer pain points from this review’). Such templates help standardize the input format for the LLM during fine-tuning, making the learning process more efficient and effective.
Once your instruction dataset (pairs of instruction prompts) is ready, it needs to be divided into three parts: training set, validation set, and test set. During fine-tuning, you take prompts from the training set and feed them to the LLM, which then generates responses (completions).
During the fine-tuning, a newly labeled dataset focusing on the target task is fed into the model. The model compares the difference between its predictions and errors and the actual labels. It then uses these errors to adjust its weights (numerical parameters that determine the strength of the connections between neurons) to ensure its predictions become progressively closer to the actual labels.
With each iteration or epoch over the dataset, the model slightly adjusts its weights for the specific task, honing its configuration to improve performance while reducing errors. By transforming its previously learned general knowledge into an understanding of the nuances and specific patterns present in the new dataset, the model becomes specialized and effective for the target task.
Based on “error calculation” and “weight adjustment,” the LLM compares predictions to the label, evaluates the difference (error/loss), and then updates its internal knowledge (weights) to reduce that difference for future guesses.
For example, if you ask a pre-trained model, “Why do we see only one side of the Moon?”, it might simply reply, “Because the Moon takes the same amount of time to complete one rotation on its axis as it does to go around the Earth once.” While technically correct, the answer is too short for a science education portal that is expected to give clearer context and deeper explanation. This is where LLM fine-tuning becomes essential.
A model fine-tuned on domain-specific labeled data can provide more in-depth insights suitable for a science learning platform, such as:
“We see only one side of the Moon because of a phenomenon referred to as tidal locking (or captured rotation). The Moon’s rotation period (the time it takes to rotate once on its axis) is synchronized with its orbital period around the Earth, which is about 27.3 days. This means the same side is always facing the Earth. Tidal forces over millions of years slowed the Moon’s rotation until it matched its orbit, making the near side always visible and the far side hidden from view.”
This enriched answer contains scientific terms, detailed reasoning, and context, making it useful for a science education website.
Cogito Tech’s fine-tuning strategies for production-ready LLMs
LLMs require expert, domain-specific data that generalist workflows can’t handle. Cogito Tech’s Innovation Hubs integrate PhDs and graduate-level experts—across law, healthcare, finance, and more—directly into the data lifecycle to provide nuanced insights critical for refining AI models. Our human-in-the-loop approach ensures meticulous refinement of AI outputs to meet the unique requirements of specific industries.
We use a range of fine-tuning techniques that help refine the performance and reliability of AI models. Each technique serves specific needs and contributes to the overall refinement process. Cogito Tech’s LLM services include:
- Custom dataset curation: The absence of context-rich, domain-specific datasets limits the fine-tuning efficacy of LLMs for specialized downstream tasks. At Cogito, we curate high-quality, domain-specific datasets through customized workflows to fine-tune models, enhancing their accuracy and performance in specialized tasks.
- Reinforcement learning from human feedback (RLHF): LLMs often lack accuracy and contextual understanding without human feedback. Our domain experts evaluate model outputs for accuracy, helpfulness, and appropriateness, providing instant feedback for RLHF to refine responses and improve task performance.
- Error detection and hallucination rectification: Fabricated or inaccurate outputs significantly undermine the reliability of LLMs in real-world applications. We enhance model reliability by systematically detecting errors and eliminating hallucinations or false facts, ensuring accurate and trustworthy responses.
- Prompt and instruction design: LLMs sometimes struggle to follow human instructions accurately without relevant training examples. We create rich prompt-response datasets that pair instructions with desired responses across various disciplines to fine-tune models, enabling them to better understand and execute human-provided instructions.
Final words
Considering the uncertainties around LLM performance and reliability, fine-tuning has become an essential technique for enterprises to meet their LLM needs and enhance operational processes. While pre-trained models have a broad understanding of language, the fine-tuning process adapts these language models into specialized systems that can understand nuances, handle niche topics, and deliver more precise results.
Cogito Tech’s Generative AI Innovation Hubs integrate domain experts, including PhDs and graduate-level specialists across disciplines, into the model refinement lifecycle. This approach ensures that models remain relevant and valuable in the rapidly evolving digital landscape. By combining expert-driven evaluation with scalable workflows, Cogito Tech enables the development of accurate, context-aware, and reliable LLMs ready for production-grade deployment across industries.















