
In this article, you will learn what context engineering is and how to apply it systematically to keep AI agents reliable, cost-efficient, and accurate in production.
Topics we will cover include:
- How to treat the context window as a constrained resource and understand the financial and cognitive costs of token mismanagement.
- How to structure context layers — separating static from dynamic content, managing conversation history, and designing retrieval as a budget decision.
- How to evaluate and monitor context quality in production using probe-based evaluation and context-specific metrics.
Effective Context Engineering for AI Agents: A Developer’s Guide
Image by Author
Introduction
When AI agents break down in production, the problem is rarely the model. More often, the context window is mismanaged: bloated with stale history, redundant retrieval results, and raw tool outputs that bury the signal the model actually needs.
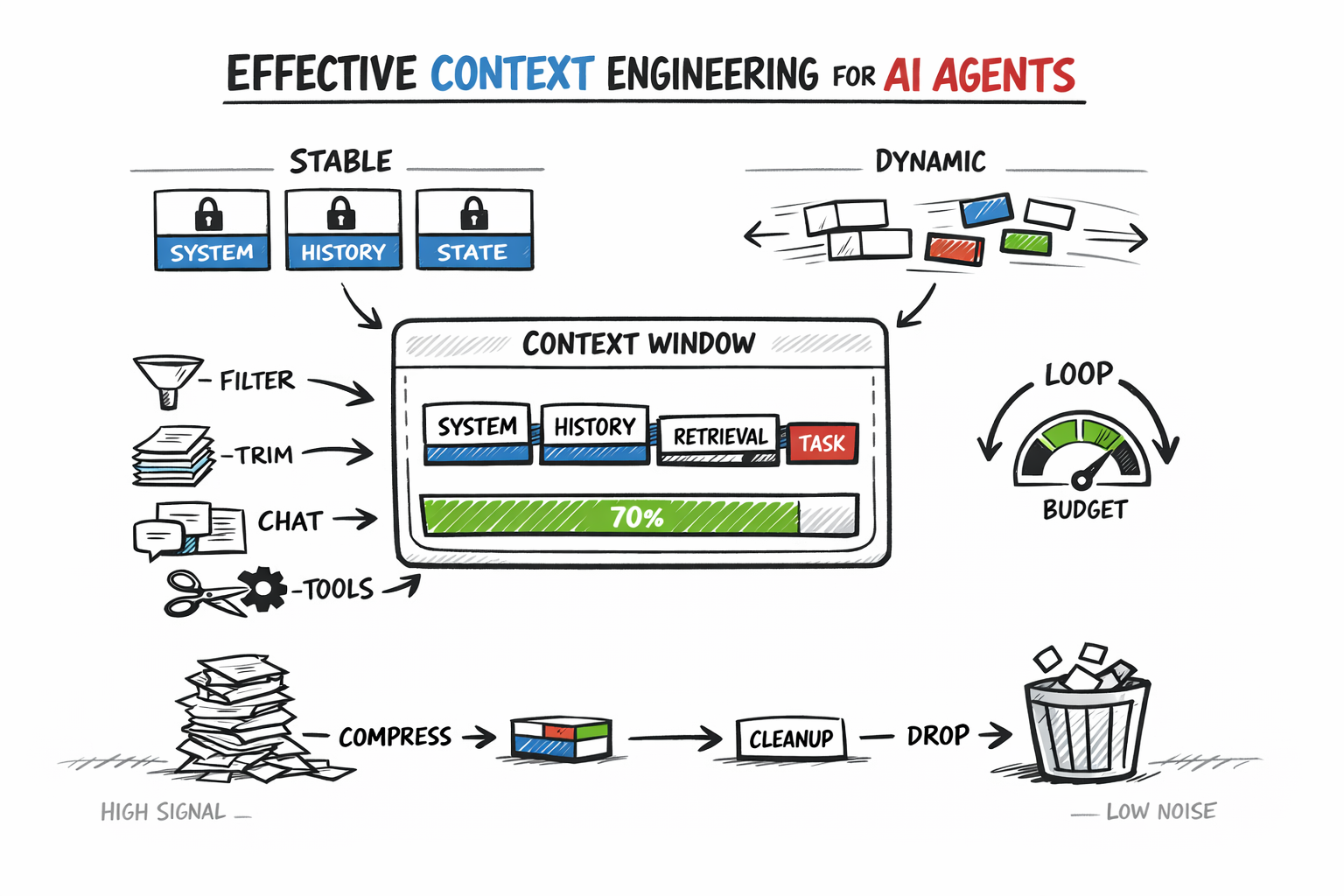
Context engineering is the practice of deciding what enters the context window, what gets compressed, what gets retrieved on demand, and what gets dropped entirely. Done well, it keeps every token high-signal and cuts the cost and quality problems that come from naive context accumulation.
This article covers the core practices:
- Understanding the context window as a constrained resource
- Structuring and separating stable from dynamic context
- Managing history, retrieval, and token budgets across the agent loop
- Evaluating and monitoring context quality in production
Each practice builds on the last, forming the architecture that keeps agents reliable under real workloads.
Treating the Context Window as a Constrained Resource
The context window shapes every other decision in agentic architecture. Treating it as a mere technical limit to route around, rather than the primary design parameter, is where most agent implementations go wrong.
Tokens have two kinds of cost: financial and cognitive. Financial cost is direct — models are billed per million input tokens, and this scales quickly in multi-step agent loops.
Cognitive cost is less obvious. Models do not treat all tokens equally. Attention tends to prioritize information at the beginning and end of the context, while mid-context content is often less influential. As a result, long or poorly structured inputs can degrade reasoning even if they fit within the token limit.
The mental model that helps most is treating the context window like RAM: fast and powerful, but finite and cleared between sessions. External memory, databases, and file systems are the disk — cheap and large, but requiring explicit retrieval to be useful.
Good context engineering decides at each step what belongs in RAM right now and what lives on disk until needed. Google’s Agent Development Kit (ADK) team addresses why the naive pattern of appending everything into one giant prompt collapses under three-way pressure: cost and latency spirals, signal degradation, and eventual overflow.
Mapping What Fills the Context Window
Most agents have more competing inputs than developers realize until they audit them. A production context window typically contains some combination of:
- System instructions — the agent’s role, behavioral rules, tool descriptions, output format requirements, and few-shot examples. Largely static, making this layer a strong candidate for prefix caching.
- Conversation history — the running record of user turns, agent responses, tool calls, and tool results. Often the fastest-growing layer and the one most teams under-manage.
- Retrieved knowledge — documents, database records, or memory items fetched from external stores. Retrieval systems can return relevant-but-redundant content, and every chunk consumes a budget that could hold something more useful.
- Working state — intermediate results, scratchpad reasoning, task progress. Necessary for multi-step coherence, but expensive if stored as verbose reasoning traces.
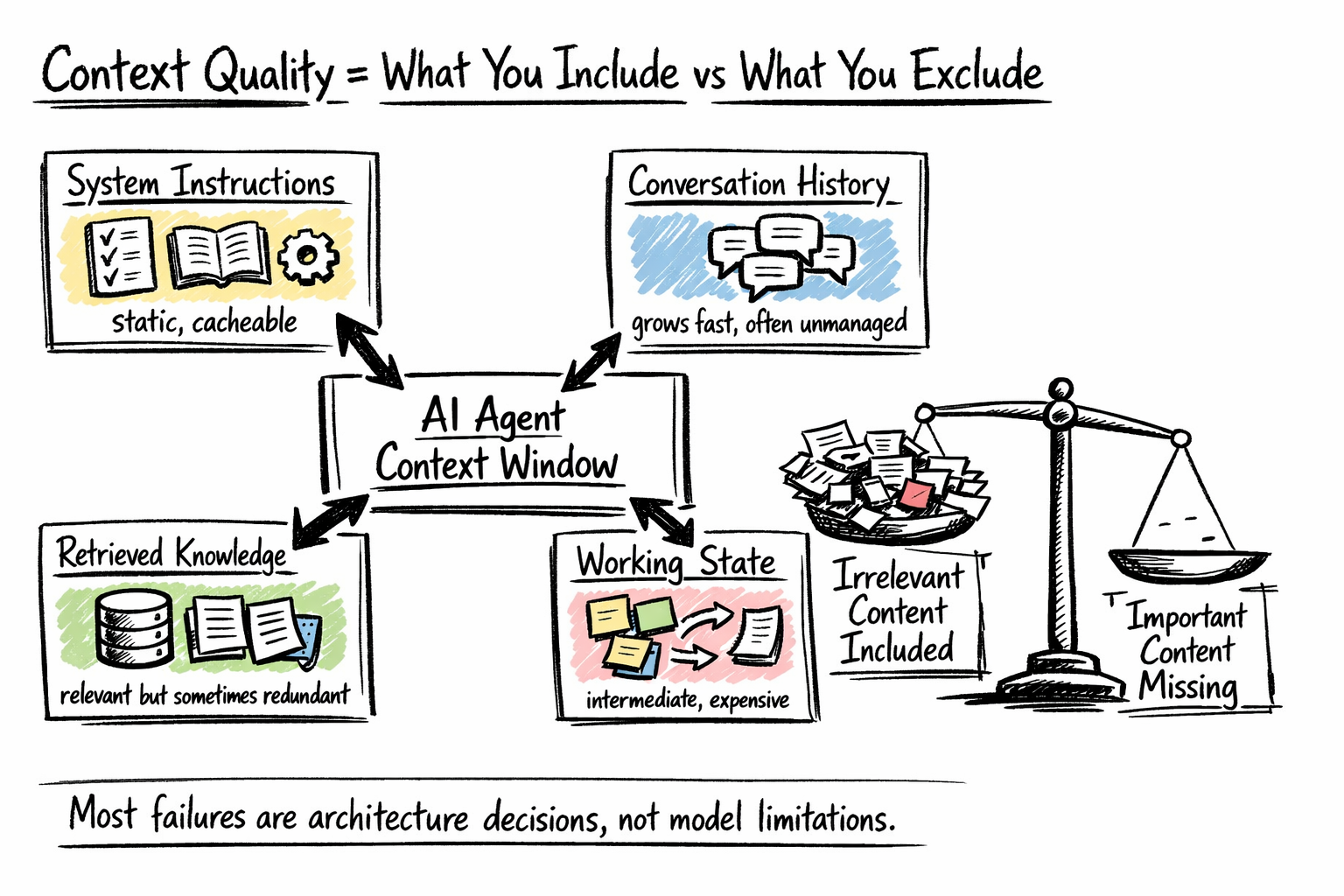
What goes into the context window
The goal of this audit is to understand the trade-offs across layers, not to minimize each one. Most context quality problems in production trace back to one of two failures: including content irrelevant to the current step, or excluding content that matters. Both are architecture decisions, not model decisions.
Separating Static from Dynamic Context
One of the highest-value structural decisions in context engineering is the split between content that stays fixed across requests and content that changes with each turn.
Static context: system instructions, agent identity, tool schemas, and fixed rules placed at the front of the prompt. This enables prefix caching, where unchanged prefixes are reused instead of recomputed each call.
Dynamic context: current user input, recent tool outputs, and retrieved documents in the variable suffix. This layer should stay minimal, containing only what’s needed for the current reasoning step.
The practical implementation is a two-pass context assembly pipeline.
- The first pass loads static context: system prompt, cached instructions, long-lived summaries.
- The second pass injects dynamic context: current task state, fresh retrieval results, recent history.
This separation also simplifies debugging. Unexpected behavior can be traced to either the static configuration — which is often a prompt engineering problem — or the dynamic state, which points to a retrieval or history management problem.
Managing Conversation History
Conversation history is the context component agents most often handle poorly. Most frameworks simply append each new turn and resend the full history. This works for short sessions, but long-running agents accumulate cost and quality issues.
Context bloat happens when old tool outputs, resolved errors, and outdated decisions remain in the prompt, consuming tokens without adding value. Context poisoning occurs when a model’s earlier mistake is preserved and treated as truth, causing compounding errors as later reasoning builds on it. See How Long Contexts Fail for more detail.
A simple strategy like recency truncation — keeping only the last N turns — is cost-effective but loses long-term state. A stronger approach is rolling summarization: periodically compress older exchanges into a short summary capturing decisions, attempts, and current state.
The most robust method is anchored iterative summarization, where a structured session-state document — intent, decisions, actions, next steps — is continuously updated, preserving meaning while preventing context overflow.
Designing Retrieval as a Budget Decision
Retrieval lets agents access knowledge that doesn’t fit in the context window. A common mistake is treating it as a simple upstream step — retrieve chunks, inject them, and proceed — without asking how much of the context budget retrieval should actually consume, or when it’s worth it.
Token cost is often underestimated. In multi-retrieval workflows, costs stack quickly. Post-retrieval filtering — scoring and selecting only relevant results before injecting them into context — is one of the highest-leverage optimizations.
Structure matters as much as selection. Semantic chunking, which splits documents along natural topic boundaries instead of fixed sizes, performs better because it preserves meaning and coherence. Hybrid retrieval combines semantic search with keyword or metadata filters, handling cases pure embeddings miss. For example, “billing issues in the last 30 days” requires both semantic relevance and a time constraint; neither approach alone is sufficient.
One design decision worth making explicitly: should retrieval fire automatically before every agent turn, or should the agent invoke it as a tool when it recognizes a need?
- Automatic retrieval is simpler but injects tokens whether or not they are useful.
- Agent-controlled retrieval produces more targeted queries and fires at the right moment in the reasoning chain, at the cost of requiring the model to recognize when retrieval would help.
For most production systems, agent-controlled retrieval is the better default once the system is stable.
Budgeting Tokens Across the Full Agent Loop
Individual context decisions only solve part of the problem. In multi-step agent loops, tokens accumulate across turns, so budgeting must treat the full run as the cost unit.
Tokens mainly go to system prompts and tool outputs. Tool responses — especially search and API results — are often the largest cost. Filtering and trimming them at ingestion is more effective than compressing later; only keep what’s needed for the next step.
Aim for roughly 60–80% context utilization rather than maxing out capacity. Tracking this in production helps catch budget issues early. Use dynamic allocation: simple tasks get minimal context, while complex multi-step tasks get more. This balances cost and capability.
Evaluating Context Quality in Production
Context engineering failures are often invisible in standard evaluations. An agent may perform well in short test sessions but degrade in longer ones, with failures incorrectly attributed to reasoning instead of context management.
A practical way to isolate this is probe-based evaluation: after compression or retrieval steps, ask targeted questions that require specific stored information. Correct responses indicate the relevant context was preserved; incorrect ones reveal issues in compression or retrieval quality. Factory.ai’s evaluation framework uses three probe types:
- Recall probes: can the agent remember specific facts?
- Artifact probes: does the agent know what files it has modified?
- Continuation probes: can the agent pick up a multi-step task where it left off?
Here are some context-specific production metrics worth tracking:
- Context utilization rate — percentage of budget actually used
- Compression ratio — token reduction from summarization
- Retrieval precision — are retrieved chunks actually being used by the model, or ignored after injection?
Monitoring for context drift in long-running sessions is also worth instrumenting explicitly. Signal indicators include the agent re-reading files it already processed, re-stating decisions it already made, or gradually reframing the task away from the original user intent. These patterns appear in step-level traces before they surface in output quality.
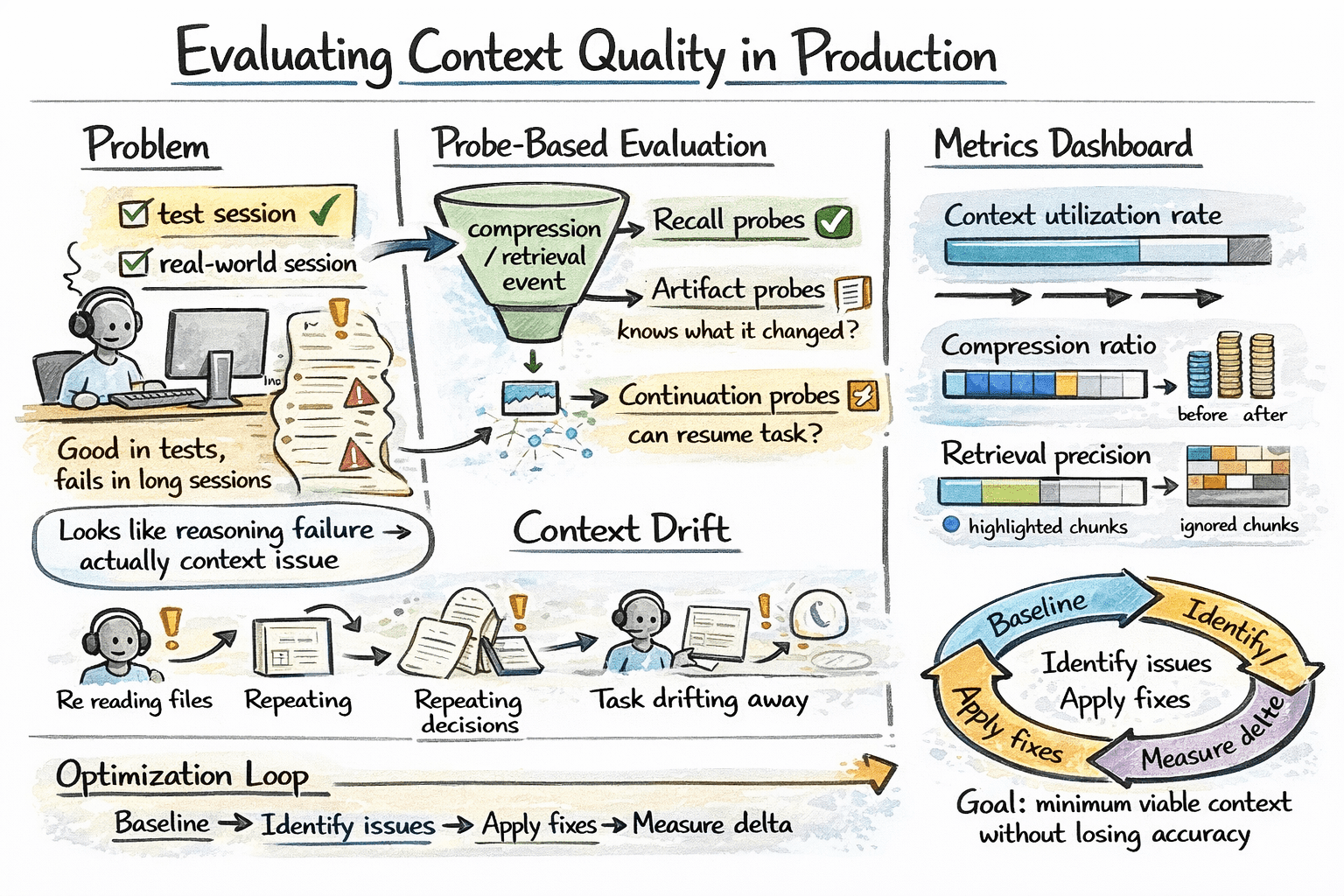
Evaluating context quality in production
The right optimization cycle is: set baseline metrics on real sessions, find high-cost or low-quality segments, apply targeted fixes, and measure impact.
Over-compression can save tokens but hurt accuracy, shifting the problem instead of solving it. The goal is the minimum viable context that still lets the agent complete its task correctly.
Wrapping Up
Context engineering spans all parts of agent design: context content, history management, compression, retrieval, and token budgeting. Each choice should be deliberate. Tooling is improving with prefix caching, better summarization, and stronger retrieval. The core rule stays the same: treat context as scarce, include only what’s necessary, and validate against real behavior. Here’s an overview of the key concepts covered:
| Concept | Summary |
|---|---|
| Context Engineering | Systematic design of what enters the context window to improve reliability, accuracy, and cost efficiency. |
| Context Window as Resource | Treat tokens as limited compute and cognitive budget with both financial cost and attention constraints. |
| Context Structure | Includes system instructions, conversation history, retrieved knowledge, and working state; split into static (fixed, cacheable) and dynamic (task-dependent) layers. |
| History Management | Avoid raw accumulation; use truncation, summarization, or structured state tracking to prevent bloat and error propagation. |
| Retrieval Design | Treat retrieval as a budgeted operation using filtering, semantic chunking, and agent-controlled triggering. |
| Token Budgeting | Manage tokens across full agent loops; prioritize trimming tool outputs and maintain ~60–80% utilization. |
| Evaluation & Key Metrics | Use probe-based tests (recall, artifact, continuation) and track utilization, compression ratio, retrieval precision, and context drift. |
And here are a couple of helpful resources for further learning:
















