
In this article, you will learn what agentic RAG is, how it differs from traditional RAG, and when to use it.
Topics we will cover include:
- The key limitations of traditional RAG pipelines and what agents add to address them.
- How the agentic retrieval loop works, including query decomposition, multi-hop chaining, and self-correction.
- Advanced architectures like Graph RAG, reflection, and memory, along with the production tradeoffs that come with them.
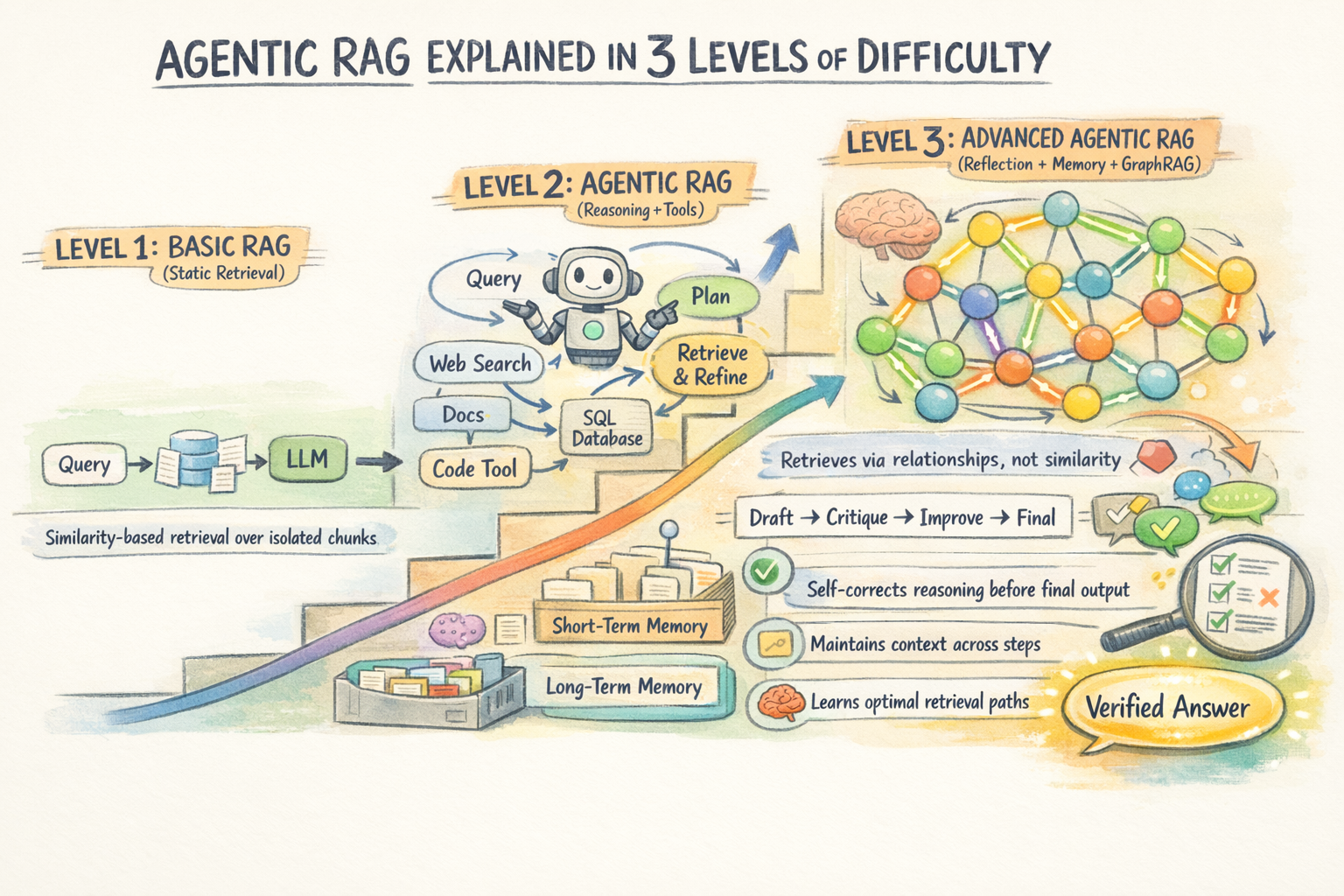
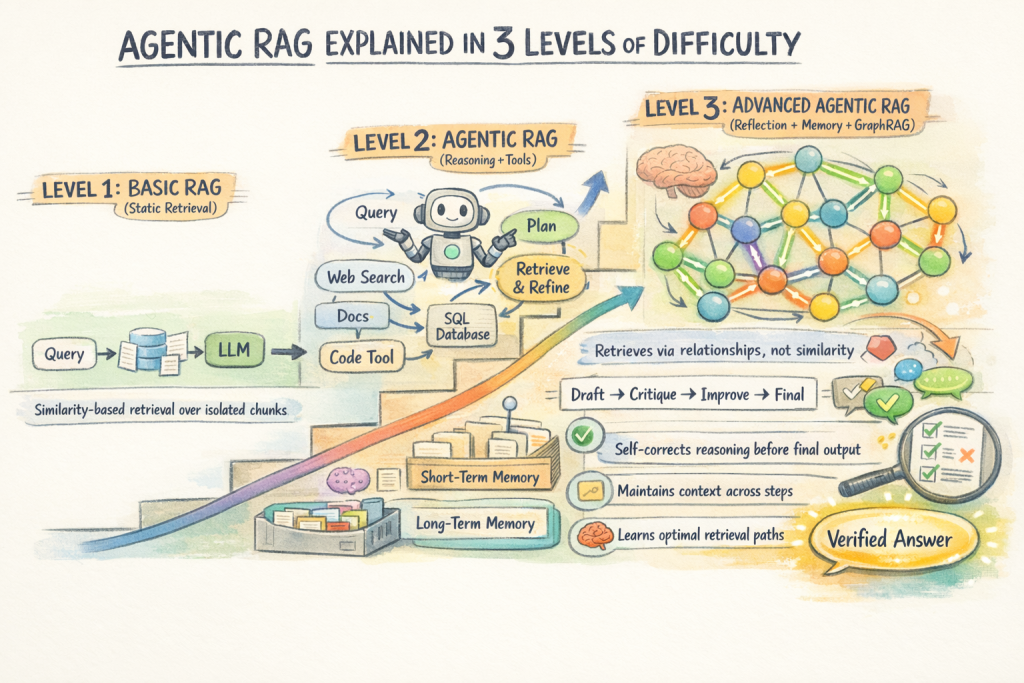
Agentic RAG Explained in 3 Levels of Difficulty
Introduction
Traditional Retrieval-Augmented Generation (RAG) retrieves information once and generates a response based on that single result. This approach works well for simple, clearly defined questions. However, it starts to break down when a task requires pulling information from multiple sources, reasoning across documents, or refining incomplete results.
A basic RAG pipeline has no built-in way to retry, adjust its retrieval strategy, or validate the quality of what it retrieved. As a result, it can struggle with more complex queries where iteration and verification are important. Agentic RAG extends the traditional RAG pipeline by introducing autonomous AI agents into the process. Instead of a single retrieval pass, an agent decomposes the query, routes each part to the right source, checks what it gets back, and iterates until it has enough grounded context to generate a reliable answer.
This article covers agentic RAG at three levels. Level 1 contrasts it with traditional RAG and explains the core capabilities agents add. Level 2 gets into how the retrieval loop actually works: decomposition, multi-hop chaining, and self-correction. Level 3 covers more advanced architectures like Graph RAG and the production tradeoffs that matter at scale.
Level 1: Making Sense of the “Agentic” in Agentic RAG
The Limitations of Traditional RAG
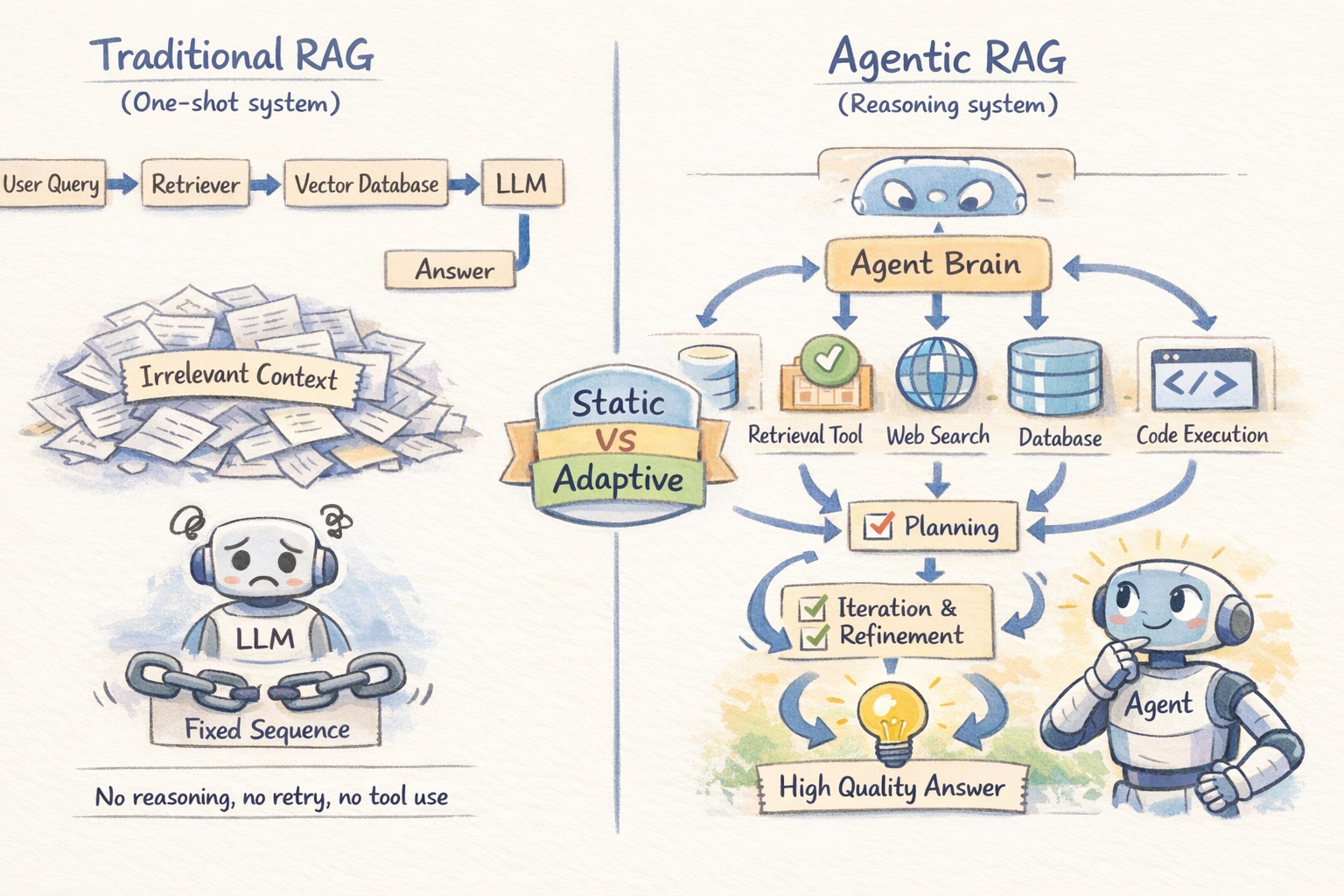
Traditional RAG follows a fixed sequence. The retriever runs once, produces a set of chunks, and those chunks go to the LLM. There is no reasoning about whether the retrieved context is actually useful, no mechanism to try again if retrieval misses the mark, and no ability to pull from multiple sources or use external tools. It is a one-shot solution.
This creates specific failure modes. For a query like “Compare our Q3 2025 sales with Q1 2026 performance and summarize the key risk factors from our latest SEC filing,” a static RAG pipeline retrieves whatever chunks happened to be most similar to that combined query — almost certainly a mishmash that doesn’t cleanly address either part.
The pipeline has no way to decompose the question, retrieve different information for each part, and synthesize a coherent answer.
Basic RAG vs. Agentic RAG
What Agents Add
An AI agent is an LLM-powered system with a role, a task, and access to tools — and more importantly, the ability to reason about what to do next based on what it observes. The key capabilities agents bring to RAG are planning, tool use, and iterative refinement:
Planning lets the agent break a complex query into subtasks and decide what information is needed and in what order.
Tool use allows retrieval beyond vector stores, including web search, SQL databases, APIs, and code execution — choosing the right tool per task.
Iterative refinement enables the agent to evaluate results, retry searches, and resolve conflicts by retrieving more context, improving reliability over one-shot retrieval.
Level 2: Understanding How the Agentic Retrieval Loop Works
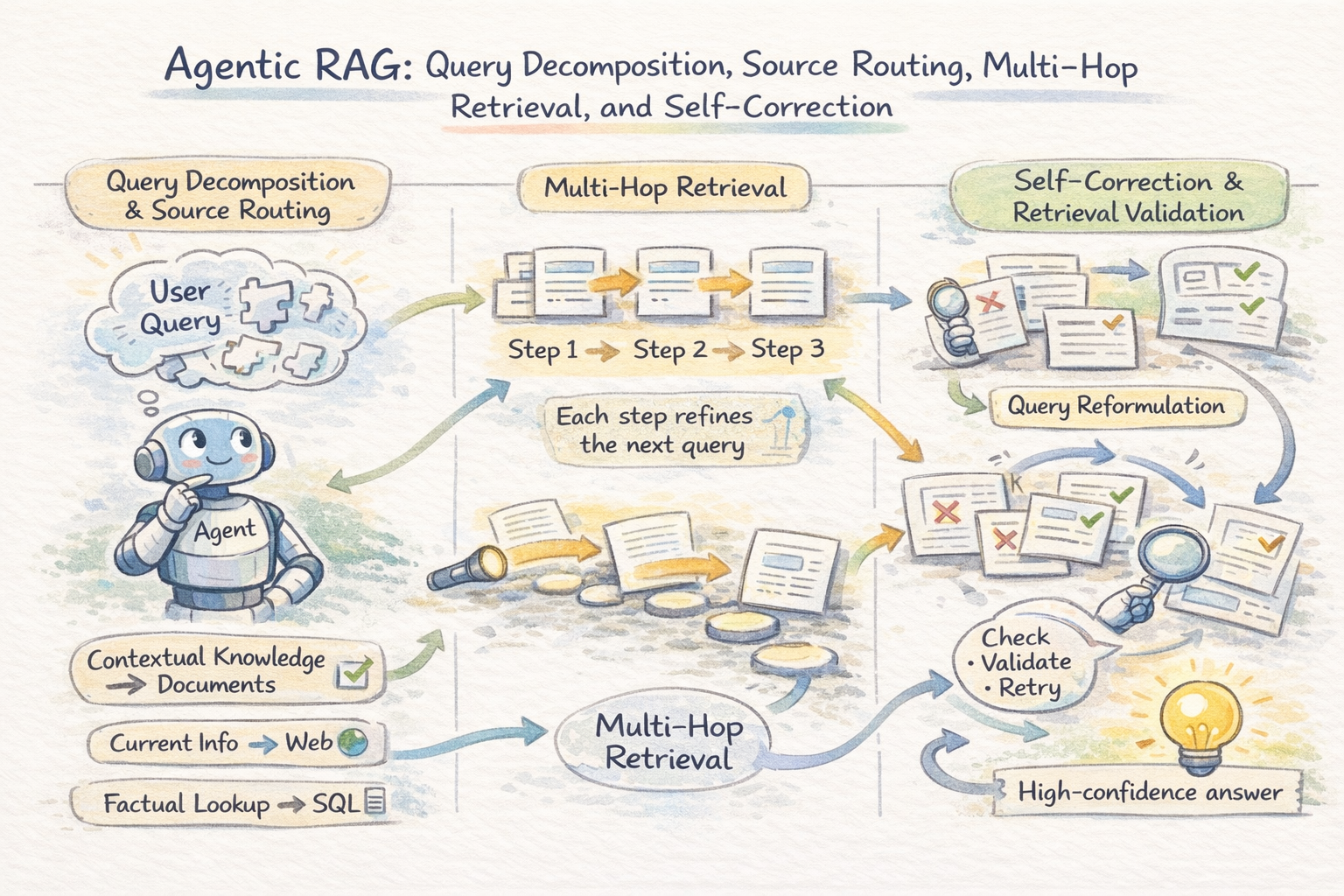
Query Decomposition and Source Routing
The first thing an agentic RAG system does with a complex query is break it apart. Rather than firing the full query at a single retrieval source, the agent identifies the distinct information needs embedded in it and plans a retrieval strategy for each one. This is query decomposition, and it is what makes agentic RAG qualitatively different from static pipelines.
Once decomposed, each sub-question is routed to the most suitable source. The agent acts as a router across vector stores, databases, web search, and knowledge bases. Routing depends on query type: factual lookups go to structured data, semantic queries go to documents, and time-sensitive questions go to web search. A single request may combine multiple sources in sequence.
Multi-Hop Retrieval
Many queries require multi-hop reasoning, where information must be connected across multiple documents. For example, understanding a company’s legal exposure may require linking filings, case law, and compliance records that aren’t retrieved together in one step.
Agentic systems solve this by chaining retrievals: each result informs the next query. The agent iterates — retrieving context, identifying gaps, refining queries — until enough evidence is gathered for a reliable answer.
Systems like RQ-RAG formalize this by decomposing multi-hop queries into latent sub-questions upfront; RAG-Fusion takes a parallel approach, generating multiple reformulations of the same query and merging results using reciprocal rank fusion to improve recall when a single formulation would miss relevant content.
An overview of agentic retrieval loop
Self-Correction and Retrieval Validation
In a static pipeline, retrieved context is passed directly to the LLM, which cannot verify its relevance and may generate incorrect but plausible answers from loosely related chunks.
Agentic systems add validation steps: the agent checks relevance, detects contradictions, and re-queries when needed. Irrelevant or weak evidence is not passed forward. This self-correction loop is a key difference from static RAG, reducing hallucinations by treating retrieved data as evidence to evaluate rather than truth to assume.
Level 3: Moving to Advanced Agentic RAG Architectures and Production Tradeoffs
Graph RAG and Structured Knowledge
Vector search in a vector database treats documents as independent chunks ranked by embedding similarity. This works when relevant information is self-contained within passages, but breaks down when queries require reasoning over relationships between entities — where the key is how entities across documents connect, not just what each document says.
Graph RAG builds a knowledge graph from documents and retrieves via graph traversal instead of embedding similarity. For domains where information is inherently relational — legal research, healthcare diagnostics, financial exposure analysis — Graph RAG consistently outperforms flat retrieval on complex reasoning tasks.
It improves performance on relationship-heavy queries but is expensive to build and maintain. It is best suited for stable, high-value data and is not well suited for simple or fast-changing datasets.
Read GraphRAG and Agentic Architecture: Practical Experimentation with Neo4j and NeoConverse for a practical approach to integrating Graph RAG in agentic applications.
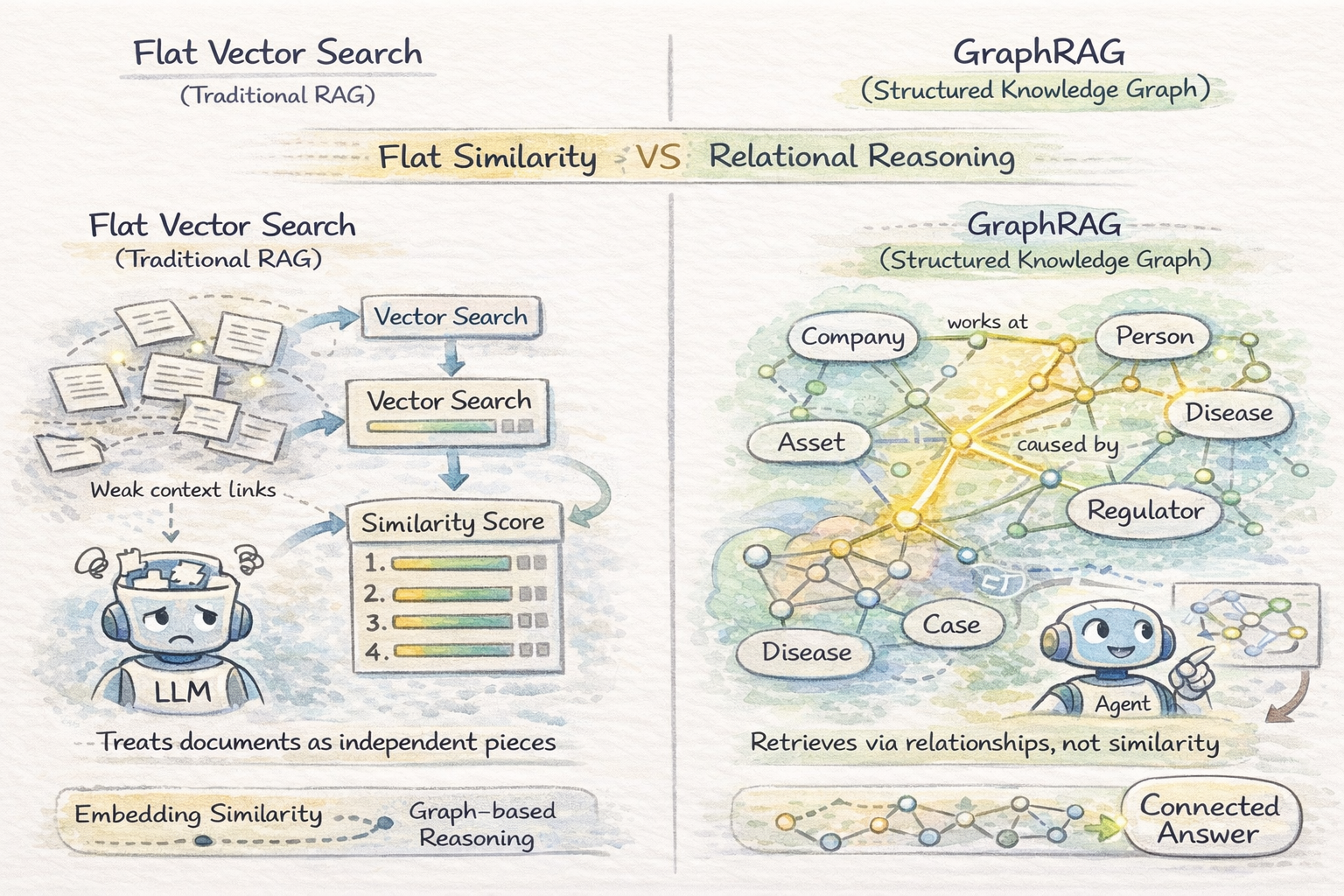
Vector Similarity Search vs Graph RAG
Reflection and Memory
Advanced agentic RAG systems add two mechanisms above the retrieval loop.
Reflection lets the agent review its draft answer for gaps, errors, or weak support and trigger further retrieval if needed.
Memory works at two levels: short-term memory tracks what has already been retrieved in a session, while long-term memory learns from past queries to improve future retrieval efficiency.
Together, reflection and memory push agentic RAG from a stateless retrieval loop toward something closer to a reasoning system with genuine operational history.
Vector Databases vs. Graph RAG for Agent Memory: When to Use Which is a useful resource for deciding between Graph RAG and vector databases for agentic memory.
So when is agentic RAG overkill? Agentic RAG is more powerful but slower and costlier than static RAG. It uses multiple LLM calls, so latency, token use, and failure risk all increase with complexity. A simple rule of thumb: use static RAG for single-hop factual queries and agentic RAG for multi-step reasoning or cross-source synthesis.
Conclusion
The defining insight of agentic RAG is straightforward: retrieval isn’t a single well-defined step — it’s an ongoing reasoning process. Basic RAG pipelines retrieve and generate. Agentic RAG systems retrieve, evaluate, iterate, and then generate, and the difference in output quality on complex queries is substantial. The tradeoffs in cost and latency are real, but for the class of questions that matter most in production, they’re worth it.
For further learning, you may find the following resources useful:
Happy learning!















