Most developers treat prompting as an afterthought—write something reasonable, observe the output, and iterate if needed. That approach works until reliability becomes critical. As LLMs move into production systems, the difference between a prompt that usually works and one that works consistently becomes an engineering concern. In response, the research community has formalized prompting into a set of well-defined techniques, each designed to address specific failure modes—whether in structure, reasoning, or style. These methods operate entirely at the prompt layer, requiring no fine-tuning, model changes, or infrastructure upgrades.
This article focuses on five such techniques: role-specific prompting, negative prompting, JSON prompting, Attentive Reasoning Queries (ARQ), and verbalized sampling. Rather than covering familiar baselines like zero-shot or basic chain-of-thought, the emphasis here is on what changes when these techniques are applied. Each is demonstrated through side-by-side comparisons on the same task, highlighting the impact on output quality and explaining the underlying mechanism.
Here, we’re setting up a minimal environment to interact with the OpenAI API. We securely load the API key at runtime using getpass, initialize the client, and define a lightweight chat wrapper to send system and user prompts to the model (gpt-4o-mini). This keeps our experimentation loop clean and reusable while focusing only on prompt variations.

The helper functions (section and divider) are just for formatting outputs, making it easier to compare baseline vs. improved prompts side by side. If you don’t already have an API key, you can create one from the official dashboard here: https://platform.openai.com/api-keys
import json
from openai import OpenAI
import os
from getpass import getpass
os.environ['OPENAI_API_KEY'] = getpass('Enter OpenAI API Key: ')
client = OpenAI()
MODEL = "gpt-4o-mini"
def chat(system: str, user: str, **kwargs) -> str:
"""Minimal wrapper around the chat completions endpoint."""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
**kwargs,
)
return response.choices[0].message.content
def section(title: str) -> None:
print()
print("=" * 60)
print(f" {title}")
print("=" * 60)
def divider(label: str) -> None:
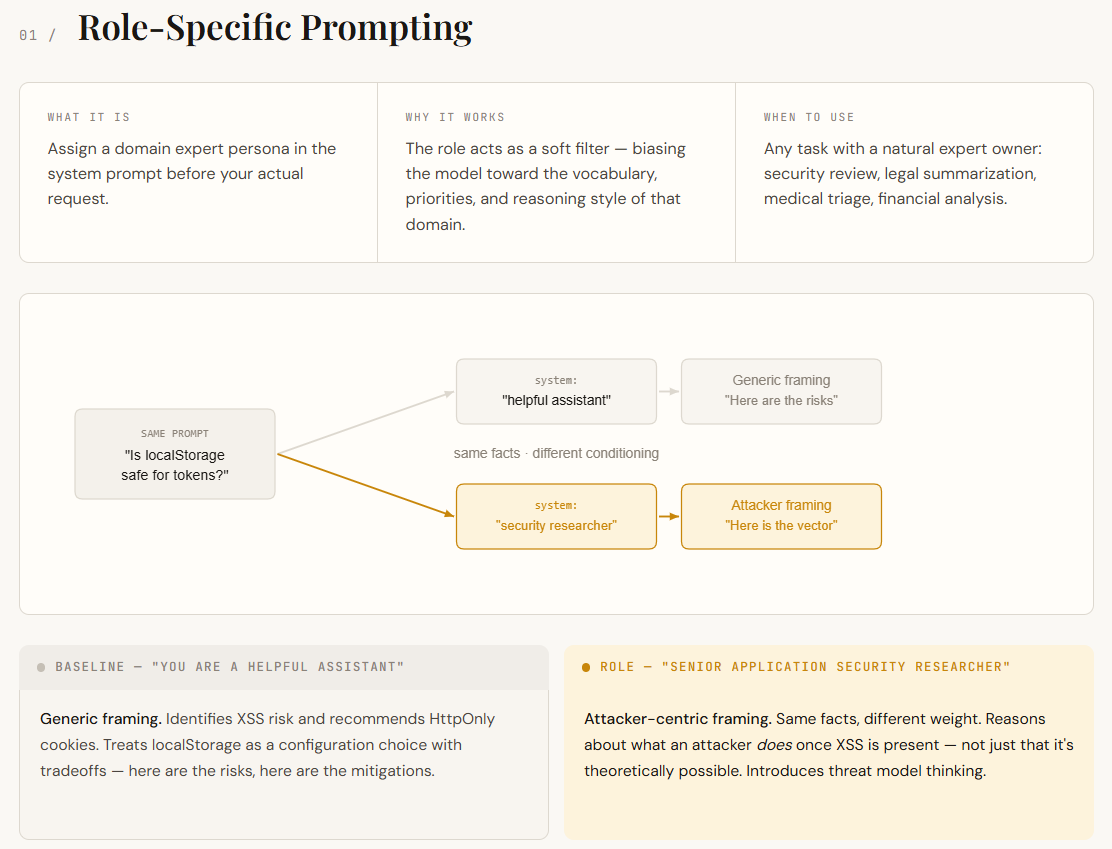
print(f"\n── {label} {'─' * (54 - len(label))}")Language models are trained on a wide mix of domains—security, marketing, legal, engineering, and more. When you don’t specify a role, the model pulls from all of them, which leads to answers that are generally correct but somewhat generic. Role-specific prompting fixes this by assigning a persona in the system prompt (e.g., “You are a senior application security researcher”). This acts like a filter, pushing the model to respond using the language, priorities, and reasoning style of that domain.
In this example, both responses identify the XSS risk and recommend HttpOnly cookies — the underlying facts are identical. The difference is in how the model frames the problem. The baseline treats localStorage as a configuration choice with tradeoffs. The role-specific response treats it as an attack surface: it reasons about what an attacker can do once XSS is present, not just that XSS is theoretically possible. That shift in framing — from “here are the risks” to “here is what an attacker does with those risks” — is the conditioning effect in action. No new information was provided. The prompt just changed which part of the model’s knowledge got weighted.
section("TECHNIQUE 1 -- Role-Specific Prompting")
QUESTION = "Our web app stores session tokens in localStorage. Is this a problem?"
baseline_1 = chat(
system="You are a helpful assistant.",
user=QUESTION,
)
role_specific = chat(
system=(
"You are a senior application security researcher specializing in "
"web authentication vulnerabilities. You think in terms of attack "
"surface, threat models, and OWASP guidelines."
),
user=QUESTION,
)
divider("Baseline")
print(baseline_1)
divider("Role-specific (security researcher)")
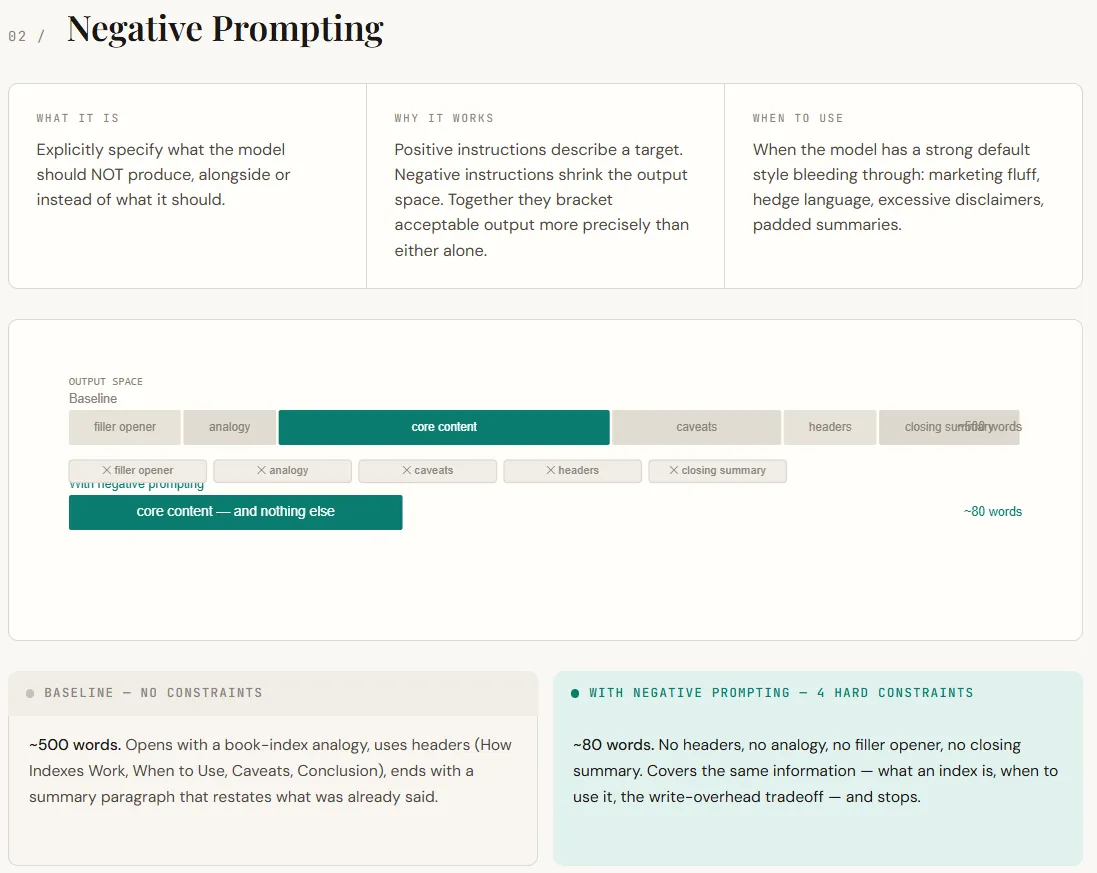
print(role_specific)Negative prompting focuses on telling the model what not to do. By default, LLMs follow patterns learned during training and RLHF—they add friendly openings, analogies, hedging (“it depends”), and closing summaries. While this makes responses feel helpful, it often adds unnecessary noise in technical contexts. Negative prompting works by removing these defaults. Instead of just describing the desired output, you also restrict unwanted behaviors, which narrows the model’s output space and leads to more precise responses.
In the output, the difference is immediately visible. The baseline response stretches into a longer, structured explanation with analogies, headers, and a redundant conclusion. The negatively prompted version delivers the same core information in a much shorter form—direct, concise, and without filler. Nothing essential is lost; the prompt simply removes the model’s tendency to over-explain and pad the response.
section("TECHNIQUE 2 -- Negative Prompting")
TOPIC = "Explain what a database index is and when you'd use one."
baseline_2 = chat(
system="You are a helpful assistant.",
user=TOPIC,
)
negative = chat(
system=(
"You are a senior backend engineer writing internal documentation.\n"
"Rules:\n"
"- Do NOT use marketing language or filler phrases like 'great question' or 'certainly'.\n"
"- Do NOT include caveats like 'it depends' without immediately resolving them.\n"
"- Do NOT use analogies unless they are necessary. If you use one, keep it to one sentence.\n"
"- Do NOT pad the response -- if you've made the point, stop.\n"
),
user=TOPIC,
)
divider("Baseline")
print(baseline_2)
divider("With negative prompting")
print(negative)JSON prompting becomes important when LLM outputs need to be consumed by code rather than just read by humans. Free-form responses are inconsistent—structure varies, key details are embedded in paragraphs, and small wording changes break parsing logic. By defining a JSON schema in the prompt, you turn structure into a hard constraint. This not only standardizes the output format but also forces the model to organize its reasoning into clearly defined fields like pros, cons, sentiment, and rating.
In the output, the difference is clear. The baseline response is readable but unstructured—pros, cons, and sentiment are mixed into narrative text, making it difficult to parse. The JSON-prompted version, however, returns clean, well-defined fields that can be directly loaded and used in code without any post-processing. Information that was previously implied is now explicit and separated, making the output easy to store, query, and compare at scale.

section("TECHNIQUE 3 -- JSON Prompting")
REVIEW = """
Honestly mixed feelings about this laptop. The display is stunning -- easily the best I've
seen at this price range -- and the keyboard is surprisingly comfortable for long sessions.
Battery life, on the other hand, barely gets me through a 6-hour workday, which is
disappointing. Fan noise under load is also pretty aggressive. For light work it's great,
but I wouldn't recommend it for anyone who needs to run heavy software.
"""
SCHEMA = """
{
"overall_sentiment": "positive | negative | mixed",
"rating": <integer 1-5>,
"pros": ["<string>", ...],
"cons": ["<string>", ...],
"recommended_for": "<string describing ideal user>",
"not_recommended_for": "<string describing user who should avoid>"
}
"""
baseline_3 = chat(
system="You are a helpful assistant.",
user=f"Summarize this product review:\n\n{REVIEW}",
)
json_output = chat(
system=(
"You are a product review parser. Extract structured information from reviews.\n"
"You MUST return only a valid JSON object. No preamble, no explanation, no markdown fences.\n"
f"The JSON must match this schema exactly:\n{SCHEMA}"
),
user=f"Parse this review:\n\n{REVIEW}",
)
divider("Baseline (free-form)")
print(baseline_3)
divider("JSON prompting (raw output)")
print(json_output)
divider("Parsed & usable in code")
parsed = json.loads(json_output)
print(f"Sentiment : {parsed['overall_sentiment']}")
print(f"Rating : {parsed['rating']}/5")
print(f"Pros : {', '.join(parsed['pros'])}")
print(f"Cons : {', '.join(parsed['cons'])}")
print(f"Recommended for : {parsed['recommended_for']}")
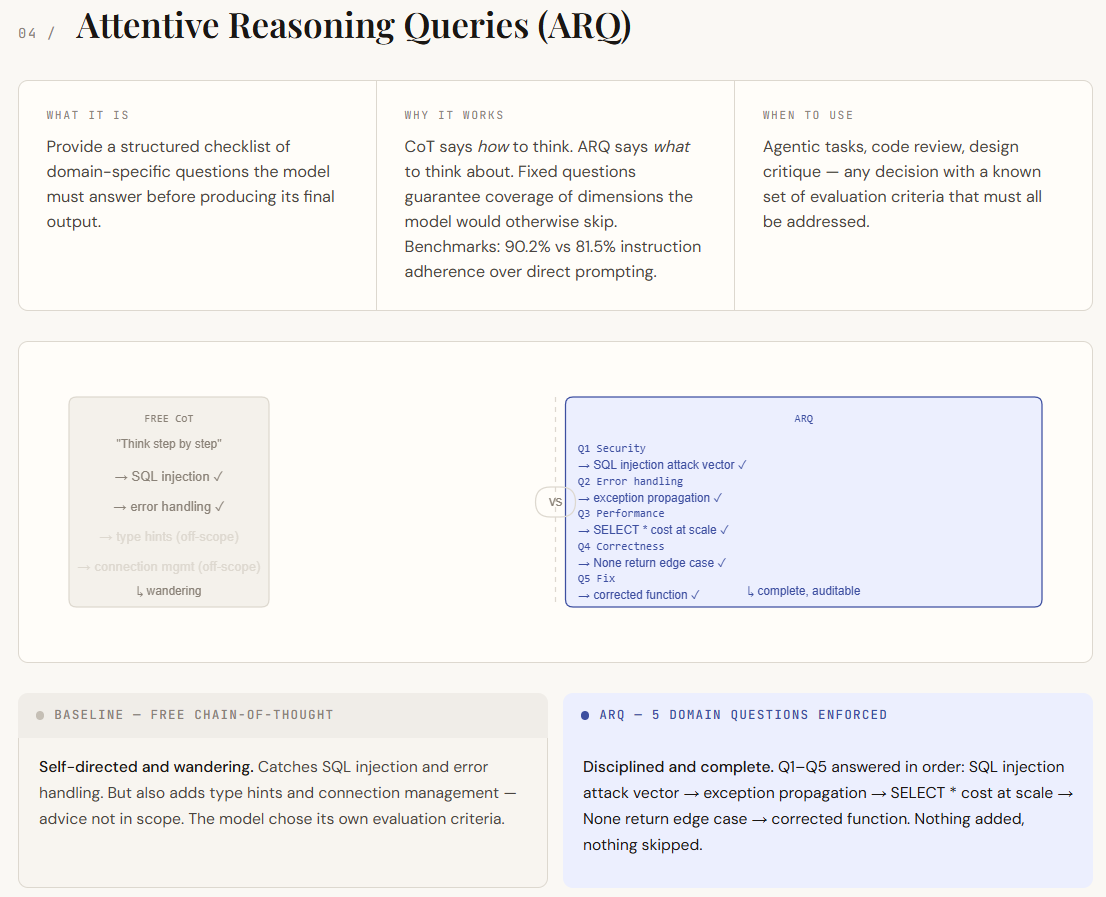
print(f"Avoid if : {parsed['not_recommended_for']}")Attentive Reasoning Queries (ARQ) build on chain-of-thought prompting but remove its biggest weakness—unstructured reasoning. In standard CoT, the model decides what to focus on, which can lead to gaps or irrelevant details. ARQ replaces this with a fixed set of domain-specific questions that the model must answer in order. This ensures that all critical aspects are covered, shifting control from the model to the prompt designer. Instead of just guiding how the model thinks, ARQ defines what it must think about.
In the output, the difference shows up as discipline and coverage. The baseline CoT response identifies key issues but drifts into less relevant areas and misses deeper analysis in places. The ARQ version, however, systematically addresses each required point—clearly isolating vulnerabilities, handling edge cases, and evaluating performance implications. Each question acts as a checkpoint, making the response more structured, complete, and easier to audit.
section("TECHNIQUE 4 -- Attentive Reasoning Queries (ARQ)")
CODE_TO_REVIEW = """
def get_user(user_id):
query = f"SELECT * FROM users WHERE id = {user_id}"
result = db.execute(query)
return result[0] if result else None
"""
ARQ_QUESTIONS = """
Before giving your final review, answer each of the following questions in order:
Q1 [Security]: Does this code have any injection vulnerabilities?
If yes, describe the exact attack vector.
Q2 [Error handling]: What happens if db.execute() throws an exception?
Is that acceptable?
Q3 [Performance]: Does this query retrieve more data than necessary?
What is the cost at scale?
Q4 [Correctness]: Are there edge cases in the return logic that could
cause a silent bug downstream?
Q5 [Fix]: Write a corrected version of the function that addresses
all issues found above.
"""
baseline_cot = chat(
system="You are a senior software engineer. Think step by step.",
user=f"Review this Python function:\n\n{CODE_TO_REVIEW}",
)
arq_result = chat(
system="You are a senior software engineer conducting a security-aware code review.",
user=f"Review this Python function:\n\n{CODE_TO_REVIEW}\n\n{ARQ_QUESTIONS}",
)
divider("Baseline (free CoT)")
print(baseline_cot)
divider("ARQ (structured reasoning checklist)")
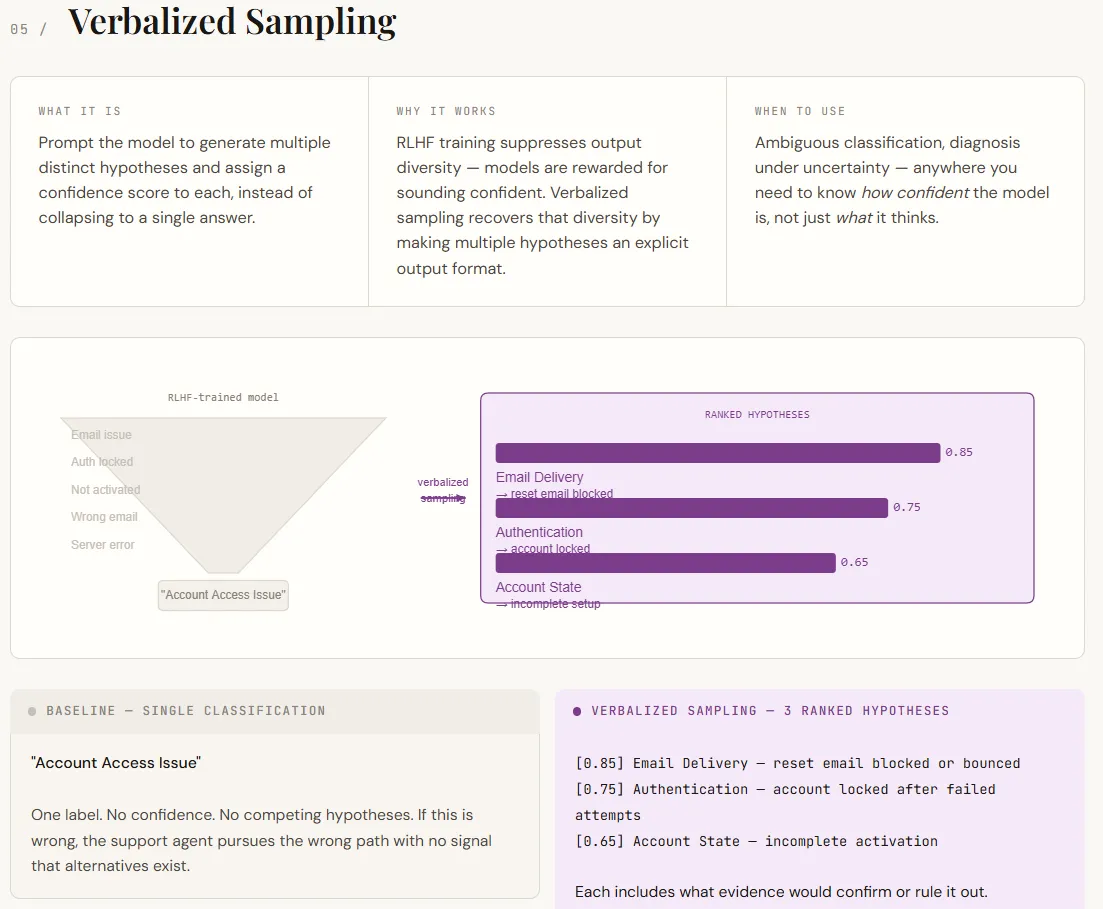
print(arq_result)Verbalized sampling addresses a key limitation of LLMs: they tend to return a single, confident answer even when multiple interpretations are possible. This happens because alignment training favors decisive outputs. As a result, the model hides its internal uncertainty. Verbalized sampling fixes this by explicitly asking for multiple hypotheses, along with confidence rankings and supporting evidence. Instead of forcing one answer, it surfaces a range of plausible outcomes—all within the prompt, without needing model changes.
In the output, this shifts the result from a single label to a structured diagnostic view. The baseline provides one classification with no indication of uncertainty. The verbalized version, however, lists multiple ranked hypotheses, each with an explanation and a way to validate or reject it. This makes the output more actionable, turning it into a decision-making aid rather than just an answer. The confidence scores themselves aren’t precise probabilities, but they effectively indicate relative likelihood, which is often sufficient for prioritization and downstream workflows.
section("TECHNIQUE 5 -- Verbalized Sampling")
SUPPORT_TICKET = """
Hi, I set up my account last week but I can't log in anymore. I tried resetting
my password but the email never arrives. I also tried a different browser. Nothing works.
"""
baseline_5 = chat(
system="You are a support ticket classifier. Classify the issue.",
user=f"Ticket:\n{SUPPORT_TICKET}",
)
verbalized = chat(
system=(
"You are a support ticket classifier.\n"
"For each ticket, generate 3 distinct hypotheses about the root cause. "
"For each hypothesis:\n"
" - State the category (Authentication, Email Delivery, Account State, Browser/Client, Other)\n"
" - Describe the specific failure mode\n"
" - Assign a confidence score from 0.0 to 1.0\n"
" - State what additional information would confirm or rule it out\n\n"
"Order hypotheses by confidence (highest first). "
"Then provide a recommended first action for the support agent."
),
user=f"Ticket:\n{SUPPORT_TICKET}",
)
divider("Baseline (single answer)")
print(baseline_5)
divider("Verbalized sampling (multiple hypotheses + confidence)")
print(verbalized)Check out the Full Codes with Notebook here. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us

I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various areas.