Mistral AI has released Mistral Small 4, a new model in the Mistral Small family designed to consolidate several previously separate capabilities into a single deployment target. Mistral team describes Small 4 as its first model to combine the roles associated with Mistral Small for instruction following, Magistral for reasoning, Pixtral for multimodal understanding, and Devstral for agentic coding. The result is a single model that can operate as a general assistant, a reasoning model, and a multimodal system without requiring model switching across workflows.
Architecture: 128 Experts, Sparse Activation
Architecturally, Mistral Small 4 is a Mixture-of-Experts (MoE) model with 128 experts and 4 active experts per token. The model has 119B total parameters, with 6B active parameters per token, or 8B including embedding and output layers.
Long Context and Multimodal Support
The model supports a 256k context window, which is a meaningful jump for practical engineering use cases. Long-context capacity matters less as a marketing number and more as an operational simplifier: it reduces the need for aggressive chunking, retrieval orchestration, and context pruning in tasks such as long-document analysis, codebase exploration, multi-file reasoning, and agentic workflows. Mistral positions the model for general chat, coding, agentic tasks, and complex reasoning, with text and image inputs and text output. That places Small 4 in the increasingly important category of general-purpose models that are expected to handle both language-heavy and visually grounded enterprise tasks under one API surface.
Configurable Reasoning at Inference Time
A more important product decision than the raw parameter count is the introduction of configurable reasoning effort. Small 4 exposes a per-request reasoning_effort parameter that allows developers to trade latency for deeper test-time reasoning. In the official documentation, reasoning_effort="none" is described as producing fast responses with a chat style equivalent to Mistral Small 3.2, while reasoning_effort="high" is intended for more deliberate, step-by-step reasoning with verbosity comparable to earlier Magistral models. This changes the deployment pattern. Instead of routing between one fast model and one reasoning model, dev teams can keep a single model in service and vary inference behavior at request time. That is cleaner from a systems perspective and easier to manage in products where only a subset of queries actually need expensive reasoning.
Performance Claims and Throughput Positioning
Mistral team also emphasizes inference efficiency. Small 4 delivers a 40% reduction in end-to-end completion time in a latency-optimized setup and 3x more requests per second in a throughput-optimized setup, both measured against Mistral Small 3. Mistral is not presenting Small 4 as just a larger reasoning model, but as a system aimed at improving the economics of deployment under real serving loads.
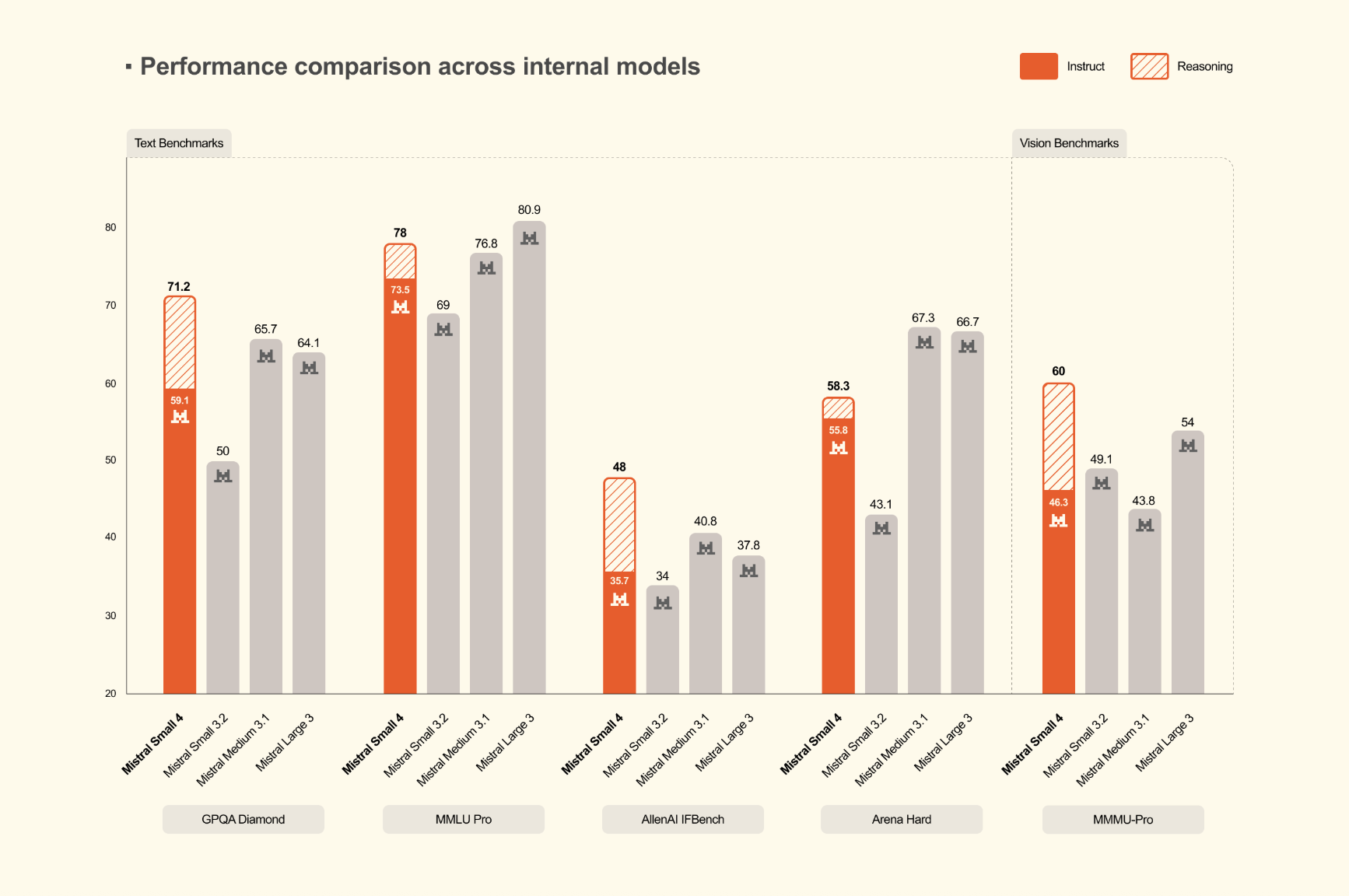
Benchmark Results and Output Efficiency
On reasoning benchmarks, Mistral’s release focuses on both quality and output efficiency. The Mistral’s research team reports that Mistral Small 4 with reasoning matches or exceeds GPT-OSS 120B across AA LCR, LiveCodeBench, and AIME 2025, while generating shorter outputs. In the numbers published by Mistral, Small 4 scores 0.72 on AA LCR with 1.6K characters, while Qwen models require 5.8K to 6.1K characters for comparable performance. On LiveCodeBench, Mistral team states that Small 4 outperforms GPT-OSS 120B while producing 20% less output. These are company-published results, but they highlight a more practical metric than benchmark score alone: performance per generated token. For production workloads, shorter outputs can directly reduce latency, inference cost, and downstream parsing overhead.
Deployment Details
For self-hosting, Mistral gives specific infrastructure guidance. The company lists a minimum deployment target of 4x NVIDIA HGX H100, 2x NVIDIA HGX H200, or 1x NVIDIA DGX B200, with larger configurations recommended for best performance. The model card on HuggingFace lists support across vLLM, llama.cpp, SGLang, and Transformers, though some paths are marked work in progress, and vLLM is the recommended option. Mistral team also provides a custom Docker image and notes that fixes related to tool calling and reasoning parsing are still being upstreamed. That is useful detail for engineering teams because it clarifies that support exists, but some pieces are still stabilizing in the broader open-source serving stack.
Key Takeaways
- One unified model: Mistral Small 4 combines instruct, reasoning, multimodal, and agentic coding capabilities in one model.
- Sparse MoE design: It uses 128 experts with 4 active experts per token, targeting better efficiency than dense models of similar total size.
- Long-context support: The model supports a 256k context window and accepts text and image inputs with text output.
- Reasoning is configurable: Developers can adjust
reasoning_effortat inference time instead of routing between separate fast and reasoning models. - Open deployment focus: It is released under Apache 2.0 and supports serving through stacks such as vLLM, with multiple checkpoint variants on Hugging Face.
Check out Model Card on HF and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.