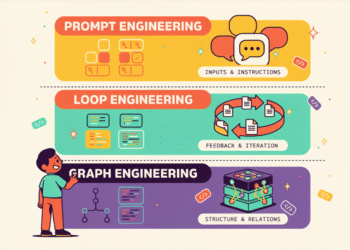
In this tutorial, we explore Hydra, an advanced configuration management framework originally developed and open-sourced by Meta Research. We begin by defining structured configurations using Python dataclasses, which allows us to manage experiment parameters in a clean, modular, and reproducible manner. As we move through the tutorial, we compose configurations, apply runtime overrides, and simulate multirun experiments for hyperparameter sweeps. Check out the FULL CODES here.
import subprocess
import sys
subprocess.check_call([sys.executable, "-m", "pip", "install", "-q", "hydra-core"])
import hydra
from hydra import compose, initialize_config_dir
from omegaconf import OmegaConf, DictConfig
from dataclasses import dataclass, field
from typing import List, Optional
import os
from pathlib import PathWe begin by installing Hydra and importing all the essential modules required for structured configurations, dynamic composition, and file handling. This setup ensures our environment is ready to execute the full tutorial seamlessly on Google Colab. Check out the FULL CODES here.
@dataclass
class OptimizerConfig:
_target_: str = "torch.optim.SGD"
lr: float = 0.01
@dataclass
class AdamConfig(OptimizerConfig):
_target_: str = "torch.optim.Adam"
lr: float = 0.001
betas: tuple = (0.9, 0.999)
weight_decay: float = 0.0
@dataclass
class SGDConfig(OptimizerConfig):
_target_: str = "torch.optim.SGD"
lr: float = 0.01
momentum: float = 0.9
nesterov: bool = True
@dataclass
class ModelConfig:
name: str = "resnet"
num_layers: int = 50
hidden_dim: int = 512
dropout: float = 0.1
@dataclass
class DataConfig:
dataset: str = "cifar10"
batch_size: int = 32
num_workers: int = 4
augmentation: bool = True
@dataclass
class TrainingConfig:
model: ModelConfig = field(default_factory=ModelConfig)
data: DataConfig = field(default_factory=DataConfig)
optimizer: OptimizerConfig = field(default_factory=AdamConfig)
epochs: int = 100
seed: int = 42
device: str = "cuda"
experiment_name: str = "exp_001"We define clean, type-safe configurations using Python dataclasses for the model, data, and optimizer settings. This structure allows us to manage complex experiment parameters in a modular and readable way while ensuring consistency across runs. Check out the FULL CODES here.
def setup_config_dir():
config_dir = Path("./hydra_configs")
config_dir.mkdir(exist_ok=True)
main_config = """
defaults:
- model: resnet
- data: cifar10
- optimizer: adam
- _self_
epochs: 100
seed: 42
device: cuda
experiment_name: exp_001
"""
(config_dir / "config.yaml").write_text(main_config)
model_dir = config_dir / "model"
model_dir.mkdir(exist_ok=True)
(model_dir / "resnet.yaml").write_text("""
name: resnet
num_layers: 50
hidden_dim: 512
dropout: 0.1
""")
(model_dir / "vit.yaml").write_text("""
name: vision_transformer
num_layers: 12
hidden_dim: 768
dropout: 0.1
patch_size: 16
""")
data_dir = config_dir / "data"
data_dir.mkdir(exist_ok=True)
(data_dir / "cifar10.yaml").write_text("""
dataset: cifar10
batch_size: 32
num_workers: 4
augmentation: true
""")
(data_dir / "imagenet.yaml").write_text("""
dataset: imagenet
batch_size: 128
num_workers: 8
augmentation: true
""")
opt_dir = config_dir / "optimizer"
opt_dir.mkdir(exist_ok=True)
(opt_dir / "adam.yaml").write_text("""
_target_: torch.optim.Adam
lr: 0.001
betas: [0.9, 0.999]
weight_decay: 0.0
""")
(opt_dir / "sgd.yaml").write_text("""
_target_: torch.optim.SGD
lr: 0.01
momentum: 0.9
nesterov: true
""")
return str(config_dir.absolute())We programmatically create a directory containing YAML configuration files for models, datasets, and optimizers. This approach enables us to demonstrate how Hydra automatically composes configurations from different files, thereby maintaining flexibility and clarity in experiments. Check out the FULL CODES here.
@hydra.main(version_base=None, config_path="hydra_configs", config_name="config")
def train(cfg: DictConfig) -> float:
print("=" * 80)
print("CONFIGURATION")
print("=" * 80)
print(OmegaConf.to_yaml(cfg))
print("\n" + "=" * 80)
print("ACCESSING CONFIGURATION VALUES")
print("=" * 80)
print(f"Model: {cfg.model.name}")
print(f"Dataset: {cfg.data.dataset}")
print(f"Batch Size: {cfg.data.batch_size}")
print(f"Optimizer LR: {cfg.optimizer.lr}")
print(f"Epochs: {cfg.epochs}")
best_acc = 0.0
for epoch in range(min(cfg.epochs, 3)):
acc = 0.5 + (epoch * 0.1) + (cfg.optimizer.lr * 10)
best_acc = max(best_acc, acc)
print(f"Epoch {epoch+1}/{cfg.epochs}: Accuracy = {acc:.4f}")
return best_accWe implement a training function that leverages Hydra’s configuration system to print, access, and use nested config values. By simulating a simple training loop, we showcase how Hydra cleanly integrates experiment control into real workflows. Check out the FULL CODES here.
def demo_basic_usage():
print("\n" + "🚀 DEMO 1: Basic Configuration\n")
config_dir = setup_config_dir()
with initialize_config_dir(version_base=None, config_dir=config_dir):
cfg = compose(config_name="config")
print(OmegaConf.to_yaml(cfg))
def demo_config_override():
print("\n" + "🚀 DEMO 2: Configuration Overrides\n")
config_dir = setup_config_dir()
with initialize_config_dir(version_base=None, config_dir=config_dir):
cfg = compose(
config_name="config",
overrides=[
"model=vit",
"data=imagenet",
"optimizer=sgd",
"optimizer.lr=0.1",
"epochs=50"
]
)
print(OmegaConf.to_yaml(cfg))
def demo_structured_config():
print("\n" + "🚀 DEMO 3: Structured Config Validation\n")
from hydra.core.config_store import ConfigStore
cs = ConfigStore.instance()
cs.store(name="training_config", node=TrainingConfig)
with initialize_config_dir(version_base=None, config_dir=setup_config_dir()):
cfg = compose(config_name="config")
print(f"Config type: {type(cfg)}")
print(f"Epochs (validated as int): {cfg.epochs}")
def demo_multirun_simulation():
print("\n" + "🚀 DEMO 4: Multirun Simulation\n")
config_dir = setup_config_dir()
experiments = [
["model=resnet", "optimizer=adam", "optimizer.lr=0.001"],
["model=resnet", "optimizer=sgd", "optimizer.lr=0.01"],
["model=vit", "optimizer=adam", "optimizer.lr=0.0001"],
]
results = {}
for i, overrides in enumerate(experiments):
print(f"\n--- Experiment {i+1} ---")
with initialize_config_dir(version_base=None, config_dir=config_dir):
cfg = compose(config_name="config", overrides=overrides)
print(f"Model: {cfg.model.name}, Optimizer: {cfg.optimizer._target_}")
print(f"Learning Rate: {cfg.optimizer.lr}")
results[f"exp_{i+1}"] = cfg
return results
def demo_interpolation():
print("\n" + "🚀 DEMO 5: Variable Interpolation\n")
cfg = OmegaConf.create({
"model": {"name": "resnet", "layers": 50},
"experiment": "${model.name}_${model.layers}",
"output_dir": "/outputs/${experiment}",
"checkpoint": "${output_dir}/best.ckpt"
})
print(OmegaConf.to_yaml(cfg))
print(f"\nResolved experiment name: {cfg.experiment}")
print(f"Resolved checkpoint path: {cfg.checkpoint}")We demonstrate Hydra’s advanced capabilities, including config overrides, structured config validation, multi-run simulations, and variable interpolation. Each demo showcases how Hydra accelerates experimentation speed, streamlines manual setup, and fosters reproducibility in research. Check out the FULL CODES here.
if __name__ == "__main__":
demo_basic_usage()
demo_config_override()
demo_structured_config()
demo_multirun_simulation()
demo_interpolation()
print("\n" + "=" * 80)
print("Tutorial complete! Key takeaways:")
print("✓ Config composition with defaults")
print("✓ Runtime overrides via command line")
print("✓ Structured configs with type safety")
print("✓ Multirun for hyperparameter sweeps")
print("✓ Variable interpolation")
print("=" * 80)We execute all demonstrations in sequence to observe Hydra in action, from loading configs to performing multiruns. By the end, we summarize key takeaways, reinforcing how Hydra enables scalable and elegant experiment management.
In conclusion, we grasp how Hydra, pioneered by Meta Research, simplifies and enhances experiment management through its powerful composition system. We explore structured configs, interpolation, and multirun capabilities that make large-scale machine learning workflows more flexible and maintainable. With this knowledge, you are now equipped to integrate Hydra into your own research or development pipelines, ensuring reproducibility, efficiency, and clarity in every experiment you run.
Check out the FULL CODES here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.