In this article, you will learn how temperature and seed values influence failure modes in agentic loops, and how to tune them for greater resilience.
Topics we will cover include:
- How low and high temperature settings can produce distinct failure patterns in agentic loops.
- Why fixed seed values can undermine robustness in production environments.
- How to use temperature and seed adjustments to build more resilient and cost-effective agent workflows.
Let’s not waste any more time.
Why Agents Fail: The Role of Seed Values and Temperature in Agentic Loops
Image by Editor
Introduction
In the modern AI landscape, an agent loop is a cyclic, repeatable, and continuous process whereby an entity called an AI agent — with a certain degree of autonomy — works toward a goal.
In practice, agent loops now wrap a large language model (LLM) inside them so that, instead of reacting only to single-user prompt interactions, they implement a variation of the Observe-Reason-Act cycle defined for classic software agents decades ago.
Agents are, of course, not infallible, and they may sometimes fail, in some cases due to poor prompting or a lack of access to the external tools they need to reach a goal. However, two invisible steering mechanisms can also influence failure: temperature and seed value. This article analyzes both from the perspective of failure in agent loops.
Let’s take a closer look at how these settings may relate to failure in agentic loops through a gentle discussion backed by recent research and production diagnoses.
Temperature: “Reasoning Drift” Vs. “Deterministic Loop”
Temperature is an inherent parameter of LLMs, and it controls randomness in their internal behavior when selecting the words, or tokens, that make up the model’s response. The higher its value (closer to 1, assuming a range between 0 and 1), the less deterministic and more unpredictable the model’s outputs become, and vice versa.
In agentic loops, because LLMs sit at the core, understanding temperature is crucial to understanding unique, well-documented failure modes that may arise, particularly when the temperature is extremely low or high.
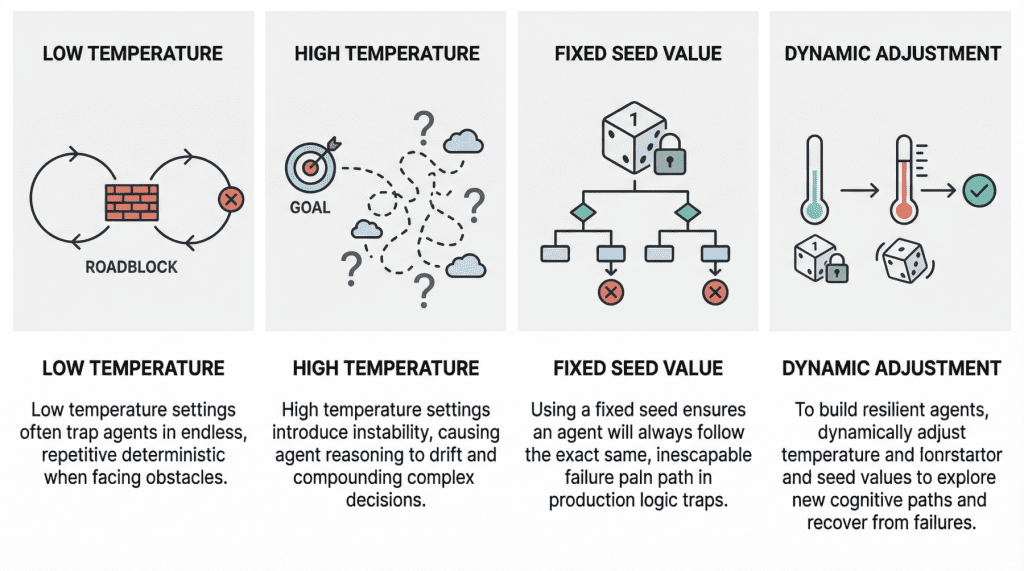
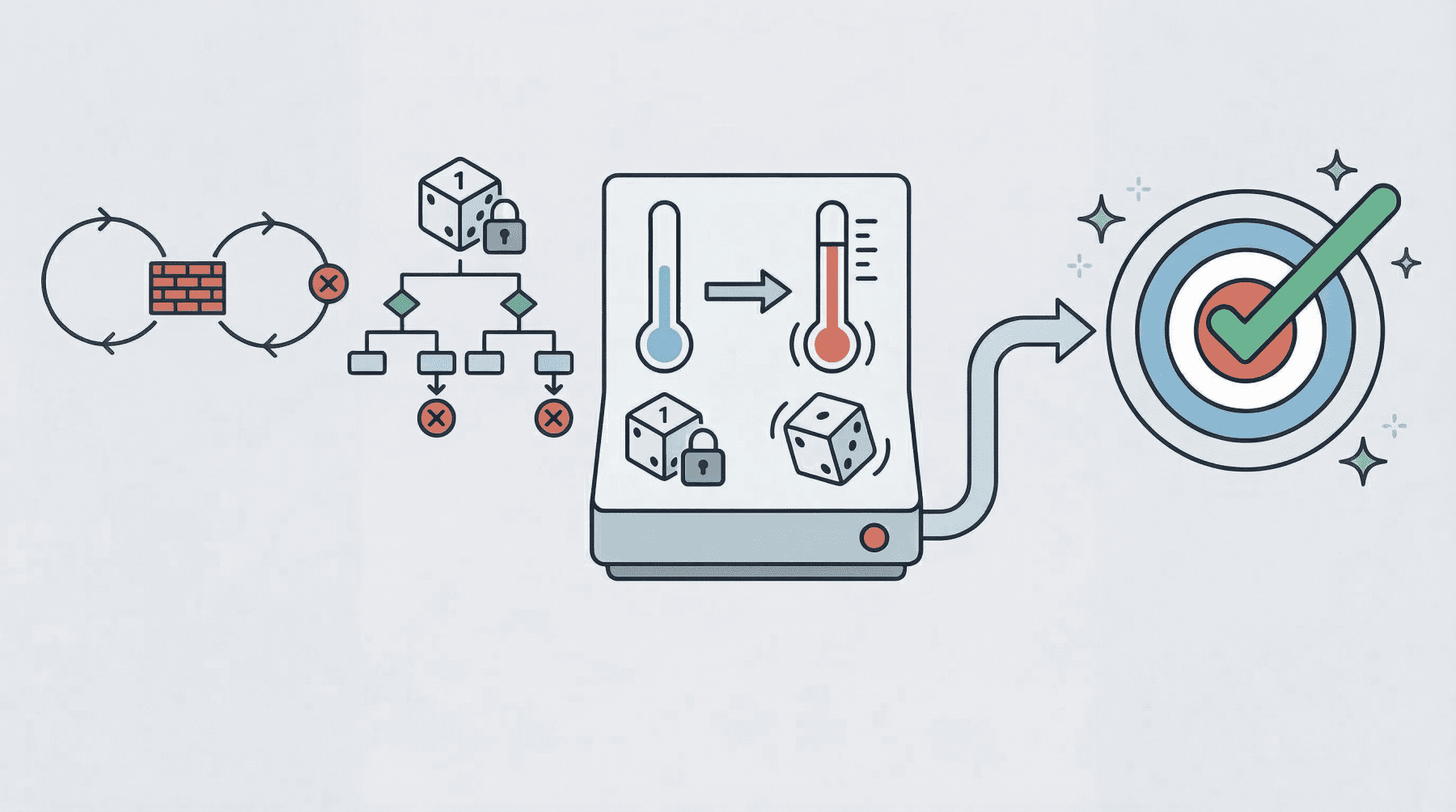
A low-temperature (near 0) agent often yields the so-called deterministic loop failure. In other words, the agent’s behavior becomes too rigid. Suppose the agent comes across a “roadblock” on its path, such as a third-party API consistently returning an error. With a low temperature and exceedingly deterministic behavior, it lacks the kind of cognitive randomness or exploration needed to pivot. Recent studies have scientifically analyzed this phenomenon. The practical consequences typically observed range from agents finalizing missions prematurely to failing to coordinate when their initial plans encounter friction, thus ending up in loops of the same attempts over and over without any progress.
At the opposite end of the spectrum, we have high-temperature (0.8 or above) agentic loops. As with standalone LLMs, high temperature introduces a much broader range of possibilities when sampling each element of the response. In a multi-step loop, however, this highly probabilistic behavior may compound in a dangerous way, turning into a trait known as reasoning drift. In essence, this behavior boils down to instability in decision-making. Introducing high-temperature randomness into complex agent workflows may cause agent-based models to lose their way — that is, lose their original selection criteria for making decisions. This may include symptoms such as hallucinations (fabricated reasoning chains) or even forgetting the user’s initial goal.
Seed Value: Reproducibility
Seed values are the mechanisms that initialize the pseudo-random generator used to build the model’s outputs. Put more simply, the seed value is like the starting position of a die that is rolled to kickstart the model’s word-selection mechanism governing response generation.
Regarding this setting, the main problem that usually causes failure in agent loops is using a fixed seed in production. A fixed seed is reasonable in a testing environment, for example, for the sake of reproducibility in tests and experiments, but allowing it to make its way into production introduces a significant vulnerability. An agent may inadvertently enter a logic trap when it operates with a fixed seed. In such a situation, the system may automatically trigger a recovery attempt, but even then, the fixed seed is almost synonymous with guaranteeing that the agent will take the same reasoning path doomed to failure over and over again.
In practical terms, imagine an agent tasked with debugging a failed deployment by inspecting logs, proposing a fix, and then retrying the operation. If the loop runs with a fixed seed, the stochastic choices made by the model during each reasoning step may remain effectively “locked” into the same pattern every time recovery is triggered. As a result, the agent may keep selecting the same flawed interpretation of the logs, calling the same tool in the same order, or generating the same ineffective fix despite repeated retries. What looks like persistence at the system level is, in reality, repetition at the cognitive level. This is why resilient agent architectures often treat the seed as a controllable recovery lever: when the system detects that the agent is stuck, changing the seed can help force exploration of a different reasoning trajectory, increasing the chances of escaping a local failure mode rather than reproducing it indefinitely.
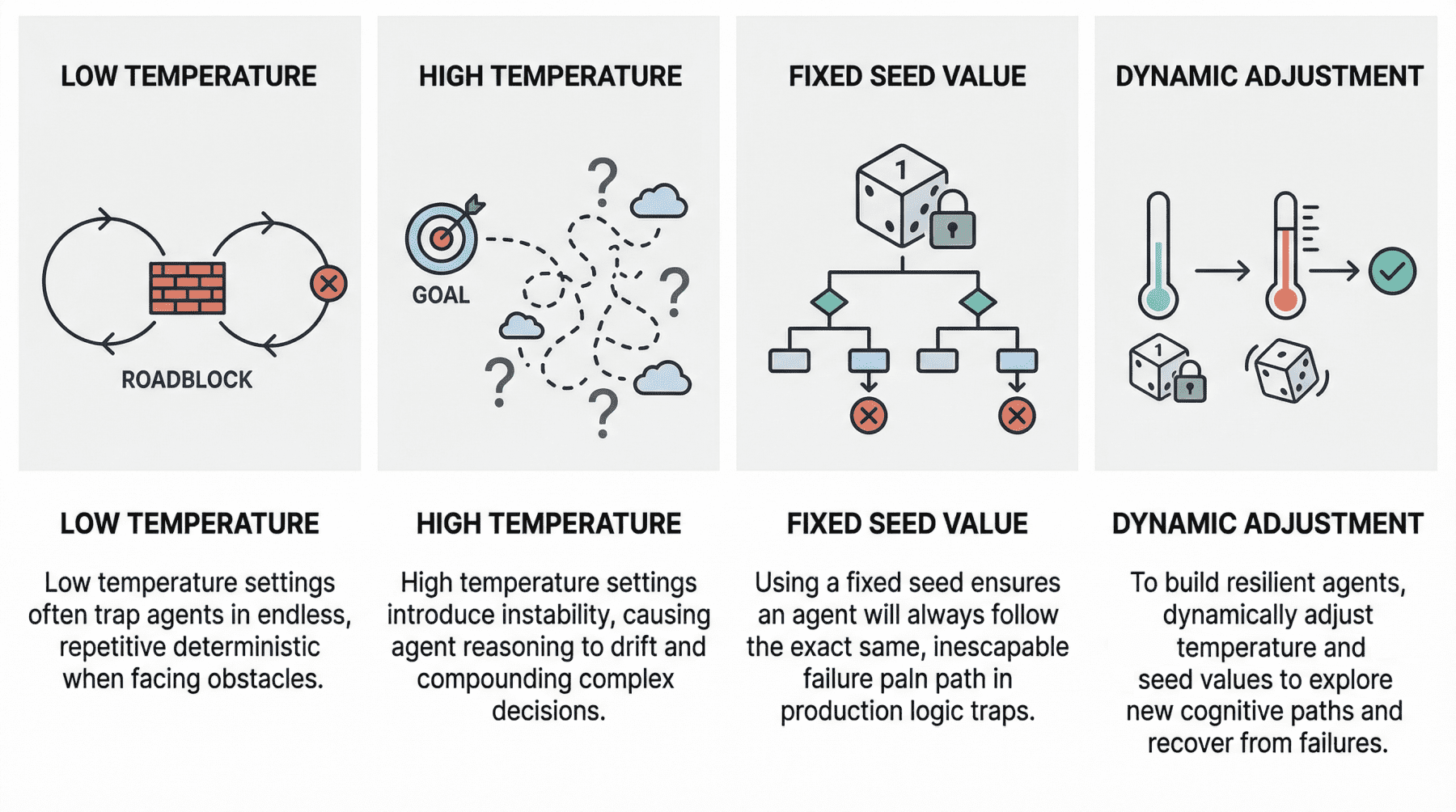
A summary of the role of seed values and temperature in agentic loops
Image by Editor
Best Practices For Resilient And Cost-Effective Loops
Having learned about the impact that temperature and seed value may have in agent loops, one might wonder how to make these loops more resilient to failure by carefully setting these two parameters.
Basically, breaking out of failure in agentic loops often entails changing the seed value or temperature as part of retry efforts to seek a different cognitive path. Resilient agents usually implement approaches that dynamically adjust these parameters in edge cases, for instance by temporarily raising the temperature or randomizing the seed if an analysis of the agent’s state suggests it is stuck. The bad news is that this can become very expensive to test when commercial APIs are used, which is why open-weight models, local models, and local model runners such as Ollama become critical in these scenarios.
Implementing a flexible agentic loop with adjustable settings makes it possible to simulate many loops and run stress tests across diverse temperature and seed combinations. When done with cost-free tools, this becomes a practical path to discovering the root causes of reasoning failures before deployment.