In the world of voice AI, the difference between a helpful assistant and an awkward interaction is measured in milliseconds. While text-based Retrieval-Augmented Generation (RAG) systems can afford a few seconds of ‘thinking’ time, voice agents must respond within a 200ms budget to maintain a natural conversational flow. Standard production vector database queries typically add 50-300ms of network latency, effectively consuming the entire budget before an LLM even begins generating a response.
Salesforce AI research team has released VoiceAgentRAG, an open-source dual-agent architecture designed to bypass this retrieval bottleneck by decoupling document fetching from response generation.
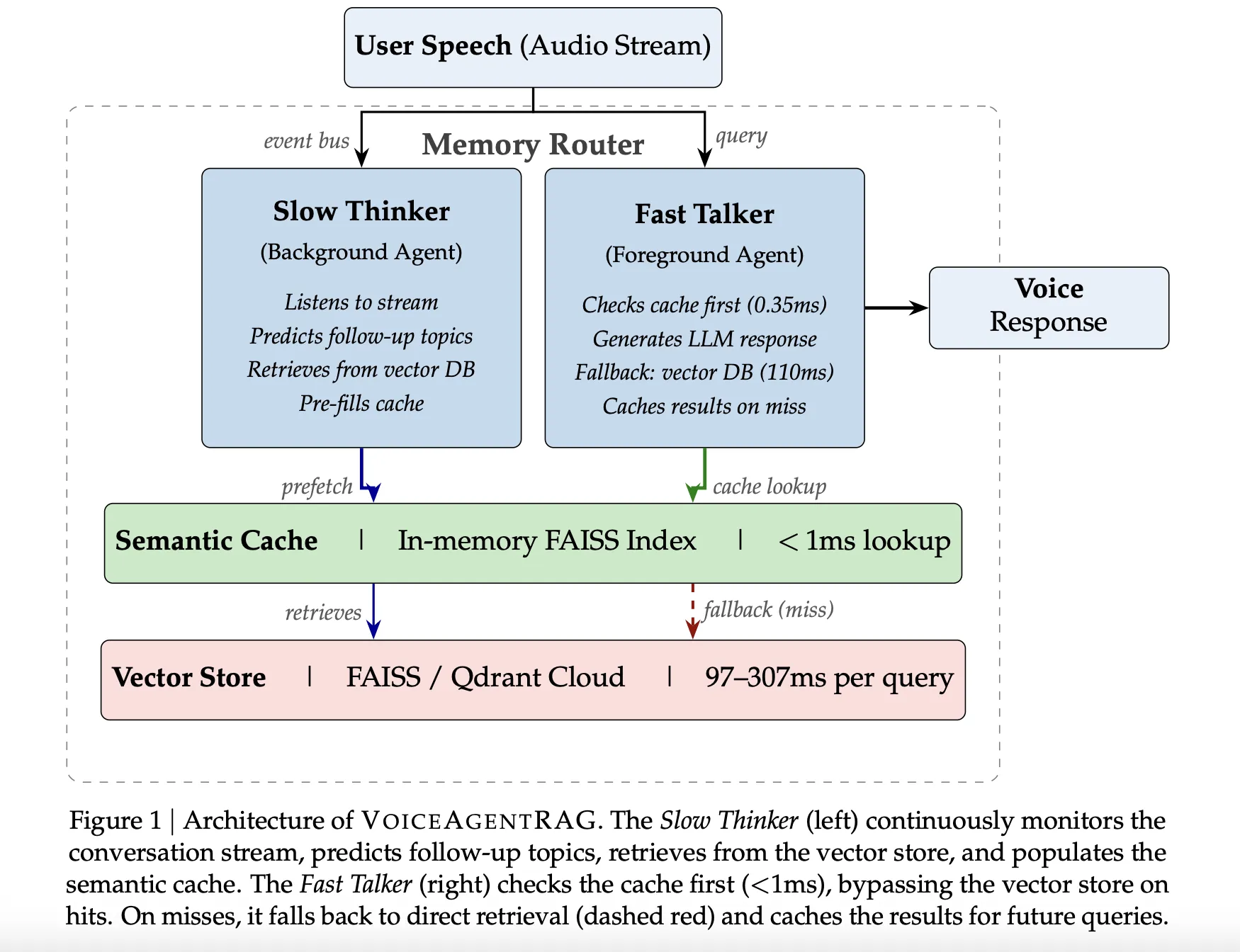
The Dual-Agent Architecture: Fast Talker vs. Slow Thinker
VoiceAgentRAG operates as a memory router that orchestrates two concurrent agents via an asynchronous event bus:
- The Fast Talker (Foreground Agent): This agent handles the critical latency path. For every user query, it first checks a local, in-memory Semantic Cache. If the required context is present, the lookup takes approximately 0.35ms. On a cache miss, it falls back to the remote vector database and immediately caches the results for future turns.
- The Slow Thinker (Background Agent): Running as a background task, this agent continuously monitors the conversation stream. It uses a sliding window of the last six conversation turns to predict 3–5 likely follow-up topics. It then pre-fetches relevant document chunks from the remote vector store into the local cache before the user even speaks their next question.
To optimize search accuracy, the Slow Thinker is instructed to generate document-style descriptions rather than questions. This ensures the resulting embeddings align more closely with the actual prose found in the knowledge base.
The Technical Backbone: Semantic Caching
The system’s efficiency hinges on a specialized semantic cache implemented with an in-memory FAISS IndexFlat IP (inner product).
- Document-Embedding Indexing: Unlike passive caches that index by query meaning, VoiceAgentRAG indexes entries by their own document embeddings. This allows the cache to perform a proper semantic search over its contents, ensuring relevance even if the user’s phrasing differs from the system’s predictions.
- Threshold Management: Because query-to-document cosine similarity is systematically lower than query-to-query similarity, the system uses a default threshold of to balance precision and recall.
- Maintenance: The cache detects near-duplicates using a 0.95 cosine similarity threshold and employs a Least Recently Used (LRU) eviction policy with a 300-second Time-To-Live (TTL).
- Priority Retrieval: On a Fast Talker cache miss, a
PriorityRetrievalevent triggers the Slow Thinker to perform an immediate retrieval with an expanded top-k (2x the default) to rapidly populate the cache around the new topic area.
Benchmarks and Performance
The research team evaluated the system using Qdrant Cloud as a remote vector database across 200 queries and 10 conversation scenarios.
| Metric | Performance |
| Overall Cache Hit Rate | 75% (79% on warm turns) |
| Retrieval Speedup | 316x |
| Total Retrieval Time Saved | 16.5 seconds over 200 turns |
The architecture is most effective in topically coherent or sustained-topic scenarios. For example, ‘Feature comparison’ (S8) achieved a 95% hit rate. Conversely, performance dipped in more volatile scenarios; the lowest-performing scenario was ‘Existing customer upgrade’ (S9) at a 45% hit rate, while ‘Mixed rapid-fire’ (S10) maintained 55%.
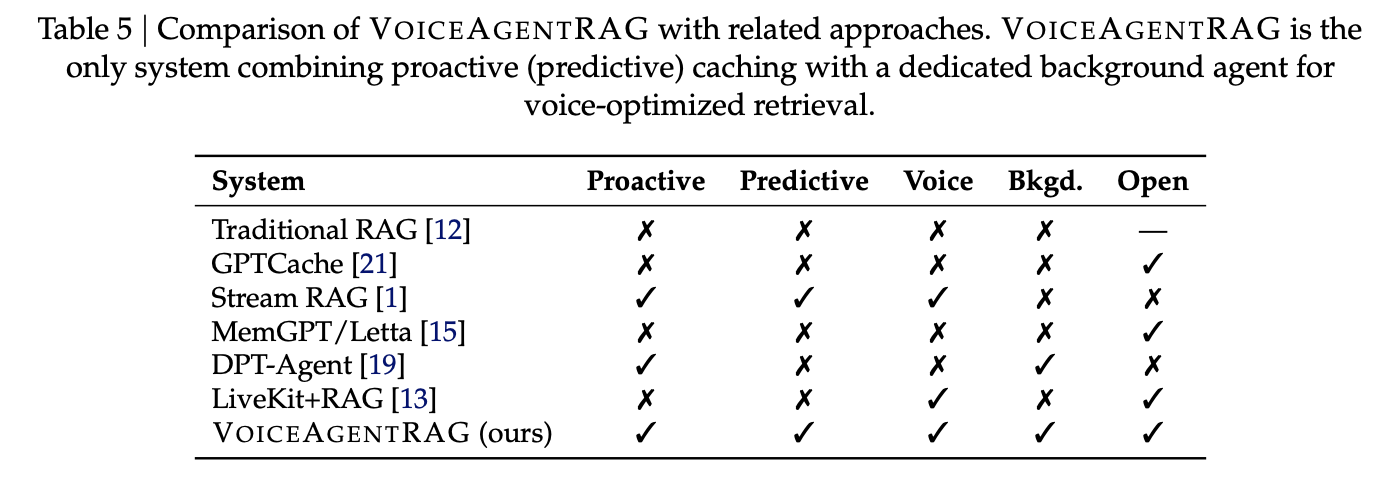
Integration and Support
The VoiceAgentRAG repository is designed for broad compatibility across the AI stack:
- LLM Providers: Supports OpenAI, Anthropic, Gemini/Vertex AI, and Ollama. The paper’s default evaluation model was GPT-4o-mini.
- Embeddings: The research utilized OpenAI text-embedding-3-small (1536 dimensions), but the repository provides support for both OpenAI and Ollama embeddings.
- STT/TTS: Supports Whisper (local or OpenAI) for speech-to-text and Edge TTS or OpenAI for text-to-speech.
- Vector Stores: Built-in support for FAISS and Qdrant.
Key Takeaways
- Dual-Agent Architecture: The system solves the RAG latency bottleneck by using a foreground ‘Fast Talker’ for sub-millisecond cache lookups and a background ‘Slow Thinker’ for predictive pre-fetching.
- Significant Speedup: It achieves a 316x retrieval speedup on cache hits, which is critical for staying within the natural 200ms voice response budget.
- High Cache Efficiency: Across diverse scenarios, the system maintains a 75% overall cache hit rate, peaking at 95% in topically coherent conversations like feature comparisons.
- Document-Indexed Caching: To ensure accuracy regardless of user phrasing, the semantic cache indexes entries by document embeddings rather than the predicted query’s embedding.
- Anticipatory Prefetching: The background agent uses a sliding window of the last 6 conversation turns to predict likely follow-up topics and populate the cache during natural inter-turn pauses.
Check out the Paper and Repo here. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.