Recursive Language Models aim to break the usual trade off between context length, accuracy and cost in large language models. Instead of forcing a model to read a giant prompt in one pass, RLMs treat the prompt as an external environment and let the model decide how to inspect it with code, then recursively call itself on smaller pieces.
The Basics
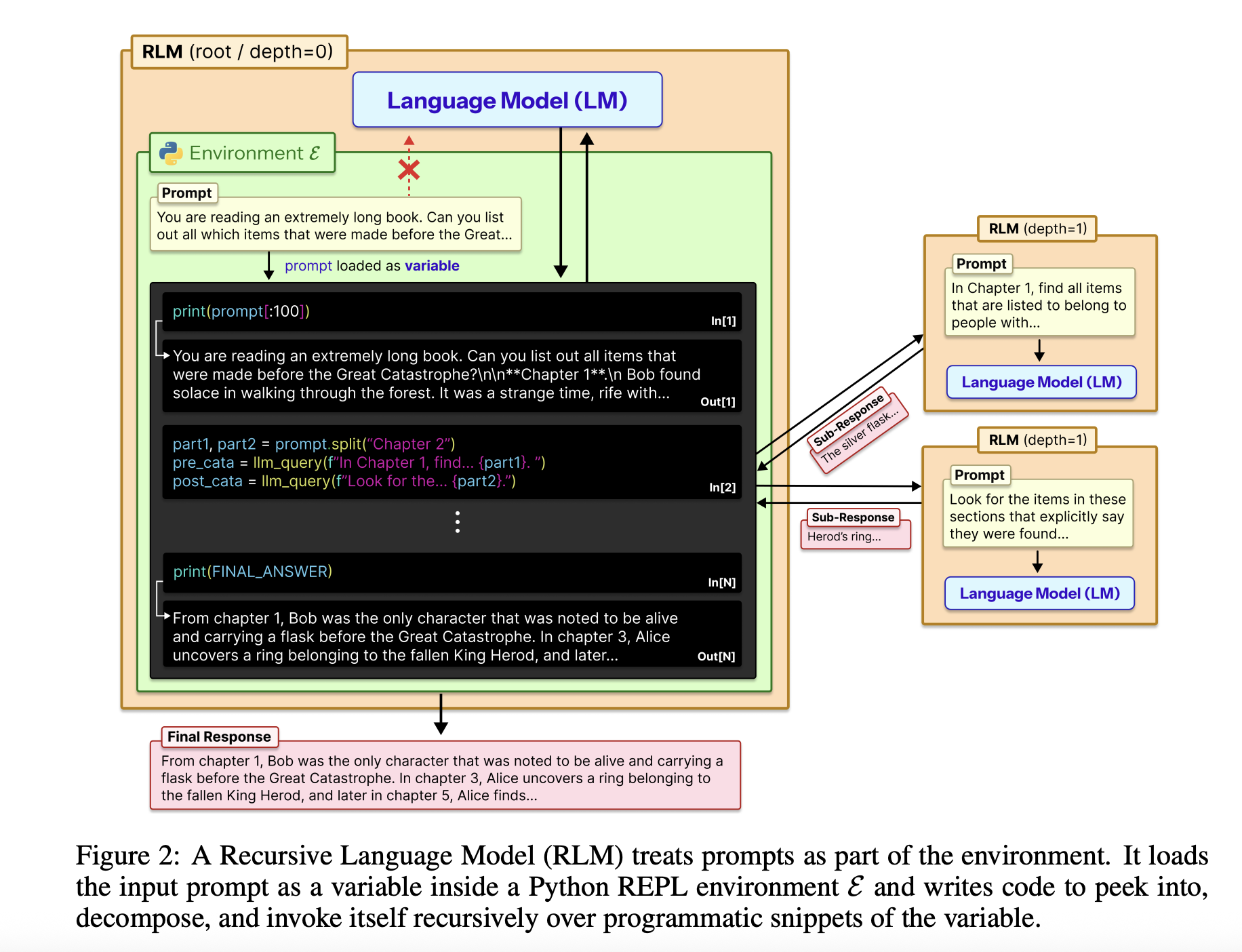
The full input is loaded into a Python REPL as a single string variable. The root model, for example GPT-5, never sees that string directly in its context. Instead, it receives a system prompt that explains how to read slices of the variable, write helper functions, spawn sub LLM calls, and combine results. The model returns a final text answer, so the external interface stays identical to a standard chat completion endpoint.
The RLM design uses the REPL as a control plane for long context. The environment, usually written in Python, exposes tools such as string slicing, regex search and helper functions like llm_query that call a smaller model instance, for example GPT-5-mini. The root model writes code that calls these helpers to scan, partition and summarize the external context variable. The code can store intermediate results in variables and build up the final answer step by step. This structure makes the prompt size independent from the model context window and turns long context handling into a program synthesis problem.
Where it stands in Evaluation?
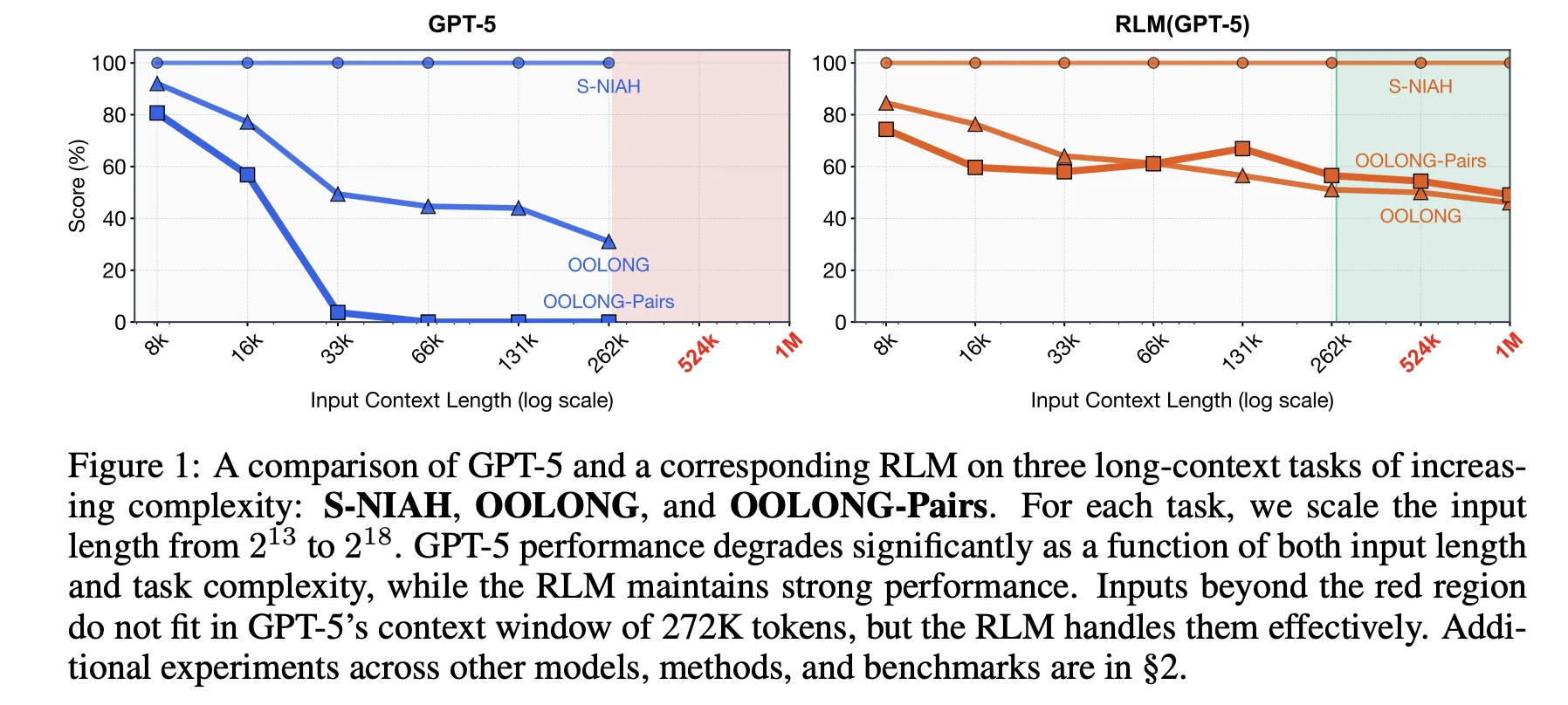
The research paper evaluates this idea on four long context benchmarks with different computational structure. S-NIAH is a constant complexity needle in a haystack task. BrowseComp-Plus is a multi hop web style question answering benchmark over up to 1,000 documents. OOLONG is a linear complexity long context reasoning task where the model must transform many entries and then aggregate them. OOLONG Pairs increases the difficulty further with quadratic pairwise aggregation over the input. These tasks stress both context length and reasoning depth, not only retrieval.
On these benchmarks, RLMs give large accuracy gains over direct LLM calls and common long context agents. For GPT-5 on CodeQA, a long document question answering setup, the base model reaches 24.00 accuracy, a summarization agent reaches 41.33, while RLM reaches 62.00 and the RLM without recursion reaches 66.00. For Qwen3-Coder-480B-A35B, the base model scores 20.00, a CodeAct retrieval agent 52.00, and the RLM 56.00 with a REPL only variant at 44.66.
The gains are largest on the hardest setting, OOLONG Pairs. For GPT-5, the direct model is almost unusable with F1 equal to 0.04. Summarization and CodeAct agents sit near 0.01 and 24.67. The full RLM reaches 58.00 F1 and the non recursive REPL variant still achieves 43.93. For Qwen3-Coder, the base model stays below 0.10 F1, while the full RLM reaches 23.11 and the REPL only version 17.34. These numbers show that both the REPL and recursive sub calls are critical on dense quadratic tasks.
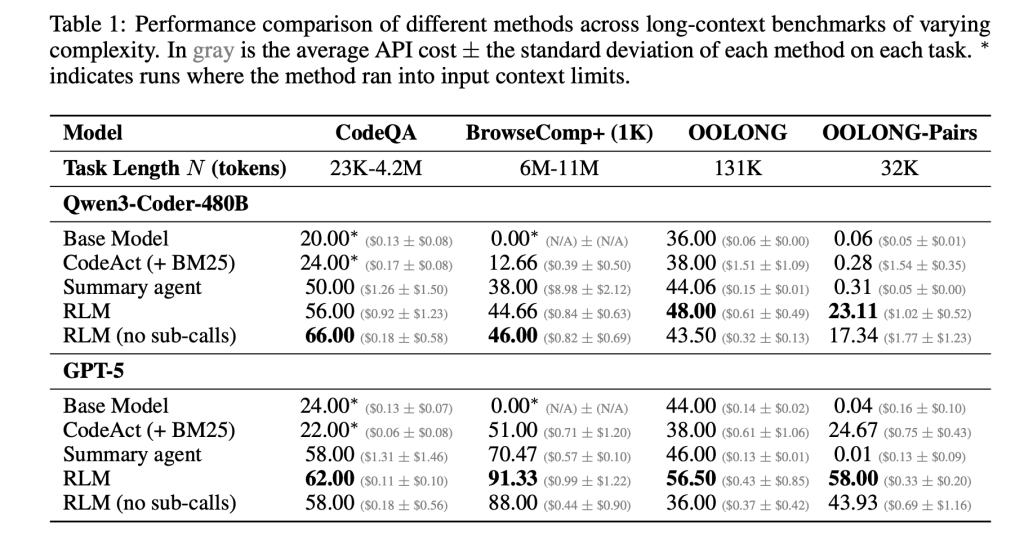
BrowseComp-Plus highlights effective context extension. The corpus ranges from about 6M to 11M tokens, which is 2 orders of magnitude beyond the 272k token context window of GPT-5. RLM with GPT 5 maintains strong performance even when given 1,000 documents in the environment variable, while standard GPT-5 baselines degrade as document count grows. On this benchmark, RLM GPT 5 achieves around 91.33 accuracy with an average cost of 0.99 USD per query, while a hypothetical model that reads the full context directly would cost between $1.50 and $2.75 at current pricing.
The research paper also analyzes the trajectories of RLM runs. Several behavior patterns emerge. The model often starts with a peek step where it inspects the first few thousand characters of the context. It then uses grep style filtering with regex or keyword search to narrow down relevant lines. For more complex queries, it partitions the context into chunks and calls recursive LMs on each chunk to perform labeling or extraction, followed by programmatic aggregation. On long output tasks, the RLM stores partial outputs in variables and stitches them together, which bypasses output length limits of the base model.
The new take from Prime Intellect
Prime Intellect team has turned this concept into a concrete environment, RLMEnv, integrated in their verifiers stack and Environments Hub. In their design, the main RLM has only a Python REPL, while sub LLMs receive the heavy tools such as web search or file access. The REPL exposes an llm_batch function so the root model can fan out many sub queries in parallel, and an answer variable where the final solution must be written and flagged as ready. This isolates token heavy tool outputs from the main context and lets the RLM delegate expensive operations to sub models.
Prime Intellect evaluates this implementation on four environments. DeepDive tests web research with search and open tools and very verbose pages. Math python exposes a Python REPL for difficult competition style math problems. Oolong reuses the long context benchmark inside RLMEnv. Verbatim copy focuses on exact reproduction of complex strings across content types such as JSON, CSV and mixed codes. Across these environments, GPT-5-mini and the INTELLECT-3-MoE model both gain from the RLM scaffold in success rate and in robustness to very long contexts, especially when tool output would otherwise swamp the model context
The research paper’s author team and Prime Intellect team both stress that current implementations are not fully optimized. RLM calls are synchronous, recursion depth is limited and cost distributions have heavy tails due to very long trajectories. The real opportunity is to combine RLM scaffolding with dedicated reinforcement learning so that models learn better chunking, recursion and tool usage policies over time. If that happens, RLMs provide a framework where improvements in base models and in systems design convert directly into more capable long horizon agents that can consume 10M plus token environments without context rot.
Key Takeaways
Here are 5 concise, technical takeaways you can plug under the article.
- RLMs reframe long context as an environment variable: Recursive Language Models treat the entire prompt as an external string in a Python style REPL, which the LLM inspects and transforms through code, instead of ingesting all tokens directly into the Transformer context.
- Inference time recursion extends context to 10M plus tokens: RLMs let a root model recursively call sub LLMs on selected snippets of the context, which enables effective processing of prompts up to about 2 orders of magnitude longer than the base context window, reaching 10M plus tokens on BrowseComp-Plus style workloads.
- RLMs outperform common long context scaffolds on hard benchmarks: Across S-NIAH, BrowseComp-Plus, OOLONG and OOLONG Pairs, RLM variants of GPT-5 and Qwen3-Coder improve accuracy and F1 over direct model calls, retrieval agents such as CodeAct, and summarization agents, while keeping per query cost comparable or lower.
- REPL only variants already help, recursion is critical for quadratic tasks: An ablation that only exposes the REPL without recursive sub calls still boosts performance on some tasks, which shows the value of offloading context into the environment, but full RLMs are required to achieve large gains on information dense settings such as OOLONG Pairs.
- Prime Intellect operationalizes RLMs through RLMEnv and INTELLECT 3: Prime Intellect team implements the RLM paradigm as RLMEnv, where the root LM controls a sandboxed Python REPL, calls tools via sub LMs and writes the final result to an
answervariable, and reports consistent gains on DeepDive, math python, Oolong and verbatim copy environments with models such as INTELLECT-3.
Check out the Paper and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.