
The Rising Need for Scalable Reasoning Models in Machine Intelligence
Advanced reasoning models are at the frontier of machine intelligence, especially in domains like math problem-solving and symbolic reasoning. These models are designed to perform multi-step calculations and logical deductions, often generating solutions that mirror human reasoning processes. Reinforcement learning techniques are used to improve accuracy after pretraining; however, scaling these methods while retaining efficiency remains a complex challenge. As demand increases for smaller, more resource-efficient models that still exhibit high reasoning capability, researchers are now turning to strategies that address data quality, exploration methods, and long-context generalization.
Challenges in Reinforcement Learning for Large Reasoning Architectures
A persistent problem with reinforcement learning for large-scale reasoning models is the mismatch between the model’s capability and the difficulty of the training data. When a model is exposed to tasks that are too simple, its learning curve stagnates. Conversely, overly difficult data can overwhelm the model and yield no learning signal. This difficulty imbalance is especially pronounced when applying recipes that work well for small models to larger ones. Another issue is the lack of methods to efficiently adapt rollout diversity and output length during both training and inference, which further constrains a model’s reasoning abilities on complex benchmarks.
Limitations of Existing Post-Training Approaches on Advanced Models
Earlier approaches, such as DeepScaleR and GRPO, have demonstrated that reinforcement learning can improve the performance of small-scale reasoning models with as few as 1.5 billion parameters. However, applying these same recipes to more capable models, such as Qwen3-4B or Deepseek-R1-Distill-Qwen-7B, results in only marginal gains or even performance drops. One key limitation is the static nature of data distribution and the limited diversity of sampling. Most of these approaches do not filter data based on model capability, nor do they adjust sampling temperature or response length over time. As a result, they often fail to scale effectively when used on more advanced architectures.
Introducing Polaris: A Tailored Recipe for Scalable RL in Reasoning Tasks
Researchers from the University of Hong Kong, Bytedance Seed, and Fudan University introduced Polaris, a post-training recipe designed specifically to scale reinforcement learning for advanced reasoning tasks. Polaris includes two preview models: Polaris-4B-Preview and Polaris-7B-Preview. Polaris-4B-Preview is fine-tuned from Qwen3-4B, while Polaris-7B-Preview is based on Deepseek-R1-Distill-Qwen-7B. The researchers focused on building a model-agnostic framework that modifies data difficulty, encourages diverse exploration through controlled sampling temperatures, and extends inference capabilities through length extrapolation. These strategies were developed using open-source datasets and training pipelines, and both models are optimized to run on consumer-grade graphics processing units (GPUs).
Polaris Innovations: Difficulty Balancing, Controlled Sampling, and Long-Context Inference
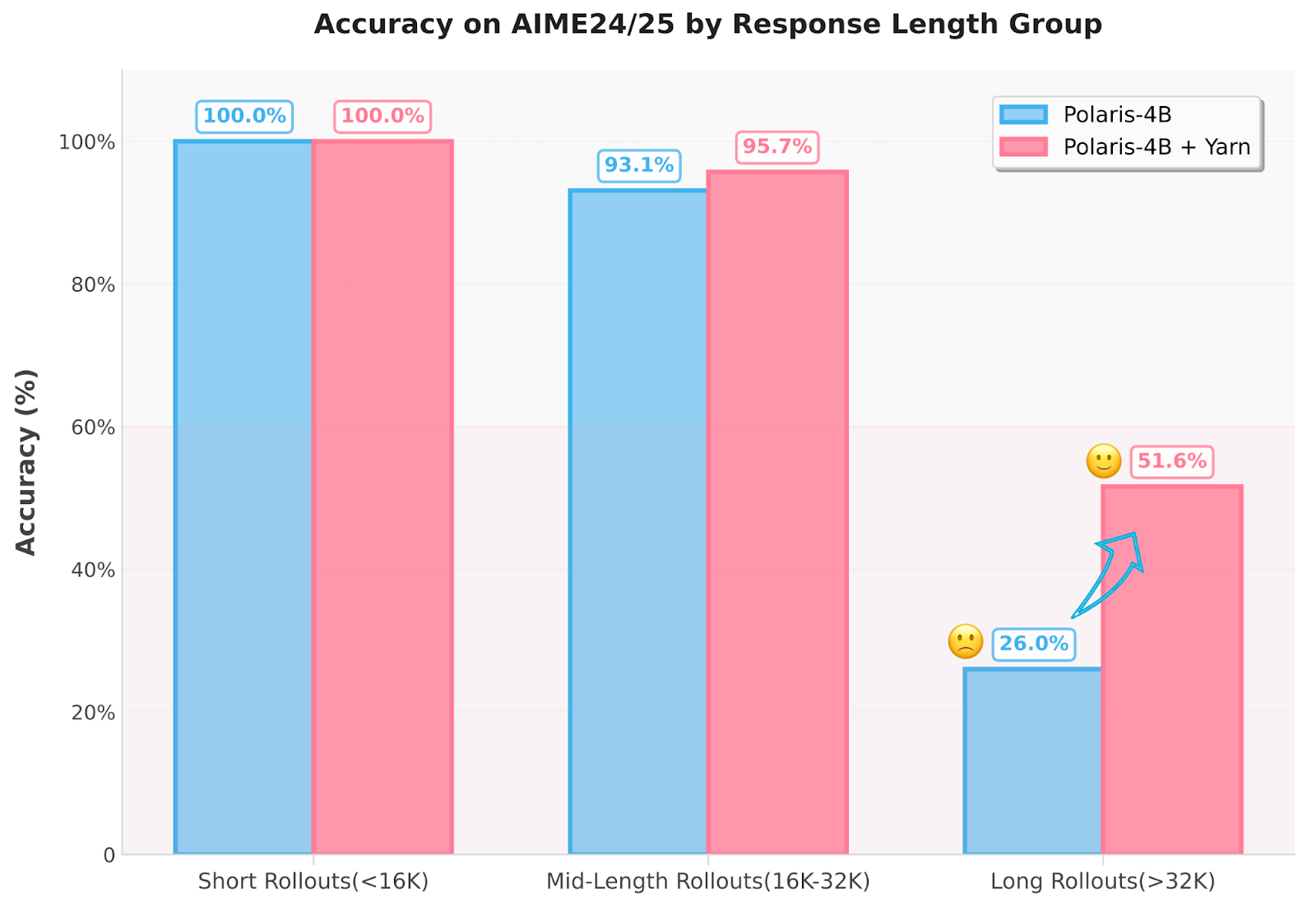
Polaris implements multiple innovations. First, the training data is curated by removing problems that are either too easy or unsolvable, creating a mirrored J-shape distribution of difficulty. This ensures that the training data evolves with the model’s growing capabilities. Second, the researchers dynamically adjust the sampling temperature across training stages—using 1.4, 1.45, and 1.5 for Polaris-4B and 0.7, 1.0, and 1.1 for Polaris-7B—to maintain rollout diversity. Furthermore, the method employs a Yarn-based extrapolation technique to extend the inference context length to 96K tokens without requiring additional training. This addresses the inefficiency of long-sequence training by enabling a “train-short, test-long” approach. The model also employs techniques such as the Rollout Rescue Mechanism and Intra-Batch Informative Substitution to prevent zero-reward batches and ensure that useful training signals are preserved, even when the rollout size is kept small at 8.
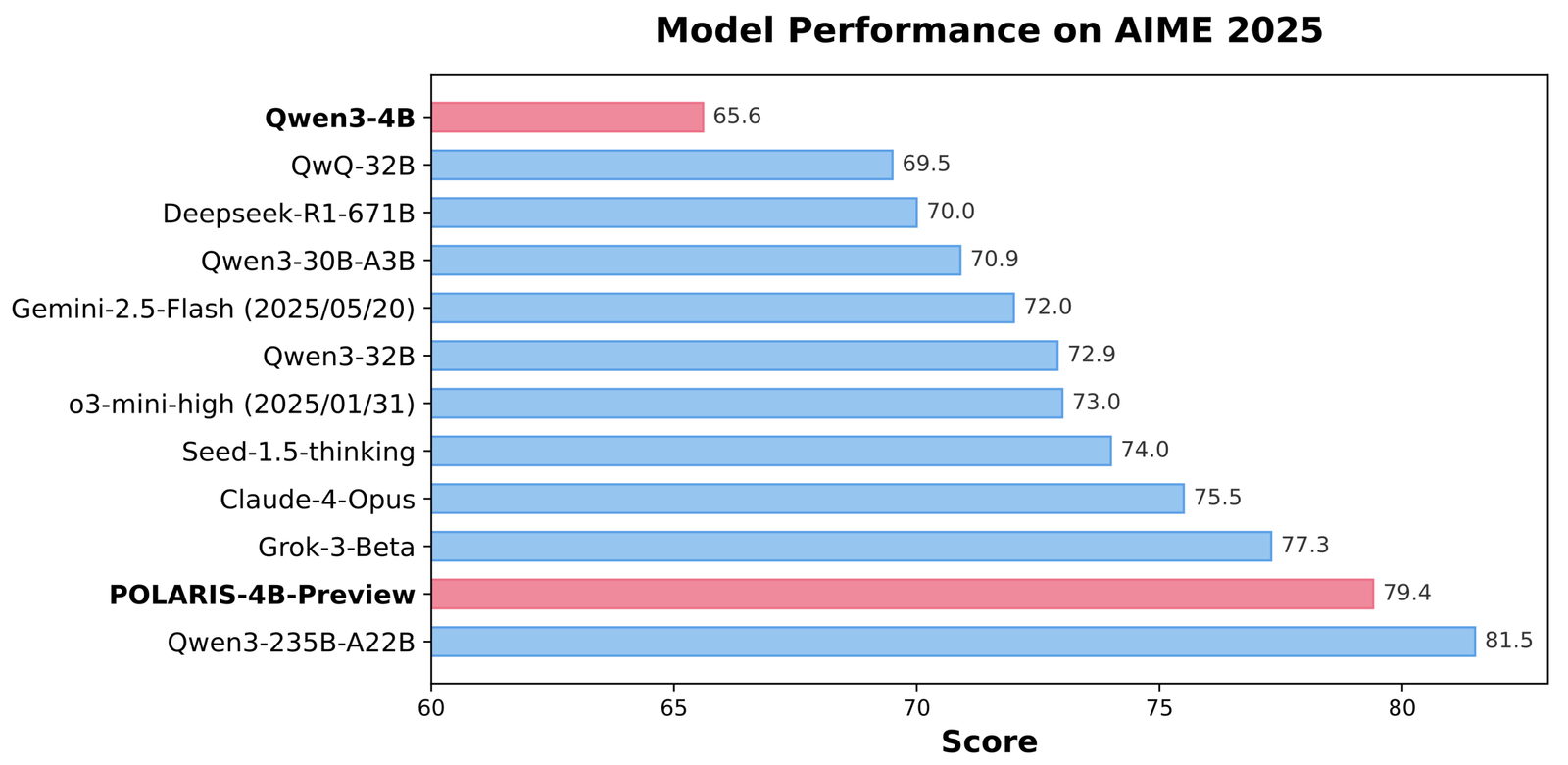
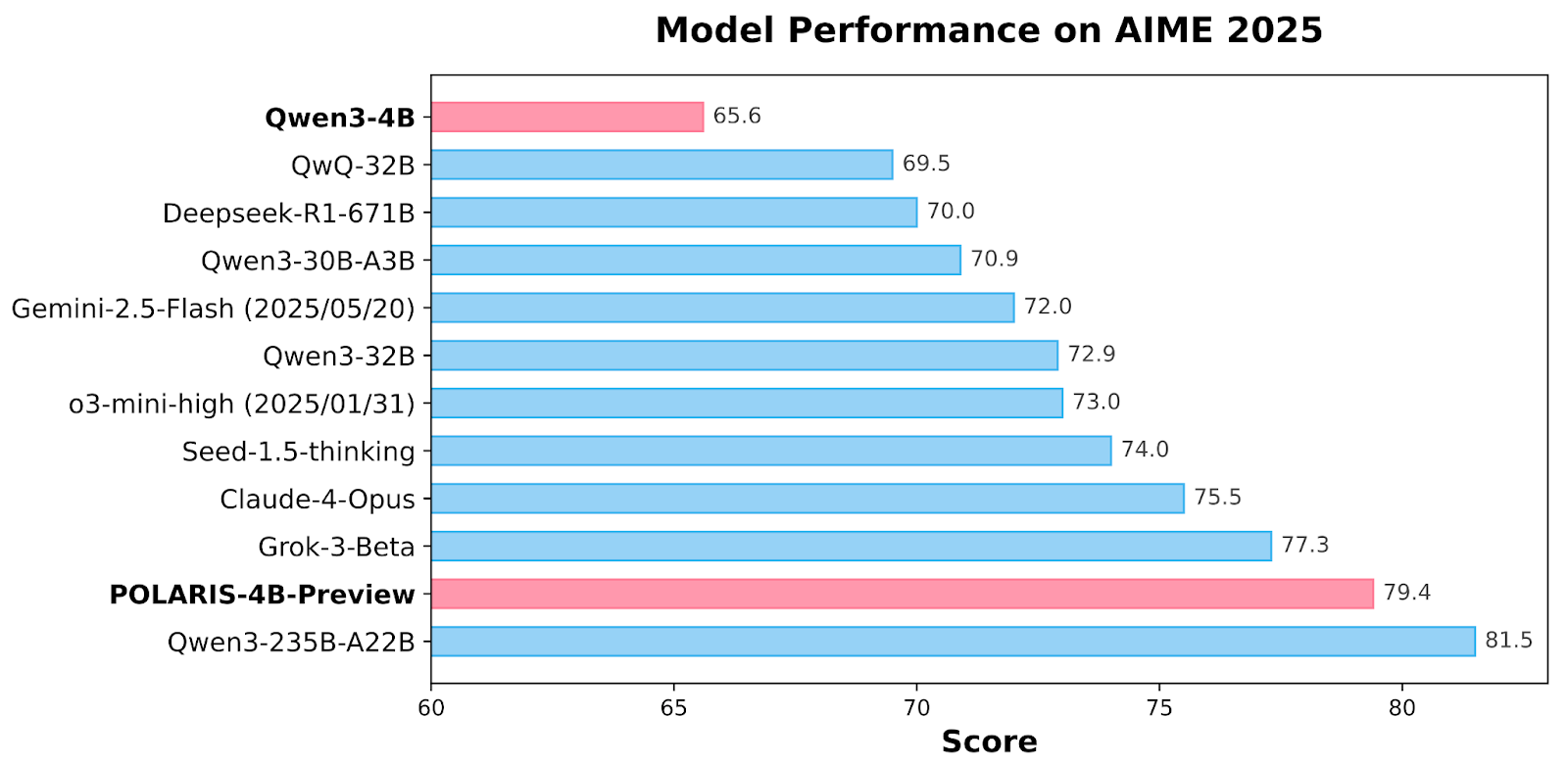
Benchmark Results: Polaris Outperforms Larger Commercial Models
Polaris models achieve state-of-the-art results across multiple math benchmarks. Polaris-4B-Preview records 81.2% accuracy on AIME24 and 79.4% on AIME25, outperforming even Qwen3-32B on the same tasks while using less than 2% of its parameters. It scores 44.0% on Minerva Math, 69.1% on Olympiad Bench, and 94.8% on AMC23. Polaris-7B-Preview also performs strongly, scoring 72.6% on AIME24 and 52.6% on AIME25. These results demonstrate consistent improvement over models such as Claude-4-Opus and Grok-3-Beta, establishing Polaris as a competitive, lightweight model that bridges the performance gap between small open models and commercial 30B+ models.
Conclusion: Efficient Reinforcement Learning Through Smart Post-Training Strategies
The researchers demonstrated that the key to scaling reasoning models is not just larger model size but intelligent control over training data difficulty, sampling diversity, and inference length. Polaris offers a reproducible recipe that effectively tunes these elements, allowing smaller models to rival the reasoning ability of massive commercial systems.
Check out the Model and Code. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.















