Why Do Sequential LLMs Hit a Bottleneck?
Test-time compute scaling in LLMs has traditionally relied on extending single reasoning paths. While this approach improves reasoning for a limited range, performance plateaus quickly. Experiments on DeepSeek-R1-distill-Qwen-1.5B show that increasing token budgets beyond 32K (up to 128K) yields negligible accuracy gains. The bottleneck arises from early token commitment, where initial errors propagate through the entire chain-of-thought. This effect, referred to as Tunnel Vision, indicates that the scaling issue is methodological rather than a fundamental limit of model capacity.
Tunnel Vision and How Is It Diagnosed?
Researchers quantified recovery ability by forcing models to continue from erroneous prefixes of varying lengths (100–1600 tokens). Accuracy declined monotonically as prefix length increased, demonstrating that once committed to a flawed trajectory, the model cannot recover—even when given additional computation budget. This confirms that sequential scaling allocates compute inefficiently.
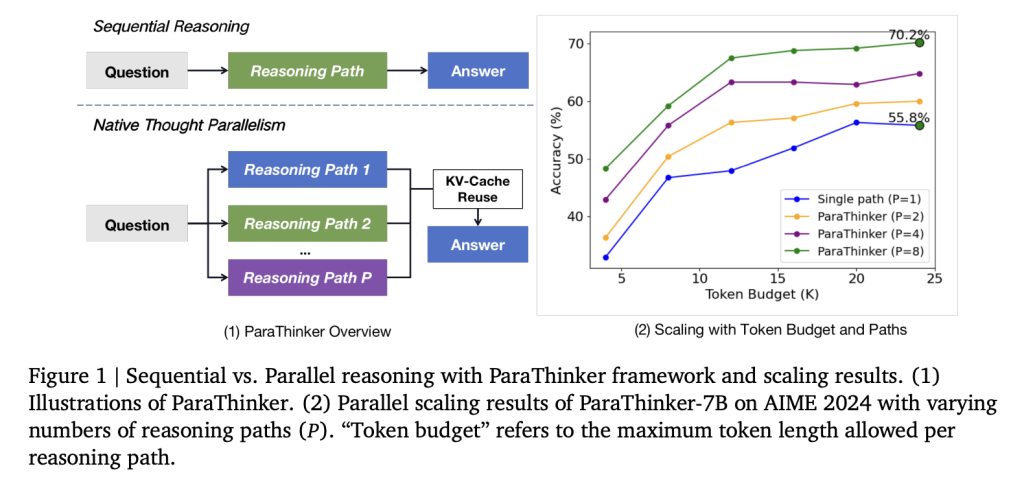
How Does ParaThinker Introduce Parallel Thinking?
A team of researchers from Tsinghua University introduce ParaThinker, an end-to-end framework that trains an LLM to generate multiple, diverse reasoning paths in parallel and synthesize them into a superior final answer. ParaThinker operationalizes native thought parallelism by generating multiple reasoning trajectories in parallel and merging them into a final response.
Key architectural components include:
- Specialized control tokens (
<think i>) to initiate distinct reasoning paths. - Thought-specific positional embeddings to disambiguate tokens across paths and prevent collapse during summarization.
- Two-phase attention masks enforcing path independence during reasoning and controlled integration during answer generation.
A critical efficiency gain comes from reusing KV-caches from the reasoning stage in the summarization phase, eliminating redundant re-prefilling.
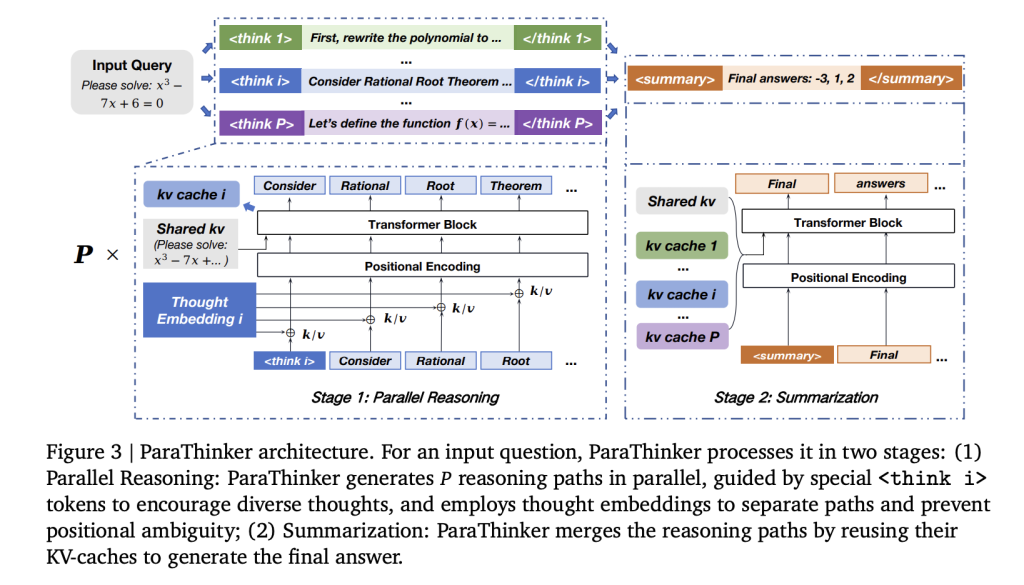
How Is ParaThinker Trained for Parallel Reasoning?
Supervised fine-tuning (SFT) was conducted using multi-path reasoning datasets. Training data was constructed by sampling multiple solution paths from teacher models (DeepSeek-R1, GPT-OSS-20B). Each example included several <think i> trajectories and a final <summary> solution. Randomized token sampling ensured generalization to more paths at inference than seen in training.
The fine-tuning used Qwen-2.5 models (1.5B and 7B parameters), with maximum context length 28K tokens. Data sources included Open-R1, DeepMath, s1k, and LIMO, supplemented with additional solutions sampled at temperature 0.8. Training was run on multiple A800 GPUs.
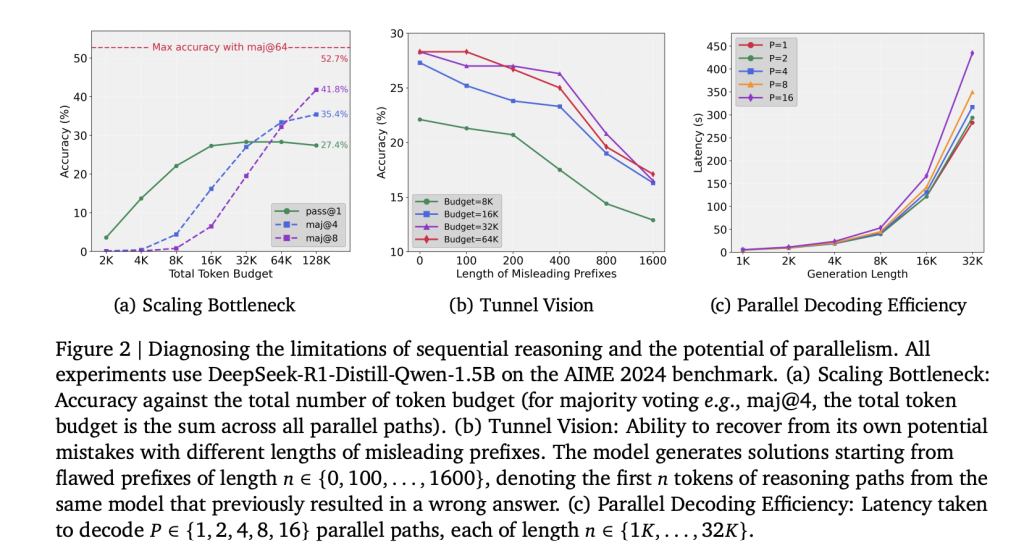
What Are the Experimental Results?
Evaluation on AIME 2024, AIME 2025, AMC 2023, and MATH-500 yields the following:
- Accuracy:
- 1.5B ParaThinker achieved +12.3% accuracy over sequential baselines and +4.3% over majority voting.
- 7B ParaThinker achieved +7.5% accuracy over sequential and +2.0% over majority voting.
- With 8 reasoning paths, ParaThinker-1.5B reached 63.2% pass@1, exceeding sequential 7B models at equivalent budgets.
- Efficiency:
- Latency overhead of parallel reasoning was 7.1% on average.
- Generating 16 paths was less than 2× the latency of generating a single path due to improved GPU memory utilization.
- Termination strategy: The First-Finish approach, where reasoning ends when the first path terminates, outperformed Last-Finish and Half-Finish strategies both in accuracy and latency.
What Do Ablation Studies Indicate?
- Dataset-only fine-tuning (without ParaThinker modifications) failed to improve performance, confirming that gains derive from architectural innovations rather than training data alone.
- Removing thought embeddings reduced accuracy, while naïve flattened encodings caused severe degradation due to long-range positional decay.
- Re-prefilling baselines degraded as the number of paths increased, validating the computational benefits of KV-cache reuse.
How Does ParaThinker Compare to Other Methods?
Conventional parallel strategies such as majority voting, self-consistency, and Tree of Thoughts require external verifiers or post-hoc selection, limiting scalability. Diffusion-based token-parallel methods perform poorly on reasoning tasks due to sequential dependency. Architectural approaches like PARSCALE demand structural changes and pretraining. In contrast, ParaThinker preserves the Transformer backbone and introduces parallelism at the reasoning stage, integrating multiple KV-caches into a unified summarization step.
Summary
ParaThinker demonstrates that test-time scaling bottlenecks are an artifact of sequential reasoning strategies. By allocating compute across width (parallel trajectories) rather than depth (longer chains), smaller models can outperform significantly larger baselines with minimal latency overhead. This establishes native thought parallelism as a critical dimension for future LLM scaling.
Check out the PAPER here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.