


Implementing Advanced Feature Scaling Techniques in Python Step-by-Step
Image by Author | ChatGPT
In this article, you will learn:
- Why standard scaling methods are sometimes insufficient and when to use advanced techniques.
- The concepts behind four advanced strategies: quantile transformation, power transformation, robust scaling, and unit vector scaling.
- How to implement each of these techniques step-by-step using Python’s scikit-learn library.
Introduction
Feature scaling is one of the most common techniques used for data preprocessing, with applications ranging from statistical modeling to analysis, machine learning, data visualization, and data storytelling. While in most projects and use cases we typically resort to a few of the most popular methods — such as normalization and standardization — there are circumstances when these basic techniques are not sufficient. For instance, when data is skewed, full of outliers, or does not follow or resemble a Gaussian distribution. In these situations, it might be necessary to resort to more advanced scaling techniques capable of transforming the data into a form that better reflects the assumptions of downstream algorithms or analysis techniques. Examples of such advanced techniques include quantile transformation, power transformation, robust scaling, and unit vector scaling.
This article aims to provide a practical overview of advanced feature scaling techniques, describing how each of these techniques works and showcasing a Python implementation for each.
Four Advanced Feature Scaling Strategies
In the following sections, we’ll introduce and show how to use the following four feature scaling techniques through Python-based examples:
- Quantile transformation
- Power transformation
- Robust scaling
- Unit vector scaling
Let’s get right to it.
1. Quantile Transformation
Quantile transformation maps the quantiles of the input data (feature-wise) into the quantiles of a desired target distribution, usually a uniform or normal distribution. Instead of making hard assumptions about the true distribution of the data, this approach focuses on the empirical distribution related to the observed data points. One of its main advantages is its robustness to outliers, which can be particularly helpful when mapping data to a uniform distribution, as it spreads out common values and compresses extreme ones.
This example shows how to apply quantile transformation to a small dataset, using a normal distribution as the output distribution:
|
from sklearn.preprocessing import QuantileTransformer import numpy as np
X = np.array([[10], [200], [30], [40], [5000]])
qt = QuantileTransformer(output_distribution=‘normal’, random_state=0) X_trans = qt.fit_transform(X)
print(“Original Data:\n”, X.ravel()) print(“Quantile Transformed (Normal):\n”, X_trans.ravel()) |
The mechanics are similar to most scikit-learn classes. We use the QuantileTransformer class that implements the transformation, specify the desired output distribution when initializing the scaler, and apply the fit_transform method to the data.
Output:
|
Original Data: [ 10 200 30 40 5000] Quantile Transformed (Normal): [–5.19933758 0.67448975 –0.67448975 0. 5.19933758] |
If we wanted to map the data quantile-wise into a uniform distribution, we would simply set output_distribution='uniform'.
2. Power Transformation
It’s no secret that many machine learning algorithms, analysis techniques, and hypothesis testing methods assume the data follows a normal distribution. Power transformation helps make non-normal data look more like a normal distribution. The specific transformation to apply depends on a parameter $λ$, whose value is determined by optimization methods like maximum likelihood estimation, which tries to find the $λ$ that yields the most normal mapping of the original data values. The base approach, called Box-Cox power transformation, is suitable only when handling positive values. An alternative approach called Yeo-Johnson power transformation is preferred when there are positive and negative values, as well as zeros.
|
from sklearn.preprocessing import PowerTransformer import numpy as np
X = np.array([[1.0], [2.0], [3.0], [4.0], [5.0]])
pt = PowerTransformer(method=‘box-cox’, standardize=True) X_trans = pt.fit_transform(X)
print(“Original Data:\n”, X.ravel()) print(“Power Transformed (Box-Cox):\n”, X_trans.ravel()) |
Output:
|
Original Data: [1. 2. 3. 4. 5.] Power Transformed (Box–Cox): [–1.50121999 –0.64662521 0.07922595 0.73236192 1.33625733] |
If you had zero or negative values in the dataset, you would use the Yeo-Johnson transformation by setting method='yeo-johnson'.
3. Robust Scaling
The robust scaler is an interesting alternative to standardization when your data contains outliers or is not normally distributed. While standardization centers your data around the mean and scales it according to the standard deviation, robust scaling uses statistics that are robust to outliers. Specifically, it centers the data by subtracting the median and then scales it by dividing by the interquartile range (IQR), following this formula:
$X_{scaled} = \frac{X – \text{Median}(X)}{\text{IQR}(X)}$
The Python implementation is straightforward:
|
from sklearn.preprocessing import RobustScaler import numpy as np
X = np.array([[10], [20], [30], [40], [1000]])
scaler = RobustScaler() X_trans = scaler.fit_transform(X)
print(“Original Data:\n”, X.ravel()) print(“Robust Scaled:\n”, X_trans.ravel()) |
Output:
|
Original Data: [ 10 20 30 40 1000] Robust Scaled: [–1. –0.5 0. 0.5 48.5] |
Robust scaling is valued for leading to a more reliable representation of the data distribution, particularly in the presence of extreme outliers like the 1000 in the example above.
4. Unit Vector Scaling
Unit vector scaling, also known as normalization, scales each sample (i.e., each row in the data matrix) to have a unit norm (a length of 1). It does so by dividing each element in the sample by the norm of that sample. There are two common norms: the L1 norm, which is the sum of the absolute values of the elements, and the L2 norm, which is the square root of the sum of squares. Using one or the other depends on whether you want to focus on data sparsity (L1) or on preserving geometric distance (L2).
This example applies unit vector scaling to two samples, turning each row into a unit vector based on the L2 norm (change the argument to 'l1' for using the L1 norm):
|
from sklearn.preprocessing import Normalizer import numpy as np
X = np.array([[1, 2, 3], [4, 5, 6]])
normalizer = Normalizer(norm=‘l2’) X_trans = normalizer.transform(X)
print(“Original Data:\n”, X) print(“L2 Normalized:\n”, X_trans) |
Output:
|
Original Data: [[1 2 3] [4 5 6]] L2 Normalized: [[0.26726124 0.53452248 0.80178373] [0.45584231 0.56980288 0.68376346]] |
Wrapping Up
In this article, four advanced feature scaling techniques have been presented, which are useful in situations involving extreme outliers, non-normally distributed data, and more. Through code examples, we showcased the use of each of these scaling techniques in Python.
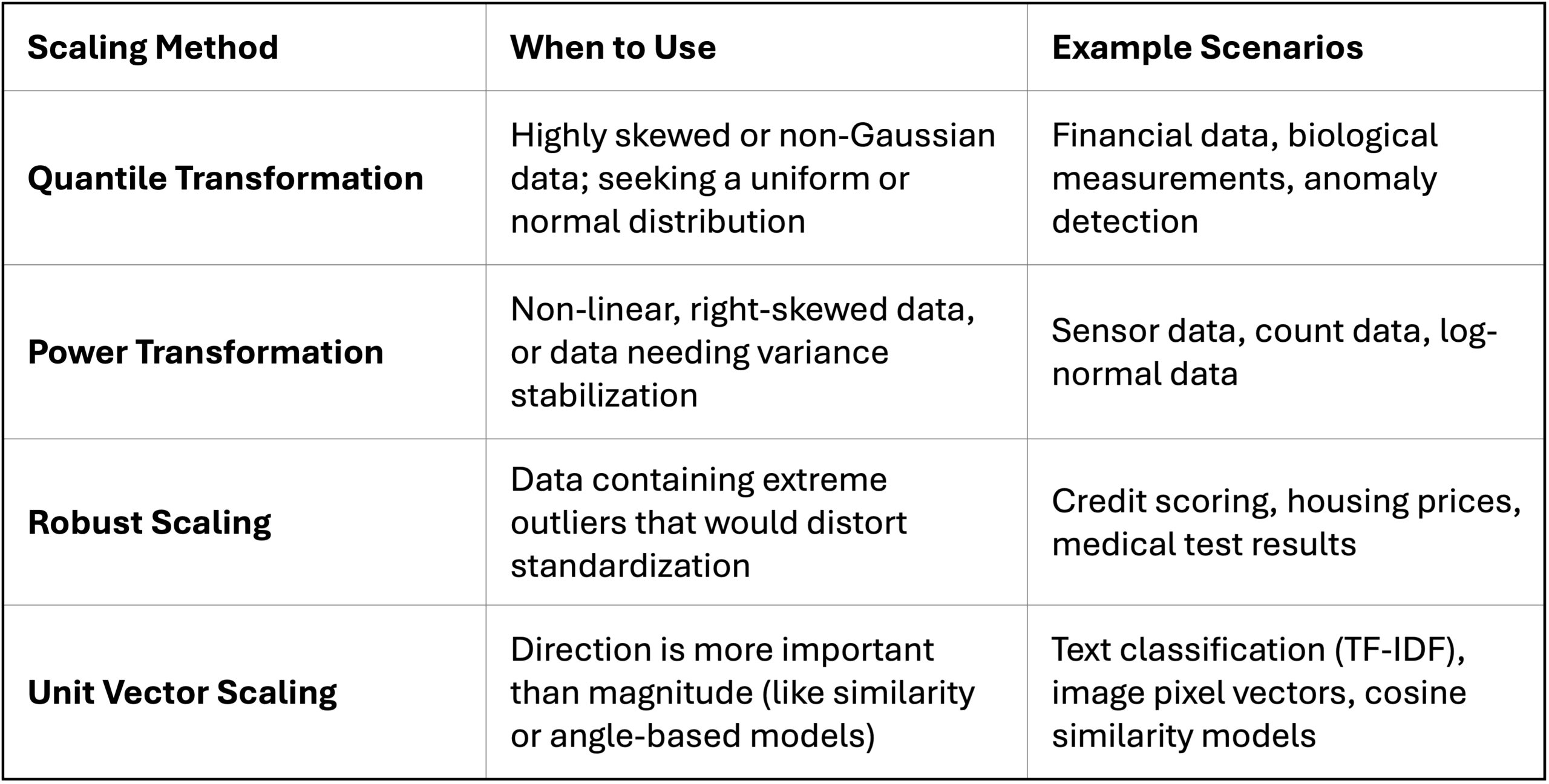
As a final summary, below is a table that highlights the data problems and example real-world scenarios where each of these feature scaling techniques might be worth considering:










![15 social media trends shaping 2025 [mid-year update]](https://mgrowtech.com/wp-content/uploads/2025/05/Social-Media-Trends-2025-350x250.png)


