
Hugging Face has just released FineVision, an open multimodal dataset designed to set a new standard for Vision-Language Models (VLMs). With 17.3 million images, 24.3 million samples, 88.9 million question-answer turns, and nearly 10 billion answer tokens, FineVision position itself as one of the largest and structured publicly available VLM training datasets.
FineVision aggregates 200+ sources into a unified format, rigorously filtered for duplicates and benchmark contamination. Rated systematically across multiple quality dimensions, the dataset enables researchers and devs to construct robust training mixtures while minimizing data leakage.
Why is FineVision Important for VLM Training?
Most state-of-the-art VLMs rely on proprietary datasets, limiting reproducibility and accessibility for the broader research community. FineVision addresses this gap by:
- Scale and Coverage: 5 TB of curated data across 9 categories, including General VQA, OCR QA, Chart & Table reasoning, Science, Captioning, Grounding & Counting, and GUI navigation.
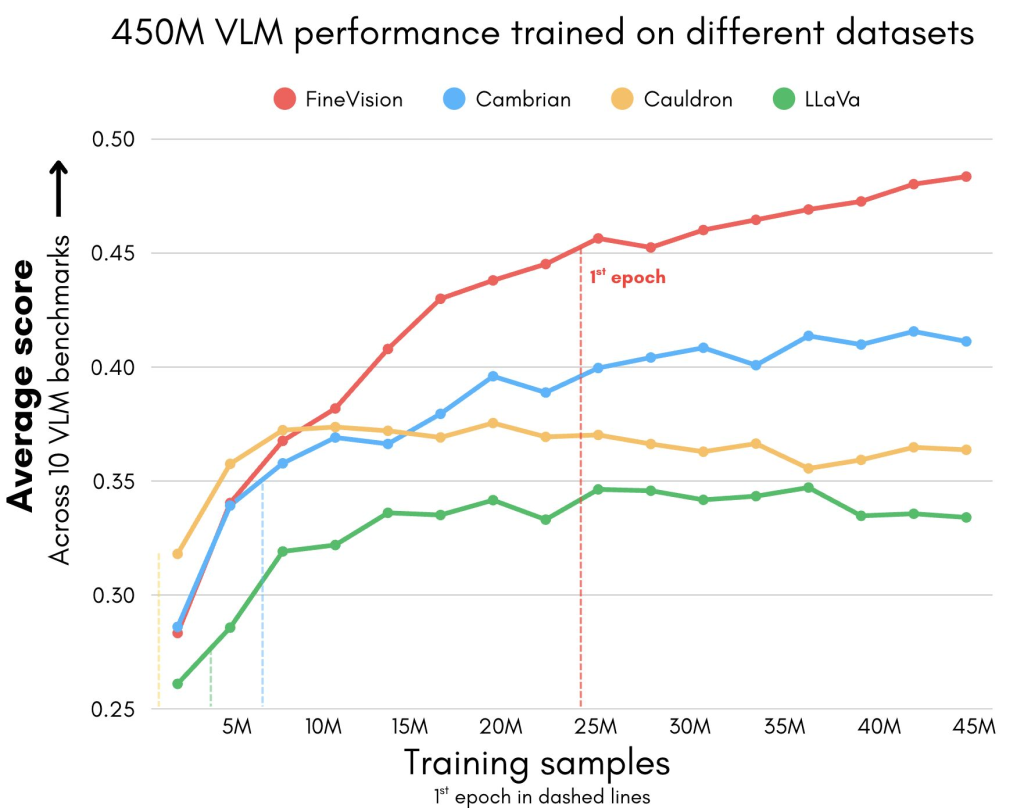
- Benchmark Gains: Across 11 widely used benchmarks (e.g., AI2D, ChartQA, DocVQA, ScienceQA, OCRBench), models trained on FineVision outperform alternatives by significant margins—up to 46.3% over LLaVA, 40.7% over Cauldron, and 12.1% over Cambrian.
- New Skill Domains: FineVision introduces data for emerging tasks like GUI navigation, pointing, and counting, expanding the capabilities of VLMs beyond conventional captioning and VQA.
How Was FineVision Built?
The curation pipeline followed a three-step process:
- Collection and Augmentation
Over 200 publicly available image-text datasets were gathered. Missing modalities (e.g., text-only data) were reformatted into QA pairs. Underrepresented domains, such as GUI data, were supplemented through targeted collection. - Cleaning
- Removed oversized QA pairs (>8192 tokens).
- Resized large images to a maximum of 2048 px while preserving aspect ratio.
- Discarded corrupted samples.
- Quality Rating
Using Qwen3-32B and Qwen2.5-VL-32B-Instruct as judges, every QA pair was rated on four axes:- Text Formatting Quality
- Question-Answer Relevance
- Visual Dependency
- Image-Question Correspondence
These ratings enable selective training mixtures, though ablations show that retaining all samples yields the best performance, even when lower-rated samples are included.
Comparative Analysis: FineVision vs. Existing Open Datasets
| Dataset | Images | Samples | Turns | Tokens | Leakage | Perf. Drop After Deduplication |
|---|---|---|---|---|---|---|
| Cauldron | 2.0M | 1.8M | 27.8M | 0.3B | 3.05% | -2.39% |
| LLaVA-Vision | 2.5M | 3.9M | 9.1M | 1.0B | 2.15% | -2.72% |
| Cambrian-7M | 5.4M | 7.0M | 12.2M | 0.8B | 2.29% | -2.78% |
| FineVision | 17.3M | 24.3M | 88.9M | 9.5B | 1.02% | -1.45% |
FineVision is not only one of the largest but also the least hallucinated dataset, with just 1% overlap with benchmark test sets. This ensures minimal data leakage and reliable evaluation performance.
Performance Insights
- Model Setup: Ablations were conducted using nanoVLM (460M parameters), combining SmolLM2-360M-Instruct as the language backbone and SigLIP2-Base-512 as the vision encoder.
- Training Efficiency: On 32 NVIDIA H100 GPUs, one full epoch (12k steps) takes ~20 hours.
- Performance Trends:
- FineVision models improve steadily with exposure to diverse data, overtaking baselines after ~12k steps.
- Deduplication experiments confirm FineVision’s low leakage compared to Cauldron, LLaVA, and Cambrian.
- Multilingual subsets, even when the backbone is monolingual, show slight performance gains, suggesting diversity outweighs strict alignment.
- Attempts at multi-stage training (two or 2.5 stages) did not yield consistent benefits, reinforcing that scale + diversity is more critical than training heuristics.
Why FineVision Brings the New Standard?
- +20% Average Performance Boost: Outperforms all existing open datasets across 10+ benchmarks.
- Unprecedented Scale: 17M+ images, 24M+ samples, 10B tokens.
- Skill Expansion: GUI navigation, counting, pointing, and document reasoning included.
- Lowest Data Leakage: 1% contamination, compared to 2–3% in other datasets.
- Fully Open Source: Available on Hugging Face Hub for immediate use via the
datasetslibrary.
Conclusion
FineVision marks a significant advancement in open multimodal datasets. Its large scale, systematic curation, and transparent quality assessments create a reproducible and extensible foundation for training state-of-the-art Vision-Language Models. By reducing dependence on proprietary resources, it enables researchers and devs to build competitive systems and accelerate progress in areas such as document analysis, visual reasoning, and agentic multimodal tasks.
Check out the Dataset and Technical details. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.













