
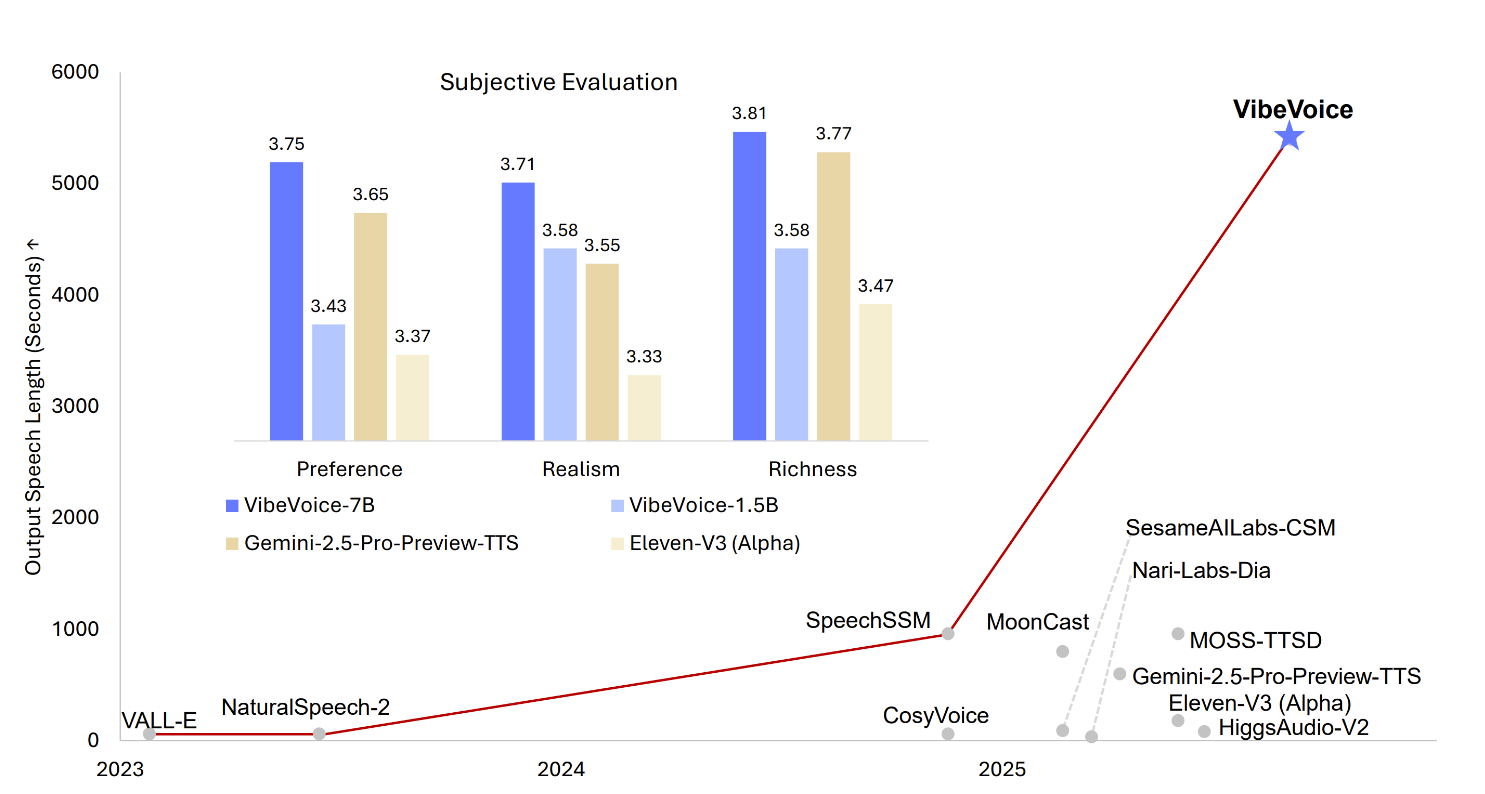
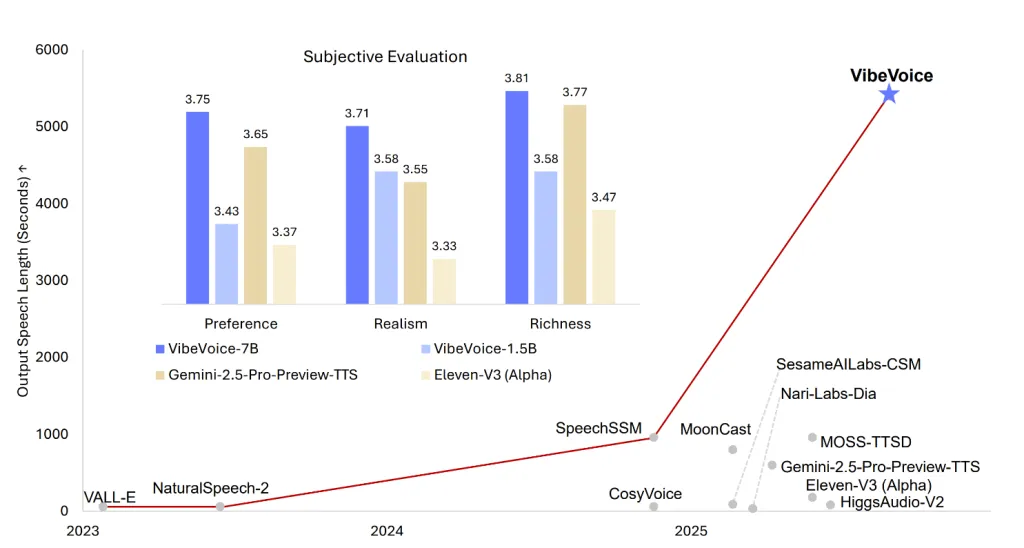
Microsoft’s latest open source release, VibeVoice-1.5B, redefines the boundaries of text-to-speech (TTS) technology—delivering expressive, long-form, multi-speaker generated audio that is MIT licensed, scalable, and highly flexible for research use. This model isn’t just another TTS engine; it’s a framework designed to generate up to 90 minutes of uninterrupted, natural-sounding audio, support simultaneous generation of up to four distinct speakers, and even handle cross-lingual and singing synthesis scenarios. With a streaming architecture and a larger 7B model announced for the near future, VibeVoice-1.5B positions itself as a major advance for AI-powered conversational audio, podcasting, and synthetic voice research.
Key Features
- Massive Context and Multi-Speaker Support: VibeVoice-1.5B can synthesize up to 90 minutes of speech with up to four distinct speakers in a single session—far surpassing the typical 1-2 speaker limit of traditional TTS models.
- Simultaneous Generation: The model isn’t just stitching together single-voice clips; it’s designed to support parallel audio streams for multiple speakers, mimicking natural conversation and turn-taking.
- Cross-Lingual and Singing Synthesis: While primarily trained on English and Chinese, the model is capable of cross-lingual synthesis and can even generate singing—features rarely demonstrated in previous open source TTS models.
- MIT License: Fully open source and commercially friendly, with a focus on research, transparency, and reproducibility.
- Scalable for Streaming and Long-Form Audio: The architecture is designed for efficient long-duration synthesis and anticipates a forthcoming 7B streaming-capable model, further expanding possibilities for real-time and high-fidelity TTS.
- Emotion and Expressiveness: The model is touted for its emotion control and natural expressiveness, making it suitable for applications like podcasts or conversational scenarios.
Architecture and Technical Deep Dive
VibeVoice’s foundation is a 1.5B-parameter LLM (Qwen2.5-1.5B) that integrates with two novel tokenizers—Acoustic and Semantic—both designed to operate at a low frame rate (7.5Hz) for computational efficiency and consistency across long sequences.
- Acoustic Tokenizer: A σ-VAE variant with a mirrored encoder-decoder structure (each ~340M parameters), achieving 3200x downsampling from raw audio at 24kHz.
- Semantic Tokenizer: Trained via an ASR proxy task, this encoder-only architecture mirrors the acoustic tokenizer’s design (minus the VAE components).
- Diffusion Decoder Head: A lightweight (~123M parameter) conditional diffusion module predicts acoustic features, leveraging Classifier-Free Guidance (CFG) and DPM-Solver for perceptual quality.
- Context Length Curriculum: Training starts at 4k tokens and scales up to 65k tokens—enabling the model to generate very long, coherent audio segments.
- Sequence Modeling: The LLM understands dialogue flow for turn-taking, while the diffusion head generates fine-grained acoustic details—separating semantics and synthesis while preserving speaker identity over long durations.
Model Limitations and Responsible Use
- English and Chinese Only: The model is trained solely on these languages; other languages may produce unintelligible or offensive outputs.
- No Overlapping Speech: While it supports turn-taking, VibeVoice-1.5B does not model overlapping speech between speakers.
- Speech-Only: The model does not generate background sounds, Foley, or music—audio output is strictly speech.
- Legal and Ethical Risks: Microsoft explicitly prohibits use for voice impersonation, disinformation, or authentication bypass. Users must comply with laws and disclose AI-generated content.
- Not for Professional Real-Time Applications: While efficient, this release is not optimized for low-latency, interactive, or live-streaming scenarios; that’s the target for the soon-to-come 7B variant.
Conclusion
Microsoft’s VibeVoice-1.5B is a breakthrough in open TTS: scalable, expressive, and multi-speaker, with a lightweight diffusion-based architecture that unlocks long-form, conversational audio synthesis for researchers and open source developers. While use is currently research-focused and limited to English/Chinese, the model’s capabilities—and the promise of upcoming versions—signal a paradigm shift in how AI can generate and interact with synthetic speech.
For technical teams, content creators, and AI enthusiasts, VibeVoice-1.5B is a must-explore tool for the next generation of synthetic voice applications—available now on Hugging Face and GitHub, with clear documentation and an open license. As the field pivots toward more expressive, interactive, and ethically transparent TTS, Microsoft’s latest offering is a landmark for open source AI speech synthesis.
FAQs
What makes VibeVoice-1.5B different from other text-to-speech models?
VibeVoice-1.5B can generate up to 90 minutes of expressive, multi-speaker audio (up to four speakers), supports cross-lingual and singing synthesis, and is fully open source under the MIT license—pushing the boundaries of long-form conversational AI audio generation
What hardware is recommended for running the model locally?
Community tests show that generating a multi-speaker dialog with the 1.5 B checkpoint consumes ≈ 7 GB of GPU VRAM, so an 8 GB consumer card (e.g., RTX 3060) is generally sufficient for inference.
Which languages and audio styles does the model support today?
VibeVoice-1.5B is trained only on English and Chinese and can perform cross-lingual narration (e.g., English prompt → Chinese speech) as well as basic singing synthesis. It produces speech only—no background sounds—and does not model overlapping speakers; turn-taking is sequential.
Check out the Technical Report, Model on Hugging Face and Codes. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.













