
The generative AI landscape is dominated by massive language models, often designed for the vast capacities of cloud data centers. These models, while powerful, make it difficult or impossible for everyday users to deploy advanced AI privately and efficiently on local devices like laptops, smartphones, or embedded systems. Instead of compressing cloud-scale models for the edge—often resulting in substantial performance compromises—the team behind SmallThinker asked a more fundamental question: What if a language model were architected from the start for local constraints?
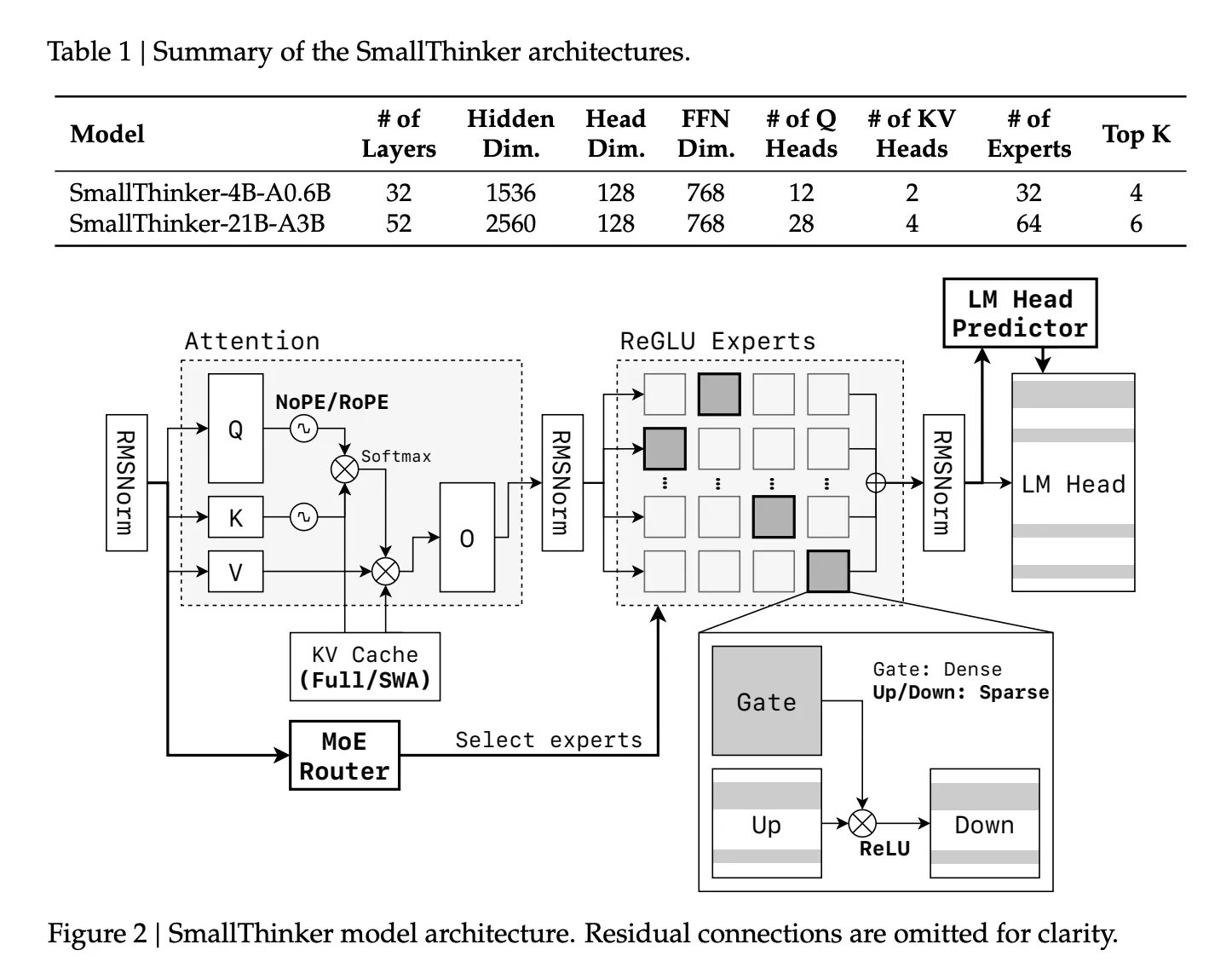
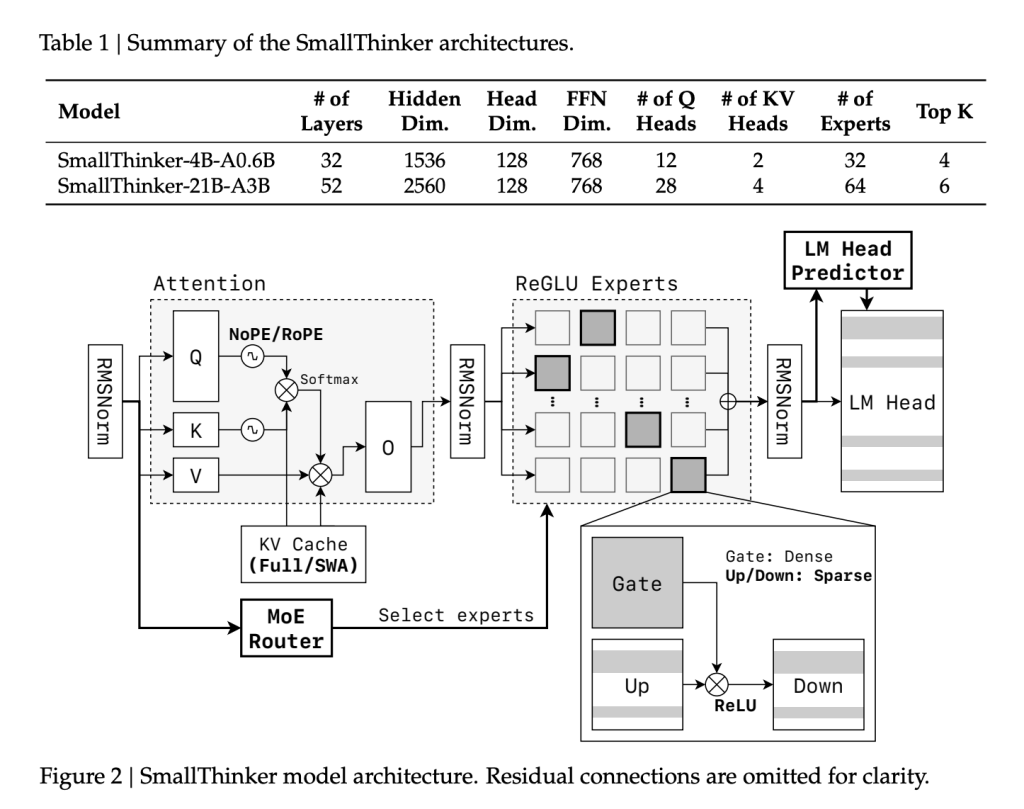
This was the genesis for SmallThinker, a family of Mixture-of-Experts (MoE) models developed by Researchers at Shanghai Jiao Tong University and Zenergize AI, that targets at high-performance, memory-limited, and compute-constrained on-device inference. With two main variants—SmallThinker-4B-A0.6B and SmallThinker-21B-A3B—they set a new benchmark for efficient, accessible AI.
Local Constraints Become Design Principles
Architectural Innovations

Fine-Grained Mixture-of-Experts (MoE):
Unlike typical monolithic LLMs, SmallThinker’s backbone features a fine-grained MoE design. Multiple specialized expert networks are trained, but only a small subset is activated for each input token:
- SmallThinker-4B-A0.6B: 4 billion parameters in total, with just 600 million in play per token.
- SmallThinker-21B-A3B: 21 billion parameters, of which only 3 billion are active at once.
This enables high capacity without the memory and computation penalties of dense models.
ReGLU-Based Feed-Forward Sparsity:
Activation sparsity is further enforced using ReGLU. Even within activated experts, over 60% of neurons are idle per inference step, realizing massive compute and memory savings.
NoPE-RoPE Hybrid Attention:
For efficient context handling, SmallThinker employs a novel attention pattern: alternating between global NoPositionalEmbedding (NoPE) layers and local RoPE sliding-window layers. This approach supports large context lengths (up to 32K tokens for 4B and 16K for 21B) but trims the Key/Value cache size compared to traditional all-global attention.
Pre-Attention Router and Intelligent Offloading:
Critical to on-device use is the decoupling of inference speed from slow storage. SmallThinker’s “pre-attention router” predicts which experts will be needed before each attention step, so their parameters are prefetched from SSD/flash in parallel with computation. The system relies on caching “hot” experts in RAM (using an LRU policy), while less-used specialists remain on fast storage. This design essentially hides I/O lag and maximizes throughput even with minimal system memory.
Training Regime and Data Procedures
SmallThinker models were trained afresh, not as distillations, on a curriculum that progresses from general knowledge to highly specialized STEM, mathematical, and coding data:
- The 4B variant processed 2.5 trillion tokens; the 21B model saw 7.2 trillion.
- Data comes from a blend of curated open-source collections, augmented synthetic math and code datasets, and supervised instruction-following corpora.
- Methodologies included quality-filtering, MGA-style data synthesis, and persona-driven prompt strategies—particularly to raise performance in formal and reasoning-heavy domains.
Benchmark Results
On Academic Tasks:
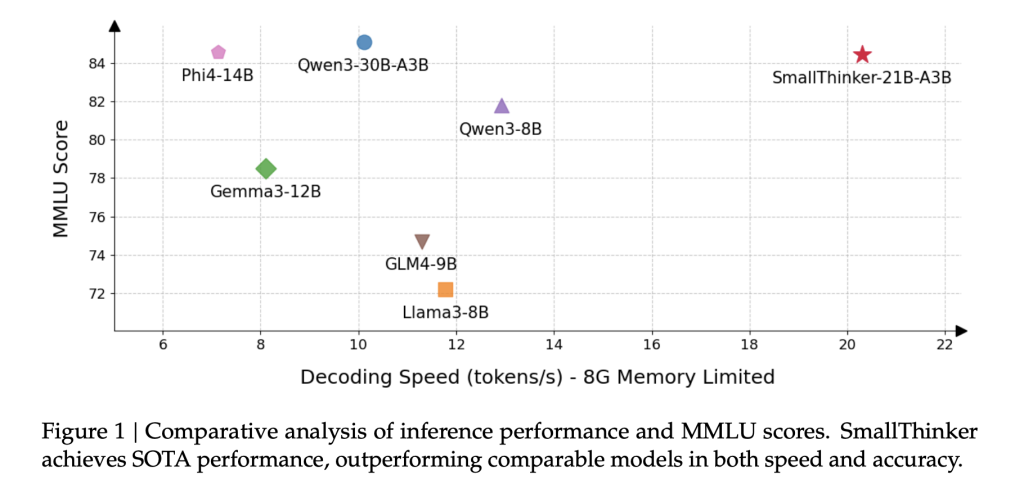
SmallThinker-21B-A3B, despite activating far fewer parameters than equivalent rivals, stands shoulder to shoulder with or beats them in fields ranging from mathematics (MATH-500, GPQA-Diamond) to code generation (HumanEval) and broad knowledge assessments (MMLU):
| Model | MMLU | GPQA | Math-500 | IFEval | LiveBench | HumanEval | Average |
|---|---|---|---|---|---|---|---|
| SmallThinker-21B-A3B | 84.4 | 55.1 | 82.4 | 85.8 | 60.3 | 89.6 | 76.3 |
| Qwen3-30B-A3B | 85.1 | 44.4 | 84.4 | 84.3 | 58.8 | 90.2 | 74.5 |
| Phi-4-14B | 84.6 | 55.5 | 80.2 | 63.2 | 42.4 | 87.2 | 68.8 |
| Gemma3-12B-it | 78.5 | 34.9 | 82.4 | 74.7 | 44.5 | 82.9 | 66.3 |
The 4B-A0.6B model also outperforms or matches other models with similar activated parameter counts, particularly excelling in reasoning and code.
On Real Hardware:
Where SmallThinker truly shines is on memory-starved devices:
- The 4B model works comfortably with as little as 1 GiB RAM, and the 21B model with just 8 GiB, without catastrophic speed drops.
- Prefetching and caching mean that even under these limits, inference remains vastly faster and smoother than baseline models simply swapped to disk.
For example, the 21B-A3B variant maintains over 20 tokens/sec on a standard CPU, while Qwen3-30B-A3B nearly crashes under similar memory constraints.
Impact of Sparsity and Specialization
Expert Specialization:
Activation logs reveal that 70–80% of experts are sparsely used, while a core few “hotspot” experts light up for specific domains or languages—a property which enables highly predictable and efficient caching.
Neuron-Level Sparsity:
Even within active experts, median neuron inactivity rates exceed 60%. Early layers are almost entirely sparse, while deeper layers retain this efficiency, illustrating why SmallThinker manages to do so much with so little compute.
System Limitations and Future Work
While the achievements are substantial, SmallThinker isn’t without caveats:
- Training Set Size: Its pretraining corpus, though massive, is still smaller than those behind some frontier cloud models—potentially limiting generalization in rare or obscure domains.
- Model Alignment: Only supervised fine-tuning is applied; unlike leading cloud LLMs, no reinforcement learning from human feedback is used, possibly leaving some safety and helpfulness gaps.
- Language Coverage: English and Chinese, with STEM, dominate training—other languages may see reduced quality.
The authors anticipate expanding the datasets and introducing RLHF pipelines in future versions.
Conclusion
SmallThinker represents a radical departure from the “shrink cloud models for edge” tradition. By starting from local-first constraints, it delivers high capability, high speed, and low memory use through architectural and systems innovation. This opens the door for private, responsive, and capable AI on nearly any device—democratizing advanced language technology for a much broader swath of users and use cases.
The models—SmallThinker-4B-A0.6B-Instruct and SmallThinker-21B-A3B-Instruct—are freely available for researchers and developers, and stand as compelling proof of what’s possible when model design is driven by deployment realities, not just data-center ambition.
Check out the Paper, SmallThinker-4B-A0.6B-Instruct and SmallThinker-21B-A3B-Instruct here. Feel free to check our Tutorials page on AI Agent and Agentic AI for various applications. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.