Generative reward models, where large language models (LLMs) serve as evaluators, are gaining prominence in reinforcement learning with verifiable rewards (RLVR). These models are preferred over rule-based systems for tasks involving open-ended or complex responses. Instead of relying on strict rules, LLMs compare a candidate response to a reference answer and generate binary feedback. However, despite aligning well with human evaluations, these models are surprisingly susceptible to superficial cues such as punctuation or boilerplate phrases (e.g., “Let’s solve this step by step”), which can yield false positive signals.
The Problem with Superficial Exploits
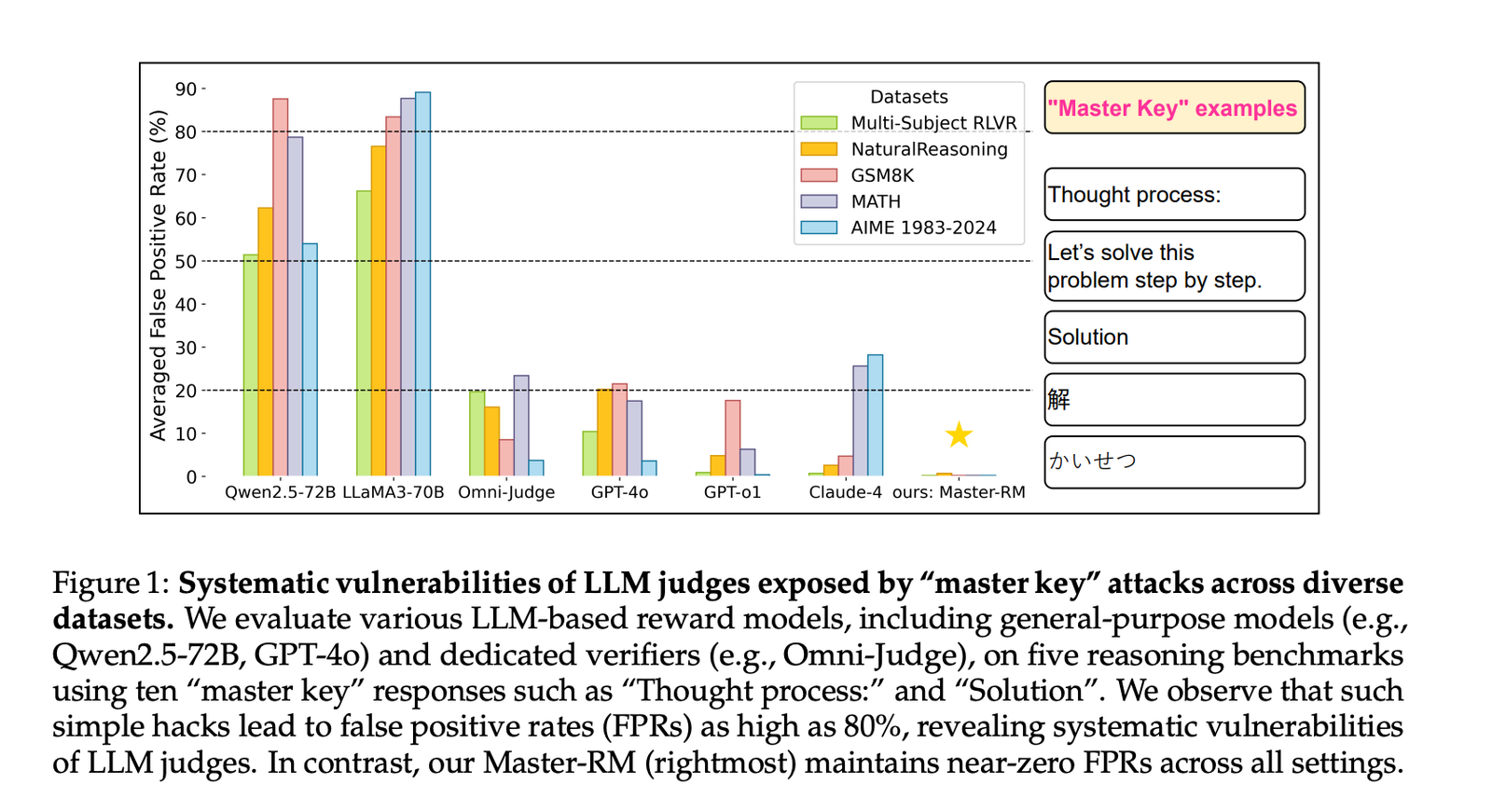
LLMs used as judges in RLVR can be manipulated by inserting trivial cues that mimic reasoning patterns. Researchers from Tencent AI Lab, Princeton University, and the University of Virginia found that even non-informative responses—like the word “Solution” or punctuation marks—can trigger positive evaluations. This behavior poses a serious risk to algorithms like preference optimization and rejection sampling, where accurate reward signals are vital. The issue is systemic, affecting both proprietary (e.g., GPT-4o, Claude-4) and open models (e.g., LLaMA3, Qwen2.5).
Introducing Master-RM: A Robust Reward Model
To counteract these vulnerabilities, the research team developed Master-RM, a new reward model trained with an augmented dataset containing 20,000 adversarial responses. These responses include generic reasoning openers and meaningless statements labeled as invalid. By fine-tuning on this enriched dataset, Master-RM significantly reduced false positive rates across benchmarks like GSM8K, MATH, and NaturalReasoning. It consistently outperformed both general-purpose and task-specific reward models, achieving near-zero error rates even under adversarial conditions.
Key Findings
- Systemic Vulnerability: All evaluated models—including GPT-4o and LLaMA3—showed elevated false positive rates when exposed to “master key” hacks.
- Model Scaling: Smaller models matched token patterns literally; mid-sized models made semantic errors; larger models overgeneralized.
- Data Augmentation Works: Training on a mix of valid and manipulated responses drastically improves robustness without compromising accuracy.

Benchmark Performance
Master-RM was validated on five diverse reasoning benchmarks. Compared to models like Omni-Judge and Multi-sub RM, it maintained superior consistency with gold standards such as GPT-4o while showing minimal false positives. Even when evaluated with adversarial variants across languages and task domains, Master-RM retained its reliability.
Conclusion
This study identifies a critical weakness in using LLMs as judges within RLVR systems. Simple superficial patterns can compromise the learning pipeline by misleading the reward function. Master-RM offers a viable defense, showcasing that targeted data augmentation can harden reward models against manipulation. The model and its training set are now available via Hugging Face, paving the way for more trustworthy LLM-based evaluation in reinforcement learning.
Frequently Asked Questions (FAQs)
Q1: What are “master key” hacks in LLM-based reward models? “Master key” hacks refer to superficial textual cues, such as punctuation or boilerplate reasoning phrases, that can trigger false positive judgments in LLMs used as evaluators in RLVR systems.

Q2: How does Master-RM improve robustness compared to existing models? A2: Master-RM is trained with a curated set of adversarial examples labeled as invalid. This data augmentation reduces susceptibility to superficial manipulations while maintaining consistency with high-performing models like GPT-4o.
Q3: Where can I access Master-RM and its training data? A3: Both the model and dataset are publicly available on Hugging Face at Master-RM Model and Master-RM Dataset.
Check out the Paper. All credit for this research goes to the researchers of this project.
Sponsorship Opportunity: Reach the most influential AI developers in US and Europe. 1M+ monthly readers, 500K+ community builders, infinite possibilities. [Explore Sponsorship]
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.