Speculative decoding is a technique for speeding up large language model inference. A small, fast draft model proposes several tokens. The large target model verifies them in parallel. If accepted, inference is faster. If rejected, the system falls back gracefully.
EAGLE Team, vLLM Team, and TorchSpec Team has launched the EAGLE series including EAGLE 1, EAGLE 2, and EAGLE 3 has become one of the most widely adopted and practically deployed families of speculative decoding algorithms across both research and production systems. Today, that family gets a targeted reliability upgrade with introduction of EAGLE 3.1.
What was Going Wrong
While speculative decoding performs well in controlled settings, performance often degrades under different chat templates, long-context inputs, or out-of-distribution system prompts.
The EAGLE team traced this fragility to a phenomenon called attention drift as speculation depth increases, the drafter gradually shifts attention away from sink tokens and toward its own generated tokens.
In simpler terms: the drafter is a small model that predicts future tokens. As speculation gets deeper, it starts attending to its own prior outputs instead of the original context. This degrades acceptance length and output stability.
Two underlying issues were identified. First, the fused input representation becomes increasingly imbalanced as higher-layer hidden states dominate the drafter input. Second, hidden-state magnitude grows across speculation steps due to the unnormalized residual path. Together, these effects make the drafter progressively less stable at deeper speculation depths.
Two Architectural Fixes in EAGLE 3.1
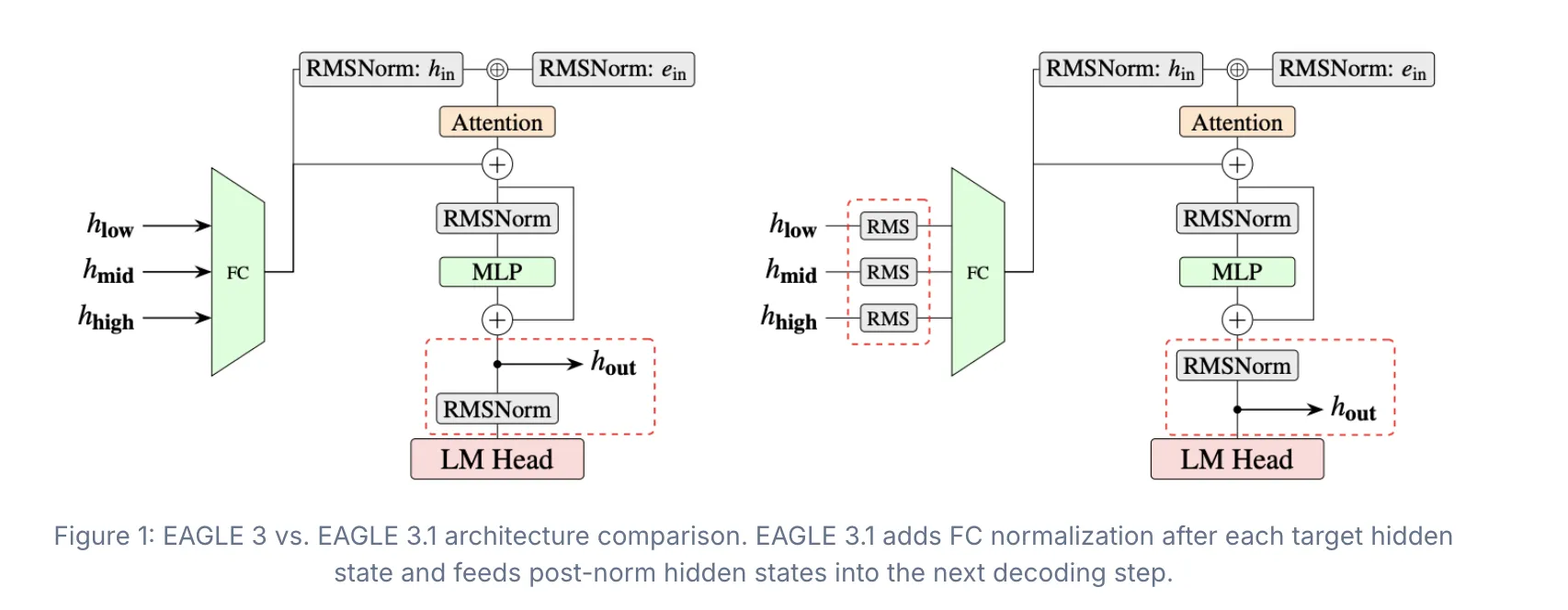
To address attention drift, EAGLE 3.1 comes with two key architectural improvements: FC normalization after each target hidden state and before the FC layer, and feeding post-norm hidden states into the next decoding step.
FC normalization stabilizes the hidden states that the drafter receives from the target model. Without it, hidden-state magnitude grows across steps, making the drafter increasingly unreliable. Applying normalization at each step keeps the inputs bounded.
The post-norm design makes the method behave more like recursively invoking the drafter across decoding steps, rather than simply appending additional layers to the target model.
What These Fixes Deliver
Compared with EAGLE 3, EAGLE 3.1 demonstrates: better training-time to inference-time extrapolation, stronger long-context robustness, higher resilience to chat template and system prompt variation, and more stable acceptance length across diverse serving environments.
In long-context workloads, EAGLE 3.1 achieves up to 2× longer acceptance length compared with EAGLE 3.
Training Infrastructure: TorchSpec
TorchSpec now provides efficient training support for EAGLE 3.1 and future speculative decoding algorithms. By lowering training overhead and simplifying experimentation workflows, TorchSpec helps accelerate iteration and exploration for next-generation speculative decoding research and deployment.
Based on TorchSpec and vLLM, the research team also trained and open-sourced an EAGLE 3.1 draft model for Kimi K2.6, available on HuggingFace. The model serves as an example of deploying EAGLE 3.1 with TorchSpec training and vLLM serving support on a real-world serving model
vLLM Integration: Config-Driven and Backward-Compatible
EAGLE 3.1 lands in vLLM as a config-driven extension of the existing EAGLE 3 implementation. The integration includes FC normalization support, post-norm hidden-state feedback, and removal of hardcoded assumptions around target hidden states.
Backward compatibility with existing EAGLE 3 checkpoints is fully preserved. EAGLE 3.1 draft models can be plugged directly through the same speculative-decoding code path.
vllm serve nvidia/Kimi-K2.6-NVFP4 \
--trust-remote-code \
--tensor-parallel-size 4 \
--tool-call-parser kimi_k2 \
--enable-auto-tool-choice \
--reasoning-parser kimi_k2 \
--attention-backend tokenspeed_mla \
--speculative-config '{"model":"lightseekorg/kimi-k2.6-eagle3.1-mla","method":"eagle3","num_speculative_tokens":3}' \
--language-model-onlyBenchmark Results on Kimi K2.6
The research team benchmarked the Kimi K2.6 EAGLE 3.1 draft model on Kimi-K2.6-NVFP4 with vLLM (TP=4, GB200, non-disagg) on the SPEED-Bench coding dataset. EAGLE 3.1 delivers 2.03× higher per-user output throughput at concurrency 1. The speedup stays meaningful as concurrency scales: 1.71× at C=4 and 1.66× at C=16.
Marktechpost’s Visual Explainer
Key Takeaways
- EAGLE 3.1 fixes attention drift — a newly identified instability where the drafter loses focus on sink tokens at deeper speculation depths.
- Two architectural changes — FC normalization and post-norm hidden-state feedback — stabilize the drafter across speculation steps.
- In long-context workloads, EAGLE 3.1 delivers up to 2× longer acceptance length compared with EAGLE 3.
- Benchmarks on Kimi-K2.6-NVFP4 show 2.03× per-user output throughput at concurrency 1, dropping to 1.66× at C=16.
- EAGLE 3.1 is backward-compatible with EAGLE 3 checkpoints and is already merged into vLLM main, shipping in v0.22.0.
Check out the Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.