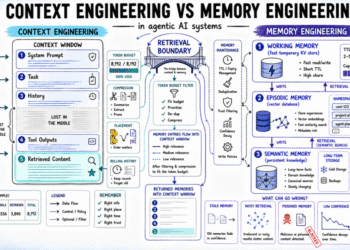
Tencent has released TencentDB Agent Memory, an open-source memory system for AI agents. The project ships under the MIT license. It targets a problem familiar to anyone shipping long-horizon agents: context bloat and recall failure.
It is symbolic short-term memory along with layered long-term memory. It integrates with OpenClaw as a plugin and with the Hermes Agent through a Gateway adapter. The default backend is local SQLite with the sqlite-vec extension, so no external API is required.
Why agent memory is hard
Most current memory stacks shred data into fragments and dump them into a flat vector store. Recall then becomes a blind similarity search across disconnected fragments, with no macro-level guidance. The architecture rests on two pillars: memory layering and symbolic memory.
A 4-tier semantic pyramid
For long-term personalization, TencentDB Agent Memory builds a four-level pyramid instead of a flat log. The layers are L0 Conversation, L1 Atom, L2 Scenario, and L3 Persona. These correspond to raw dialogue, atomic facts, scene blocks, and a user profile.
The Persona layer carries day-to-day user preferences and is queried first. The system drills down to Atoms or raw Conversations only when finer detail is needed. Lower layers preserve evidence; upper layers preserve structure.
Storage is heterogeneous. Facts, logs, and traces are persisted in databases for full-text retrieval. Personas, scenes, and canvases are stored as human-readable Markdown files. Layered memory artifacts live under ~/.openclaw/memory-tdai/.
Symbolic short-term memory via Mermaid
Long-running agent tasks consume tokens through verbose tool logs, search results, code, and error traces. TencentDB Agent Memory addresses this through context offloading combined with symbolic memory.
Full tool logs are offloaded to external files under refs/*.md. State transitions are encoded in Mermaid syntax inside a lightweight task canvas. The agent reasons over the symbol graph in its context window.
When it needs the raw text, it greps for a node_id and retrieves the corresponding file. The Tencent dev team describes this as a deterministic drill-down from top-layer symbol to mid-layer index to bottom-layer raw text.
Benchmark numbers
Results are measured over continuous long-horizon sessions, not isolated turns. SWE-bench, for example, runs 50 consecutive tasks per session to simulate context-accumulation pressure.
On WideSearch, integrating the plugin with OpenClaw raises pass rate from 33% to 50%, a 51.52% relative improvement. Token usage drops from 221.31M to 85.64M, a 61.38% reduction.
On SWE-bench, success climbs from 58.4% to 64.2% while tokens fall from 3474.1M to 2375.4M, a 33.09% reduction. On AA-LCR, the success rate moves from 44.0% to 47.5%. Tokens drop from 112.0M to 77.3M, a 30.98% reduction.
For long-term memory, PersonaMem accuracy rises from 48% to 76%. Note: these numbers come from Tencent’s own evaluations.
Recall and retrieval
Retrieval defaults to a hybrid strategy. The system combines BM25 keyword search with vector embeddings, fused using Reciprocal Rank Fusion (RRF). Developers can switch to pure keyword or embedding mode through a config field. The BM25 tokenizer supports both Chinese (jieba) and English.
Default settings trigger an L1 memory extraction every five turns. A user persona is generated every 50 new memories. Recall returns five items by default with a 5-second timeout. On timeout, the system skips injection rather than blocking the conversation.
Installation and developer surface
The OpenClaw integration ships as a single npm package: @tencentdb-agent-memory/memory-tencentdb. The project requires Node.js 22.16 or higher. Enabling it takes one config flag. The plugin then handles conversation capture, memory extraction, scene aggregation, persona generation, and recall.
For Hermes, a Docker image bundles the agent, the plugin, and the TDAI Memory Gateway. The default model is Tencent Cloud’s DeepSeek-V3.2. Any OpenAI-compatible endpoint works through the MODEL_PROVIDER=custom flag.
Two tools are exposed to agents during a session: tdai_memory_search and tdai_conversation_search. Both return references with node_id and result_ref fields for traceback. A Tencent Cloud Vector Database (TCVDB) backend is also available as an alternative to local SQLite.
Marktechpost’s Visual Explainer
Curated by MARKTECHPOST · AI Research, Engineered for Builders
Key Takeaways
- TencentDB Agent Memory is Tencent’s open-source (MIT) memory system for AI agents, built on symbolic short-term memory along with a layered long-term memory pipeline with zero external API dependencies.
- Long-term memory is structured as a 4-tier semantic pyramid (L0 Conversation → L1 Atom → L2 Scenario → L3 Persona), with drill-down via
node_idandresult_refinstead of flat vector recall. - Short-term memory offloads verbose tool logs to
refs/*.mdand keeps only a compact Mermaid task canvas in context, cutting token usage while preserving full traceability. - Reported gains when integrated with OpenClaw: WideSearch pass rate 33% → 50% with a 61.38% token reduction, SWE-bench 58.4% → 64.2%, AA-LCR 44.0% → 47.5%, and PersonaMem accuracy 48% → 76%.
- Ships as a single npm plugin for OpenClaw and a Docker image for Hermes, with local SQLite + sqlite-vec by default, hybrid BM25 + vector + RRF retrieval, and an optional Tencent Cloud Vector Database (TCVDB) backend.
Check out the Repo. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.