For years, the computer vision community has operated on two separate tracks: generative models (which produce images) and discriminative models (which understand them). The assumption was straightforward — models good at making pictures aren’t necessarily good at reading them. A new paper from Google, titled “Image Generators are Generalist Vision Learners” (arXiv:2604.20329), published April 22, 2026, blows that assumption apart.
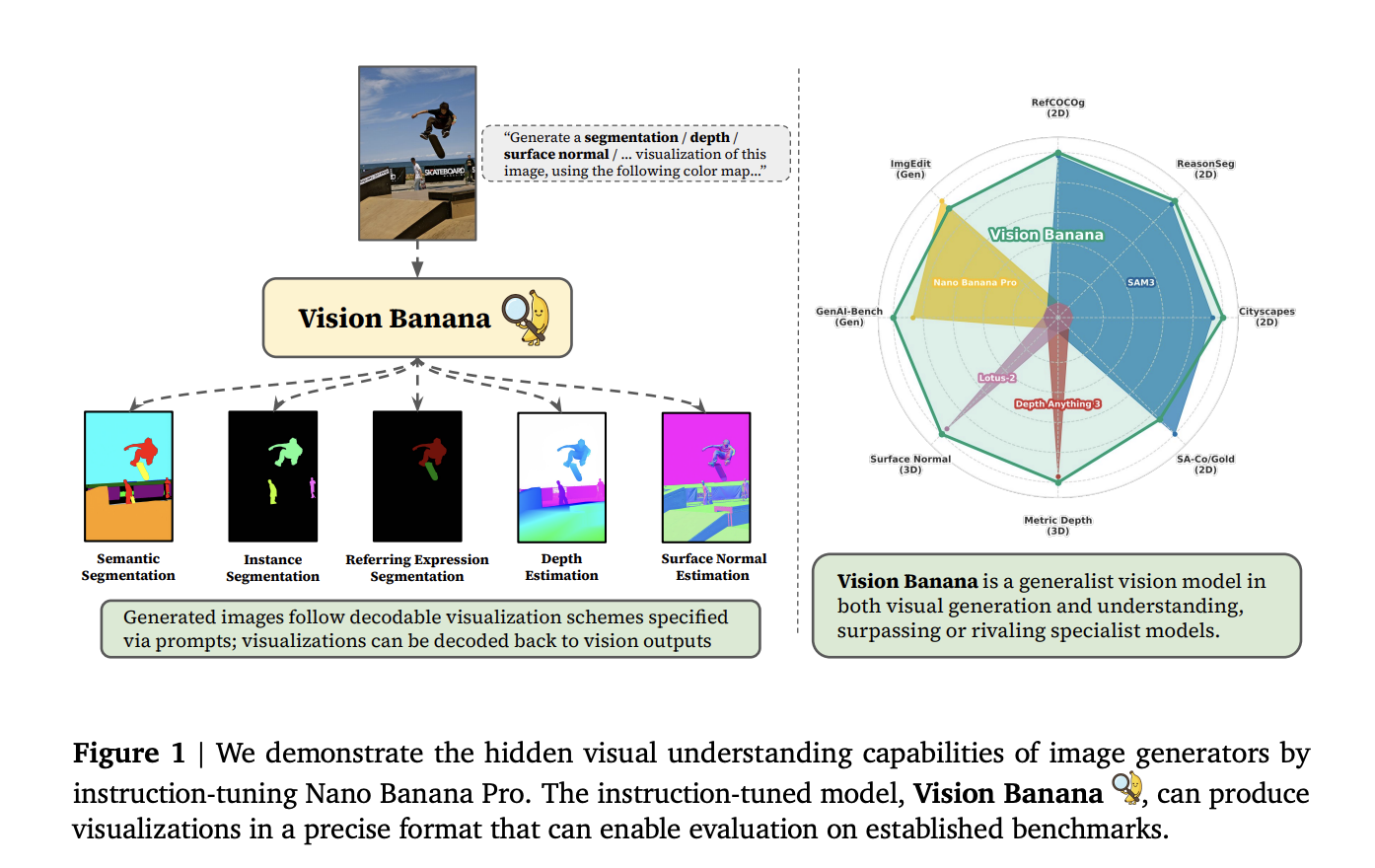
A team of Google DeepMind researchers introduced Vision Banana, a single unified model that surpasses or matches state-of-the-art specialist systems across a wide range of visual understanding tasks — including semantic segmentation, instance segmentation, monocular metric depth estimation, and surface normal estimation — while simultaneously retaining the original image generation capabilities of its base model.
The LLM Analogy That Changes Everything
If you’ve worked with large language models, you already understand the two-phase playbook: first, pretrain a base model on massive text data using a generative objective, then apply instruction-tuning to align it for downstream tasks. The pretraining phase is where the model develops a rich internal representation of language that can be repurposed for almost anything.

The Google team’s core claim is that image generation training plays the exact same foundational role for vision. Their base model, Nano Banana Pro (NBP), is Google’s state-of-the-art image generator. By performing a lightweight instruction-tuning pass — mixing a small proportion of computer vision task data at a very low ratio into NBP’s original training mixture — they created Vision Banana. The key insight: generating photorealistic images implicitly requires a model to understand geometry, semantics, depth, and object relationships. Vision Banana learns to express that latent knowledge in measurable, decodable formats.
Critically, no training data from any of the evaluation benchmarks is included in the instruction-tuning mixture — ensuring that all results reflect true generalist capability rather than in-domain memorization.
How It Works: Perception as Image Generation
Rather than adding specialized decoder heads or regression modules for each task, all vision task outputs are parameterized as RGB images. The model is instruction-tuned to produce visualizations that follow precise, invertible color schemes — meaning the generated images can be decoded back into quantitative outputs for benchmark evaluation.
The research team identified three key advantages of this strategy. First, it supports a wide variety of tasks with a single unified model — after instruction-tuning, only the prompt changes, not the weights. Second, it requires relatively little new training data, since instruction-tuning is solely teaching the model how to format computer vision outputs as RGB. Third, it helps the model retain its original image generation capabilities, since the outputs are simply new RGB images.
For semantic segmentation, the model is prompted with instructions such as: “Generate a segmentation visualization of this image, using the color mapping: {‘cat’: ‘red’, ‘background’: ‘yellow’}.” Each pixel is colored by its predicted class, and because color assignments are specified in the prompt, no fixed label vocabulary is needed.
For instance segmentation, since the number of instances is unknown in advance, Vision Banana uses a per-class inference strategy — running a separate pass per class and dynamically assigning unique colors to each instance. Masks are recovered by clustering pixels with similar colors using a threshold.
Metric depth estimation uses a bijective mapping between unbounded metric depth values in [0, ∞) and bounded RGB values in [0, 1]³. A power transform (shape parameter λ = −3, scale parameter c = 10/3) first “curves” metric depth values, which are then encoded as a false-color visualization that traverses the edges of the RGB cube, following the structure of a 3D Hilbert curve. This transform is strictly invertible, so the generated depth image decodes cleanly back to physical metric distances. Crucially, no camera parameters — neither intrinsics nor extrinsics — are required at training or inference time. The model infers absolute scale purely from visual cues and world knowledge embedded during pretraining. The depth training data is also entirely synthetic, generated from simulation rendering engines, with zero real-world depth data used.
For surface normal estimation, the mapping is more direct: surface normals are unit vectors (x, y, z) ranging from −1.0 to 1.0, which map naturally to RGB channels. Facing-left normals encode as pinkish-red; facing-up normals encode as light green; normals pointing toward the camera encode as light blue/purple.
The Numbers: Beating Specialists at Their Own Game
Vision Banana’s results across benchmarks — all in zero-shot transfer settings, where the model has never seen any training data from the evaluated datasets — are significant:
- Semantic segmentation on Cityscapes val: mIoU of 0.699, compared to SAM 3’s 0.652 — a 4.7-point gain.
- Referring expression segmentation on RefCOCOg UMD val: cIoU of 0.738, edging out SAM 3 Agent’s 0.734.
- Reasoning segmentation on ReasonSeg val: gIoU of 0.793, beating SAM 3 Agent’s 0.770 — and notably surpassing even non-zero-shot methods trained on in-domain data, including X-SAM.
- Instance segmentation on SA-Co/Gold: pmF1 of 0.540, on par with DINO-X (0.552), and ahead of Gemini 2.5 (0.461), APE-D (0.369), and OWLv2 (0.420) under zero-shot transfer.
- Metric depth estimation: average δ1 of 0.882 across six major benchmarks; on the four datasets where Depth Anything V3 was evaluated (NYU, ETH3D, DIODE-Indoor, KITTI), Vision Banana scores 0.929 versus Depth Anything V3’s 0.918 — while using zero real-world training data and no camera parameters.
- Surface normal estimation: average mean angle error of 18.928° across four datasets, compared to Lotus-2’s 19.642°. On indoor datasets specifically, Vision Banana achieves the lowest mean angle error (15.549°) and lowest median angle error (9.300°) among all compared methods.
On generative benchmarks, Vision Banana holds its own against its base model: it achieves a 53.5% win rate against Nano Banana Pro on GenAI-Bench (text-to-image), and a 47.8% win rate on ImgEdit (image editing), where Nano Banana Pro scores 52.2%. Overall, the results confirm that lightweight instruction-tuning does not degrade the model’s generative capabilities.
Key Takeaways
- Image generation pretraining is a generalist vision learner: Just as LLM pretraining unlocks emergent language understanding, Google’s research shows that training on image generation naturally develops powerful internal visual representations that transfer to perception tasks like segmentation, depth estimation, and surface normal estimation.
- Vision Banana beats specialist models without specialist architecture: Built by lightweight instruction-tuning of Nano Banana Pro, Vision Banana surpasses SAM 3 on three segmentation benchmarks, Depth Anything V3 on metric depth estimation (δ1: 0.929 vs 0.918), and Lotus-2 on surface normal estimation (mean angle error: 18.928° vs 19.642°) — all in zero-shot transfer settings.
- All vision tasks are reframed as image generation: By parameterizing vision task outputs as RGB images with decodable color schemes, Vision Banana uses a single set of weights and prompt-only switching across semantic segmentation, instance segmentation, depth estimation, and surface normal estimation — no task-specific modules required.
- Metric depth estimation works without any camera parameters or real-world data: Using a bijective power transform mapping depth values to RGB color space, Vision Banana infers absolute metric scale purely from visual context — requiring neither camera intrinsics nor extrinsics, and trained entirely on synthetic data from simulation engines.
- Image generation can serve as a universal interface for vision: Analogous to how text generation unifies language tasks, image generation may become the universal output interface for computer vision, pointing toward a paradigm shift where generative vision pretraining powers true Foundational Vision Models for both generation and understanding.
Check out the Paper and Project Page here. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.