In industrial recommendation systems, the shift toward Generative Retrieval (GR) is replacing traditional embedding-based nearest neighbor search with Large Language Models (LLMs). These models represent items as Semantic IDs (SIDs)—discrete token sequences—and treat retrieval as an autoregressive decoding task. However, industrial applications often require strict adherence to business logic, such as enforcing content freshness or inventory availability. Standard autoregressive decoding cannot natively enforce these constraints, often leading the model to “hallucinate” invalid or out-of-stock item identifiers.
The Accelerator Bottleneck: Tries vs. TPUs/GPUs
To ensure valid output, developers typically use a prefix tree (trie) to mask invalid tokens during each decoding step. While conceptually straightforward, traditional trie implementations are fundamentally inefficient on hardware accelerators like TPUs and GPUs.
The efficiency gap stems from two primary issues:
- Memory Latency: Pointer-chasing structures result in non-contiguous, random memory access patterns. This prevents memory coalescing and fails to utilize the High-Bandwidth Memory (HBM) burst capabilities of modern accelerators.
- Compilation Incompatibility: Accelerators rely on static computation graphs for machine learning compilation (e.g., Google’s XLA). Standard tries use data-dependent control flow and recursive branching, which are incompatible with this paradigm and often force costly host-device round-trips.
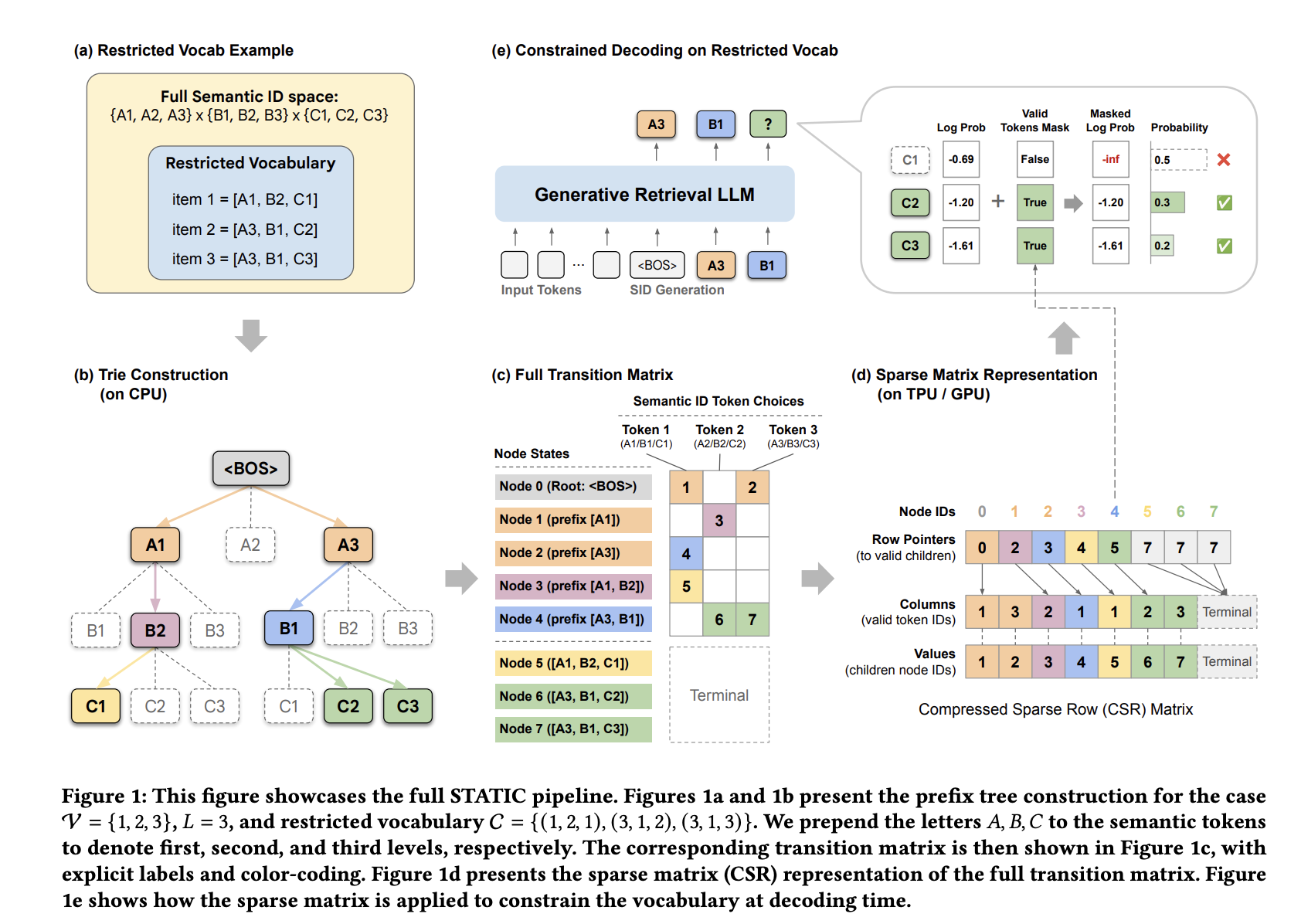
STATIC: Sparse Transition Matrix-Accelerated Trie Index
Google DeepMind and Youtube Researchers have introduced STATIC (Sparse Transition Matrix-Accelerated Trie Index for Constrained Decoding) to resolve these bottlenecks. Instead of treating the trie as a graph to be traversed, STATIC flattens it into a static Compressed Sparse Row (CSR) matrix. This transformation allows irregular tree traversals to be executed as fully vectorized sparse matrix operations.
The Hybrid Decoding Architecture
STATIC employs a two-phase lookup strategy to balance memory usage and speed:
- Dense Masking (t-1 < d): For the first d=2 layers, where the branching factor is highest, STATIC uses a bit-packed dense boolean tensor. This allows for O(1) lookups during the most computationally expensive initial steps.
- Vectorized Node Transition Kernel (VNTK): For deeper layers (l ≥ 3), STATIC utilizes a branch-free kernel. This kernel performs a ‘speculative slice’ of a fixed number of entries (Bt), corresponding to the maximum branch factor at that level. By using a fixed-size slice regardless of the actual child count, the entire decoding process remains a single, static computation graph.
This approach achieves an I/O complexity of O(1) relative to the constraint set size, whereas previous hardware-accelerated binary-search methods scaled logarithmically (O(log|C|)).
Performance and Scalability
Evaluated on Google TPU v6e accelerators using a 3-billion parameter model with a batch size of 2 and a beam size (M) of 70, STATIC demonstrated significant performance gains over existing methods.
| Method | Latency Overhead per Step (ms) | % of Total Inference Time |
| STATIC (Ours) | +0.033 | 0.25% |
| PPV Approximate | +1.56 | 11.9% |
| Hash Bitmap | +12.3 | 94.0% |
| CPU Trie | +31.3 | 239% |
| PPV Exact | +34.1 | 260% |
STATIC achieved a 948x speedup over CPU-offloaded tries and outperformed the exact binary-search baseline (PPV) by 1033x. Its latency remains nearly constant even as the Semantic ID vocabulary size (|V|) increases.
For a vocabulary of 20 million items, STATIC’s upper bound for HBM usage is approximately 1.5 GB. In practice, due to the non-uniform distribution and clustering of Semantic IDs, actual utilization is typically ≤75% of this bound. The rule of thumb for capacity planning is approximately 90 MB of HBM per 1 million constraints.
Deployment Results
STATIC was deployed on YouTube to enforce a ‘last 7 days’ freshness constraint for video recommendations. The system served a vocabulary of 20 million fresh items with 100% compliance.
Online A/B testing showed:
- A +5.1% increase in 7-day fresh video views.
- A +2.9% increase in 3-day fresh video views.
- A +0.15% increase in click-through rate (CTR).
Cold-Start Performance
The framework also addresses the ‘cold-start’ limitation of generative retrieval—recommending items not seen during training. By constraining the model to a cold-start item set on Amazon Reviews datasets, STATIC significantly improved performance over unconstrained baselines, which recorded 0.00% Recall@1. For these tests, a 1-billion parameter Gemma architecture was used with L = 4 tokens and a vocabulary size of |V|=256.
Key Takeaways
- Vectorized Efficiency: STATIC recasts constrained decoding from a graph traversal problem into hardware-friendly, vectorized sparse matrix operations by flattening prefix trees into static Compressed Sparse Row (CSR) matrices.
- Massive Speedups: The system achieves a 0.033ms per-step latency, representing a 948x speedup over CPU-offloaded tries and a 47–1033x speedup over hardware-accelerated binary-search baselines.+1
- Scalable O(1) Complexity: By achieving O(1) I/O complexity relative to constraint set size, STATIC maintains high performance with a low memory footprint of roughly 90 MB per 1 million items.
- Production-Proven Results: Deployment on YouTube showed 100% compliance with business logic constraints, driving a 5.1% increase in fresh video views and a 0.15% boost in click-through rates.
- Cold-Start Solution: The framework enables generative retrieval models to successfully recommend cold-start items, boosting Recall@1 performance from 0.00% to non-trivial levels on Amazon Reviews benchmarks.
Check out the Paper and Codes. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.