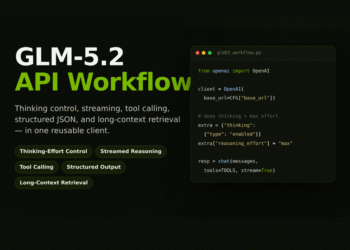
The robustness of robotic systems is dependent on the precise annotation of spatial data. Robots built on spatial intelligence are utilized in key applications, including aerial delivery systems, autonomous vehicles, search and rescue drones, surgical robots, mobile robots, and industrial robots that work alongside people.
The need for reliable data annotation is now greater than ever, enabling robots to operate outside controlled settings. For data annotation providers, this shift marks a pivotal moment. There is an unprecedented need to annotate visual data for spatial reasoning in machines. By combining automated pipelines for 3D data generation with expert human-in-the-loop annotation, it becomes feasible to produce scalable, cost-efficient, and reliable 3D training data for complex spatial tasks.
3D Data Annotation for Spatial Understanding
3D data works in full spatial coordinates. Its annotation deals with point clouds, volumetric data, and spatial relationships that mirror real-world environments. The resultant training data enables the robots to perform spatial reasoning tasks, navigating and reasoning in the physical world with human-like precision. In practice, many robots fail at even basic spatial functions if they are trained on fundamentally flawed training data.
The following are the common areas where Cogito Tech’s high-quality 3D datasets help.
Beyond 2D-centric Training Data to 3D Spatial Datasets
Most robotics models are trained on general-purpose image datasets that reduce the world to a set of pixels. At Cogito Tech, we ensure our datasets bring depth, scale, and spatial continuity, enabling models to “understand” spatial structure rather than guessing it. Our capability also lies in the ability to handle fatigue management when the human-in-the-loop method is applied for extensive datasets. Furthermore, we provide technical training to the team to mitigate error propagation that may occur from doing repetitive tasks.
Multi-modal and multi-perspective training datasets
One major area of a model’s perception failures traces back to training data errors. Apart from learning from multidimensional data provided by LiDAR, radar, and cameras, they require multi-modal data, including action information, images, and visual training, or learning new tasks based on demonstrations. We at Cogito Tech go beyond the current focus of the community on simple cases, such as push or pick-place tasks, which rely solely on visual guidance. Instead, we bring real-world complex skills to train robots, some of which may even require both visual and tactile perception to solve. We also offer human demonstration videos in datasets for training robots to acquire new skills and improve motion planning tasks.
Guidelines to Identify Reference Points for Frame Understanding
Most datasets face one fundamental challenge—they do not specify the AI’s perspective from which the spatial information should be interpreted. This ambiguity can lead to inconsistent annotations and unreliable AI models. For example, when a robot is trained to pick up carts in a logistics industry, it needs to consider whether the label “to the left of the conveyor systems” is ambiguous. Does the label “to the left of the plate” originate from the robot’s current position? Left of the camera mounted on its arm? What is the global coordinate system of the room where the robot is located? The robot needs to know: “The cart is at position (x: 0.45m, y: -0.12m, z: 0.85m) relative to the robot’s base frame.
This is where our years of expertise play a crucial role, as our annotated 3D data encodes measurable spatial facts, such as distances, orientations, and relative positions, rather than using vague terms like “left of” or “behind.”
Intelligence in robotic systems stems from data. The key to this technological progress is accurately annotating large datasets into a format that robots can use.
Challenges Unique to 3D Annotation
1. Occlusions: Partial visibility in 3D scenes
Objects in 3D data often find themselves partially or entirely blocked by other objects from the sensor’s perspective. For instance, when building robots for warehouse automation, locating a hidden box behind equipment becomes tough because 3D point clouds reveal only fragments of an object and do not clearly reveal where it begins and ends, unlike 2D images, where occlusion is visually apparent. Here, data annotators must infer the object’s presence and boundaries using spatial context, motion across frames, or camera data. In robotics navigation, poor handling of occlusions can result in models failing to detect essential objects.
2. Sparse and uneven point density in LiDAR data
They are inherently non-uniform in nature. Closer objects are represented by many points and appear solid, while more distant objects are less dense and fuzzy. The distribution of points is influenced by various factors, including the angle at which the vehicle’s lights hit the target and the color of the vehicle in question.
Different depths can be distinguished in the image by the degree of blur that different objects have. The same degree of blur will occur at the same depth, regardless of the image size. This means that at any given depth, objects of the same size will appear blurred, making it tough for annotators to decide:
- Whether sparse points belong to a real object or noise
- Where the true object boundaries lie
- How to label small or far-away objects consistently
3. Time-consuming nature of 3D annotation
Annotating a single 3D frame is inherently more complex than labeling a 2D image because annotators often spend several minutes on just one frame. Given the millions of frames to annotate, this can lead to frustration. In-house teams may also be tempted to take annotation shortcuts under pressure, which can result in a reduction in quality. In this situation, partnering with Cogito Tech could offer more benefits than using an in-house team. In cases where work is outsourced, the external team bears the responsibility for handling extensive quality assurance procedures, including verifying object dimensions, position, and depth, as well as ensuring data consistency. Cogito Tech addresses this roadblock by utilizing proprietary tools to automate annotation, which is then reviewed by human oversight to ensure the quality and quantity of datasets are adequately maintained.
Benefits of 3D Spatial Data for Robotics AI
AI robots equipped with spatial computing technology represent a significant leap, as they enable the following capabilities.
- Robots that utilize spatial computation can execute tasks with accuracy. In manufacturing facilities, robots that can assemble components with micrometer-level precision result in a decrease in errors.
- Processing real-time data from sensors and cameras on the robot enables the device to adjust its actions based on what it perceives in its environment. This is crucial in dynamic situations, such as warehouses and building sites.
- Spatial computing now enables the automation of tasks that were previously too complex for robots, such as surgeries or self-driving cars.
- In hazardous situations, computers with situational awareness can perform tasks more safely than humans.
The above advantages suggest that, for robots to interact with the world meaningfully, they must possess spatial awareness.
The Bottom Line
Robotics AI is being trained to operate in a 3-dimensional, dynamic, physical world using datasets that barely represent one. Until spatially grounded, reference-aware, and temporally consistent 3D data becomes the foundation of training pipelines, robotics systems will continue to fall short of real-world intelligence.
This is not a model problem.
It is a data problem.
To address this issue, Cogito Tech Robotics AI services offers a large-scale dataset for spatial understanding in robotics. It includes actual indoor environments and close-range depth data, collected as 3D scan images, and labeled with detailed spatial information important for robotics, based on the demands of our clients or the project’s specific needs.
Our satisfied clients are proof that models trained with our training data outperform baselines on downstream tasks such as spatial affordance prediction, spatial relationship prediction, and robot manipulation.