![Black Forest Labs Releases FLUX.2 [klein]: Compact Flow Models for Interactive Visual Intelligence](https://mgrowtech.com/wp-content/uploads/2026/01/blog-banner23-30-1024x731.png)
Black Forest Labs releases FLUX.2 [klein], a compact image model family that targets interactive visual intelligence on consumer hardware. FLUX.2 [klein] extends the FLUX.2 line with sub second generation and editing, a unified architecture for text to image and image to image, and deployment options that range from local GPUs to cloud APIs, while keeping state of the art image quality.
From FLUX.2 [dev] to interactive visual intelligence
FLUX.2 [dev] is a 32 billion parameter rectified flow transformer for text conditioned image generation and editing, including composition with multiple reference images, and runs mainly on data center class accelerators. It is tuned for maximum quality and flexibility, with long sampling schedules and high VRAM requirements.
FLUX.2 [klein] takes the same design direction and compresses it into smaller rectified flow transformers with 4 billion and 9 billion parameters. These models are distilled to very short sampling schedules, support the same text to image and multi reference editing tasks, and are optimized for response times below 1 second on modern GPUs.
Model family and capabilities
The FLUX.2 [klein] family consists of 4 main open weight variants through a single architecture.
- FLUX.2 [klein] 4B
- FLUX.2 [klein] 9B
- FLUX.2 [klein] 4B Base
- FLUX.2 [klein] 9B Base
FLUX.2 [klein] 4B and 9B are step distilled and guidance distilled models. They use 4 inference steps and are positioned as the fastest options for production and interactive workloads. FLUX.2 [klein] 9B combines a 9B flow model with an 8B Qwen3 text embedder and is described as the flagship small model on the Pareto frontier for quality versus latency across text to image, single reference editing, and multi reference generation.
The Base variants are undistilled versions with longer sampling schedules. The documentation lists them as foundation models that preserve the complete training signal and provide higher output diversity. They are intended for fine tuning, LoRA training, research pipelines, and custom post training workflows where control is more important than minimum latency.
All FLUX.2 [klein] models support three core tasks in the same architecture. They can generate images from text, they can edit a single input image, and they can perform multi reference generation and editing where several input images and a prompt jointly define the target output.
Latency, VRAM, and quantized variants
The FLUX.2 [klein] model page provides approximate end to end inference times on GB200 and RTX 5090. FLUX.2 [klein] 4B is the fastest variant and is listed at about 0.3 to 1.2 seconds per image, depending on hardware. FLUX.2 [klein] 9B targets about 0.5 to 2 seconds at higher quality. The Base models require several seconds because they run with 50 step sampling schedules, but they expose more flexibility for custom pipelines.
The FLUX.2 [klein] 4B model card states that 4B fits in about 13 GB of VRAM and is suitable for GPUs like the RTX 3090 and RTX 4070. The FLUX.2 [klein] 9B card reports a requirement of about 29 GB of VRAM and targets hardware such as the RTX 4090. This means a single high end consumer card can host the distilled variants with full resolution sampling.
To extend the reach to more devices, Black Forest Labs also releases FP8 and NVFP4 versions for all FLUX.2 [klein] variants, developed together with NVIDIA. FP8 quantization is described as up to 1.6 times faster with up to 40 percent lower VRAM usage, and NVFP4 as up to 2.7 times faster with up to 55 percent lower VRAM usage on RTX GPUs, while keeping the core capabilities the same.
Benchmarks against other image models
Black Forest Labs evaluates FLUX.2 [klein] through Elo style comparisons on text to image, single reference editing, and multi reference tasks. The performance charts show FLUX.2 [klein] on the Pareto frontier of Elo score versus latency and Elo score versus VRAM.The commentary states that FLUX.2 [klein] matches or exceeds the quality of Qwen based image models at a fraction of the latency and VRAM, and that it outperforms Z Image while supporting unified text to image and multi reference editing in one architecture.
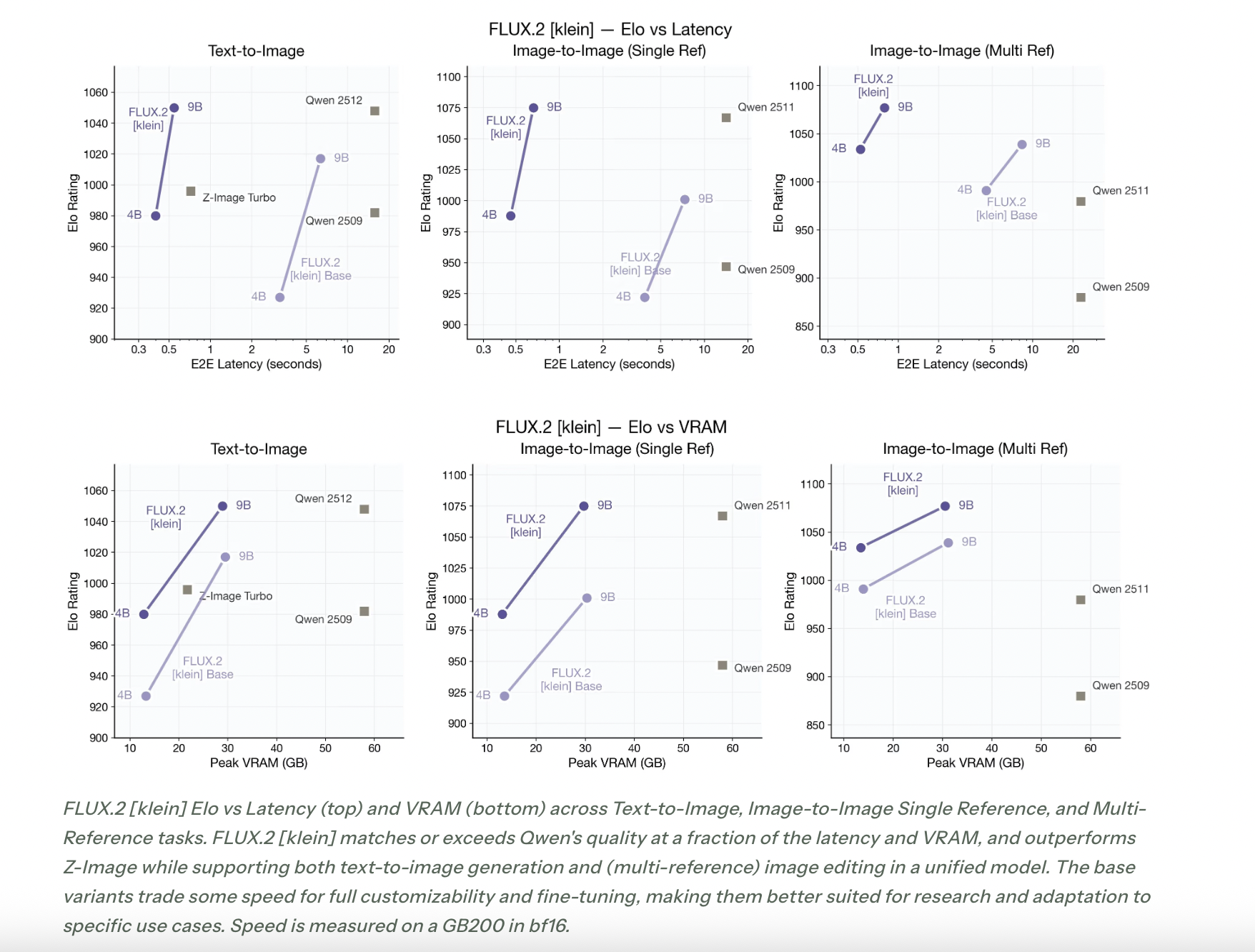
The base variants trade some speed for full customizability and fine tuning, which aligns with their role as foundation checkpoints for new research and domain specific pipelines.
Key Takeaways
- FLUX.2 [klein] is a compact rectified flow transformer family with 4B and 9B variants that supports text to image, single image editing, and multi reference generation in one unified architecture.
- The distilled FLUX.2 [klein] 4B and 9B models use 4 sampling steps and are optimized for sub second inference on a single modern GPU, while the undistilled Base models use longer schedules and are intended for fine tuning and research.
- Quantized FP8 and NVFP4 variants, built with NVIDIA, provide up to 1.6 times speedup with about 40 percent VRAM reduction for FP8 and up to 2.7 times speedup with about 55 percent VRAM reduction for NVFP4 on RTX GPUs.
Check out the Technical details, Repo and Model weights. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.