

AI clusters have entirely transformed the way traffic flows within data centers. Most of the time, traffic now moves east–west between GPUs during model training and checkpointing, rather than north–south between applications and the internet. This indicates a shift in where bottlenecks occur. CPUs, which were once responsible for encapsulation, flow control, and security, are now on the critical path. This adds latency and variability that makes it harder to use GPUs.
Due to this performance limit, the DPU/SmartNIC has evolved from being an optional accelerator to becoming necessary infrastructure. “Data center is the new unit of computing,” NVIDIA CEO Jensen Huang said during the GTC 2021. “There’s no way you’re going to do that on the CPU. So you have to move the networking stack off. You want to move the security stack off, and you want to move the data processing and data movement stack off.” Jensen Huang, interview with The Next Platform. NVIDIA claims its Spectrum-X Ethernet fabric (encompassing congestion control, adaptive routing, and telemetry) can deliver up to 48% higher storage read bandwidth for AI workloads.
The network interface is now a layer that processes things. The question of maturity is no longer whether offloading is necessary, but which offloads currently provide a measurable operational ROI.
Where AI Fabric Traffic and Reliability Become Significant
AI workloads operate synchronously: when one node experiences congestion, all GPUs in the cluster wait. Meta reports that routing-induced flow collisions and uneven traffic distribution in early RoCE deployments “degraded the training performance up to more than 30%,” prompting changes in routing and collective tuning. These issues are not purely architectural; they emerge directly from how east–west flows behave at scale.
InfiniBand has long provided credit-based link-level flow control (per-VL) to guarantee lossless delivery and prevent buffer overruns, i.e., a hardware mechanism built into the link layer. Ethernet is evolving along similar lines through the Ultra Ethernet Consortium (UEC): its Ultra Ethernet Transport (UET) work introduces endpoint/host-aware transport, congestion management guided by real-time feedback, and coordination between endpoints and switches, explicitly moving more congestion handling and telemetry into the NIC/endpoint.
InfiniBand remains the benchmark for deterministic fabric behavior. Ethernet-based AI fabrics are rapidly evolving through innovations in UET and SmartNIC.
Network professionals must evaluate silicon capabilities, not just link speeds. Reliability is now determined by telemetry, congestion control, and offload support at the NIC/DPU level.
Also Read: Smarter DevOps with Kite: AI Meets Kubernetes
Offload Pattern: Encapsulation and Stateless Pipeline Processing
AI clusters at cloud and enterprise scale rely on overlays such as VXLAN and GENEVE to segment traffic across tenants and domains. Traditionally, these encapsulation tasks run on the CPU.
DPUs and SmartNICs offload encapsulation, hashing, and flow matching directly into hardware pipelines, reducing jitter and freeing CPU cycles. NVIDIA documents VXLAN hardware offloads on its NICs/DPUs and claims Spectrum-X delivers material AI-fabric gains, including up to 48% higher storage read bandwidth in partner tests and more than 4x lower latency versus traditional Ethernet in Supermicro benchmarking.
Offload for VXLAN and stateless flow processing is supported across NVIDIA BlueField, AMD Pensando Elba, and Marvell OCTEON 10 platforms.
From a competitive perspective:
- NVIDIA focuses on integrating tightly with Datacenter Infrastructure-on-a-Chip (DOCA) for GPU-accelerated AI workloads.
- AMD Pensando offers P4 programmability and integration with Cisco Smart Switches.
- Intel IPU brings Arm-heavy designs for transport programmability.
Encapsulation offload is no longer a performance enhancer; it is foundational for predictable AI fabric behavior.
Offload Pattern: Inline Encryption and East–West Security
As AI models cross sovereign boundaries and multi-tenant clusters become common, encryption of east–west traffic has become mandatory. However, encrypting this traffic in the host CPU introduces measurable performance penalties. In a joint VMware–6WIND–NVIDIA validation, BlueField-2 DPUs offloaded IPsec for a 25 Gbps testbed (2×25 GbE BlueField-2), demonstrating higher throughput and lower host-CPU use for the 6WIND vSecGW on vSphere 8.

Figure: Thanks to NVIDIA
Marvell positions its OCTEON 10 DPUs for inline security offload in AI data centers, citing integrated crypto accelerators capable of 400+ Gbps IPsec/TLS (Marvell OCTEON 10 DPU Family media deck); the company also highlights growing AI-infrastructure demand in its investor communications. Encryption offload is shifting from optional to required as AI becomes regulated infrastructure.
Offload Pattern: Microsegmentation and Distributed Firewalling
GPU servers are often deployed in high-trust zones, but there are still risks of lateral movement, especially in environments with many tenants or when inference is done on shared infrastructure. Traditional firewalls are configured outside the GPUs and force east–west traffic through centralized choke points. This bottleneck contributes to increased latency and creates blind spots in operations.
DPUs and SmartNICs now let you set up L4 firewalls directly on the NIC, enforcing policy at the source. Cisco introduced the N9300 Series “Smart Switches,” which have programmable DPUs that add stateful services directly to the data center fabric to speed up operations. NVIDIA’s BlueField DPU similarly supports microsegmentation, allowing operators to apply Zero Trust principles to GPU workloads without involving the host CPU.
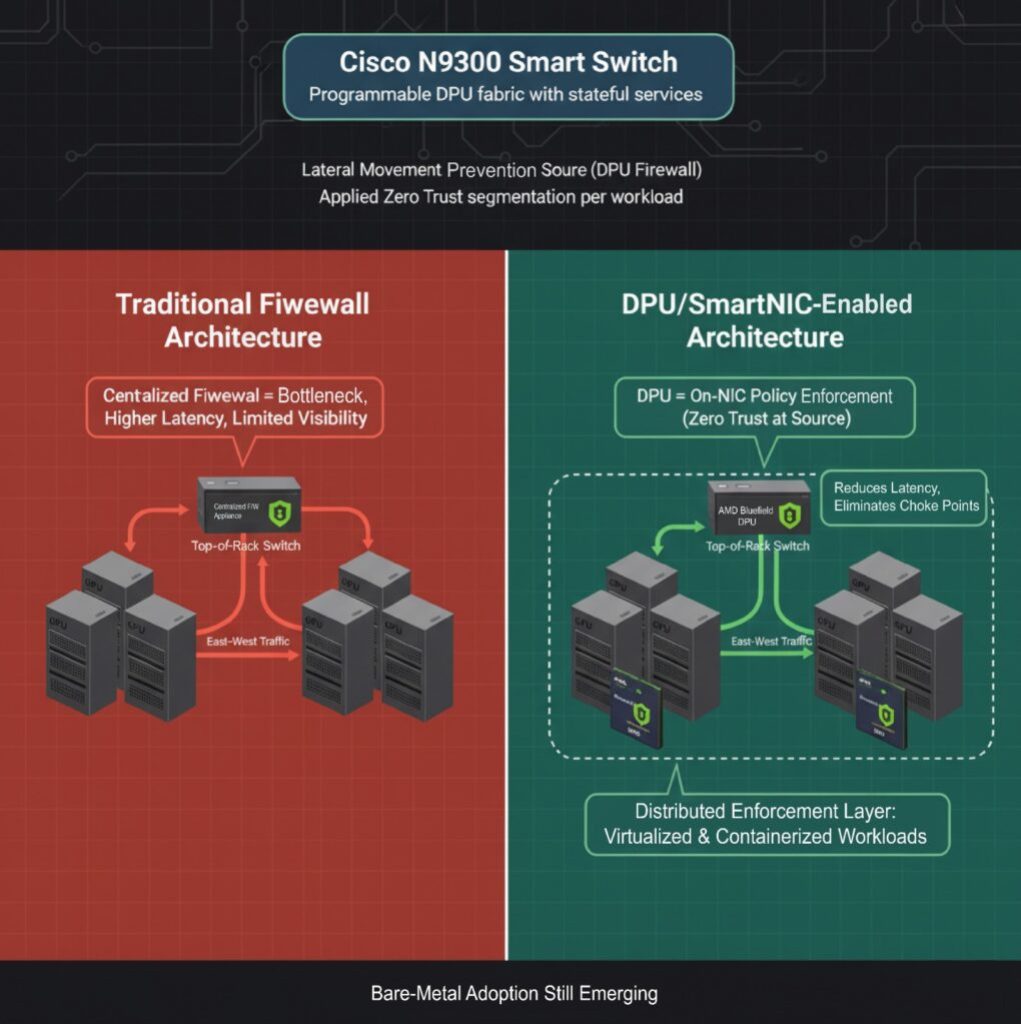
While firewall offload is production-ready for virtualized and containerized environments, its application in bare-metal AI fabric deployments is still developing.
Network engineers gain a new enforcement point inside the server itself. This offload pattern is gaining traction in regulated and sovereign AI deployments where east–west isolation is required.
Also Read: Agentic AI vs AI Agents: Key Differences & Impact on the Future of AI
Case Snapshot: Ethernet AI Fabric Operations in Production
To overcome fabric instability, Meta co-designed the transport layer and collective library, implementing Enhanced ECMP traffic engineering, queue-pair scaling, and a receiver-driven admission model. These changes yielded up to 40% improvement in AllReduce completion latency, demonstrating that fabric performance is now determined as much by transport logic in the NIC as by switch architecture.
In another example, a joint VMware–6WIND–NVIDIA validation, BlueField-2 DPUs offloaded IPsec for a 6WIND vSecGW on vSphere 8. The lab setup (limited by BlueField-2’s dual-25 GbE ports) targeted and demonstrated at least 25 Gbps aggregated IPsec throughput and showed that offloading increased throughput and improved application response, while freeing host-CPU cores.
Real deployments validate performance gains. However, independent benchmarks comparing vendors remain limited. Network architects should evaluate vendor claims through the lens of published deployment evidence, rather than relying on marketing figures.
Buyer’s Landscape: Silicon and SDK Maturity
The competitive landscape is being transformed by DPU and SmartNIC strategies. The following table highlights key considerations and differences among various vendors.
| Vendor | Differentiator | Maturity | Key Considerations |
| NVIDIA | Tight integration with GPUs, DOCA SDK, and advanced telemetry | High | Highest performance; ecosystem lock-in is a concern |
| AMD Pensando | P4-based pipeline, Cisco integration | High | Strong in enterprise and hybrid deployments |
| Intel IPU | Programmable transport, crypto acceleration | Emerging | Expected 2025 rollout; backed by Google deployment history |
| Marvell OCTEON | Power-efficient, storage-centric offload | Medium | Strength in edge and disaggregated storage AI |
Buyers are prioritizing more than raw speeds and feeds. Omdia emphasizes that effective operations now hinge on AI-driven automation and actionable telemetry, not just higher link rates.
Procurement decisions must be aligned not only with performance targets but with SDK roadmap maturity and long-term platform lock-in risks.
Competitive and Architectural Choices: What Operators Must Decide
As AI fabrics move from early deployment to scaled production, infrastructure leaders are faced with several strategic decisions that will shape cost, performance, and operational risk for years to come.
DPU vs. SuperNIC vs. High-End NIC
DPUs deliver you Arm cores, crypto blocks, and storage/network offload capabilities. They work best in AI environments that have multiple tenants, are regulated, or are sensitive to security. SuperNICs, like NVIDIA’s Spectrum-X adapters, are designed to work with switches with very low latency and deep telemetry integration, but they lack general-purpose processors.
High-end NICs (without offload capabilities) may still serve single-tenant or small-scale AI clusters, but lack long-term viability for multi-pod AI fabrics.
Ethernet vs. InfiniBand for AI Fabrics
InfiniBand is still the best at native congestion control and predictable latency. However, Ethernet is quickly becoming more popular as vendors standardize Ultra Ethernet Transport and add SmartNIC/DPU offload. InfiniBand is the best choice for hyperscale deployments where you accept vendor lock-in.
“When we first initiated our coverage of AI Back-end Networks in late 2023, the market was dominated by InfiniBand, holding over 80 percent share… As the industry moves to 800 Gbps and beyond, we believe Ethernet is now firmly positioned to overtake InfiniBand in these high-performance deployments.” Sameh Boujelbene, Vice President, Dell’Oro Group.
SDK and Ecosystem Control
Vendor control over software ecosystems is becoming a key differentiator. NVIDIA DOCA, AMD’s P4-based framework, and Intel’s IPU SDK each represent divergent development paths. Choosing a vendor today effectively means choosing a programming model and long-term integration strategy.
Also Read: How AI Chatbots Can Help Streamline Your Business Operations?
When it Pencils Out and What to Watch Next
DPUs and SmartNICs are no longer positioned as future enablers. They are becoming a required infrastructure for AI-scale networking. The business case is most transparent in clusters where:
- East–west traffic dominates
- GPU utilization is affected by microburst congestion
- Regulatory or multi-tenant requirements mandate encryption or isolation
- Storage traffic interferes with compute performance
Early adopters report measurable ROI. NVIDIA disclosed improved GPU utilization and a 48% increase in sustained storage throughput in Spectrum-X deployments that combine telemetry and congestion offload. Meanwhile, Marvell and AMD report rising attach rates for DPUs in AI design wins where operators require data path autonomy from the host CPU.
Over the next 12 months, network professionals should closely monitor:
- NVIDIA’s roadmap for BlueField-4 and SuperNIC enhancements
- AMD Pensando’s Salina DPUs integrated into Cisco Smart Switches
- UEC 1.0 specification and vendor adoption timelines
- Intel’s first production deployments of the E2200 IPU
- Independent benchmarks comparing Ethernet Ultra Fabric vs. InfiniBand performance under AI collective loads
The economics of AI networking now hinge on where processing happens. The strategic shift is underway from CPU-centric architectures to fabrics where DPUs and SmartNICs define performance, reliability, and security at scale.















